目录
随着人工智能技术的普及,如何在资源有限的设备上高效运行大型模型成为关键挑战。本文深入解析不同精度量化技术,帮助你理解AI领域这一重要优化方向。
模型量化:AI轻量化的关键技术
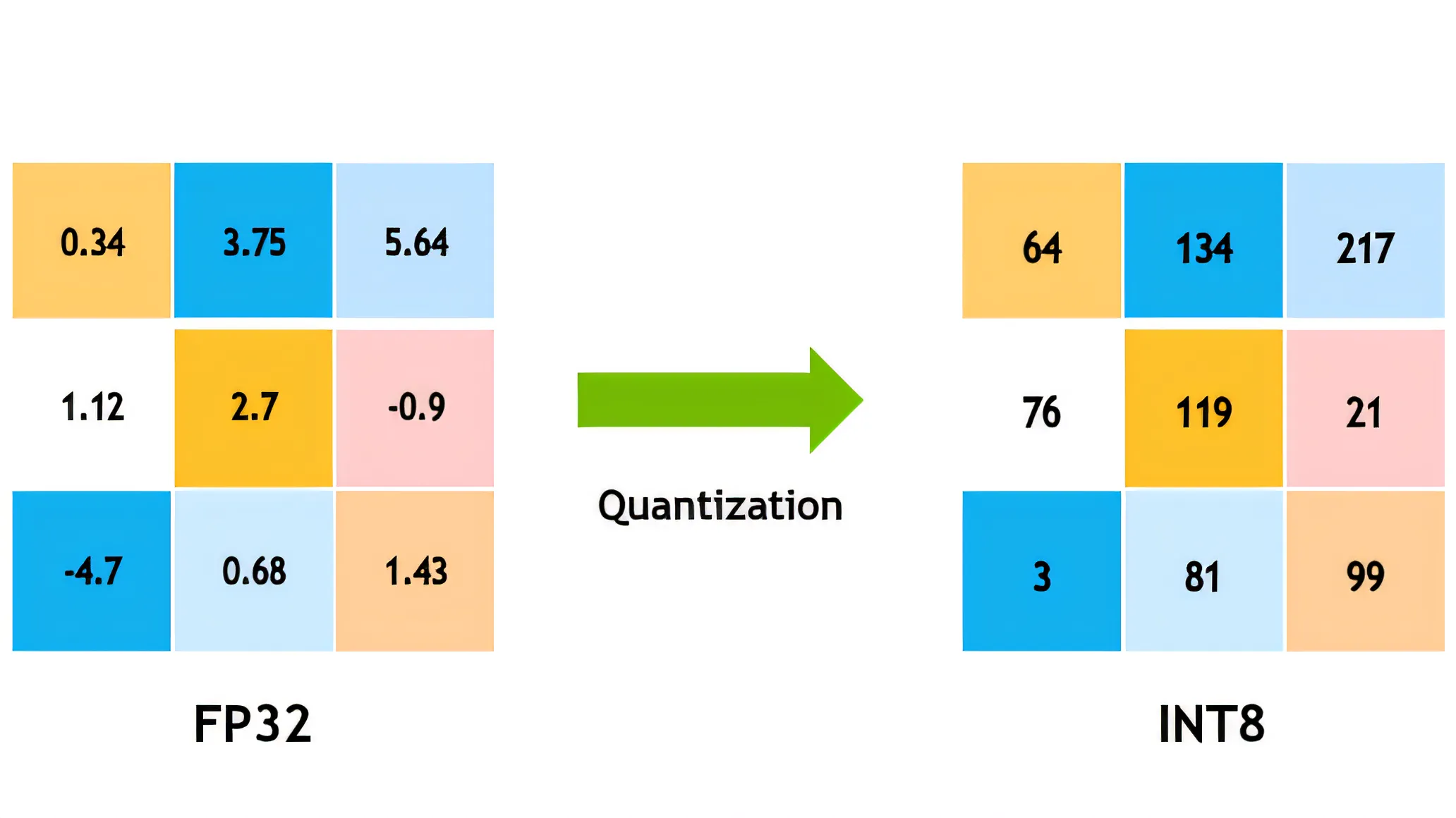
在深度学习领域,模型量化是指将模型参数从高精度表示(如32位浮点数)转换为低精度表示(如16位、8位甚至更低)的过程。这项技术正成为推动AI大模型普及的关键因素,使其能够在手机、IoT设备等计算资源有限的环境中运行。
模型量化的核心优势在于:
- 📱 显著减少模型体积
- ⚡ 加快推理速度
- 🔋 降低能耗
- 💻 减少内存占用
精度等级详解:从16比特到2比特
16比特全参数微调(FP16/BF16)
16比特全参数微调是当前大语言模型训练和微调中的主流选择,它使用半精度浮点数表示模型参数。
- 技术细节:每个参数占用16位内存,相比标准32位浮点数(FP32)减少50%存储空间
- 应用场景:大型语言模型(如GPT、LLaMA)的训练和微调
- 优势:
- 保持较高精度的同时大幅降低显存需求
- 加速训练和推理过程
- 几乎不影响模型性能
- 实际效果:在大多数任务中,16位模型与32位模型表现几乎相同
💡 小贴士:BF16(Brain Floating Point)是Google为机器学习优化的16位格式,与FP16相比具有更大的动态范围。
8位量化(INT8)
8位量化是目前应用最广泛的低精度表示方法,在推理阶段尤为常见。
- 技术细节:使用8位整数表示参数,将模型体积压缩到原来的1/4
- 应用场景:模型部署和终端推理
- 优势:
- 显著加快推理速度(约2-4倍)
- 大幅减少内存占用和存储需求
- 降低设备能耗
- 精度损失:在大多数计算机视觉任务中精度损失小于1%,语言模型中损失可控
4位量化(INT4)
4位量化代表了更激进的压缩策略,是近期AI领域的研究热点。
- 技术细节:每个参数仅使用4位表示,模型体积缩小至原来的1/8
- 应用场景:移动设备和边缘计算设备上的AI应用
- 优势:
- 极大降低模型体积和内存需求
- 显著提升推理速度
- 使大模型能够在资源受限设备上运行
- 挑战:需要采用特殊量化技术(如QLoRA)来维持模型性能
2位量化(INT2/Binary)
2位量化是当前最极端的压缩方案,处于研究前沿。
- 技术细节:每个参数仅用2个二进制位表示,通常只能表示极少数值
- 应用场景:极度资源受限的设备或对延迟要求极高的应用
- 优势:
- 模型体积可减少至原来的1/16
- 极大提升推理速度
- 极低的能耗
- 挑战:精度损失显著,需要特殊的训练和微调技术维持性能
量化技术的实际应用案例
🔍 案例一:Meta的LLaMA模型量化
Meta的LLaMA模型在4位量化后仍能保持接近原始性能的表现,体积减少75%以上。这使得原本需要数十GB存储的大模型可以部署在普通消费级设备上。
📱 案例二:手机上的实时语言翻译
Google的实时翻译功能利用8位量化模型,能在手机上实现接近实时的多语言翻译,无需云端支持。
🎮 案例三:游戏中的AI角色行为
游戏开发者使用4位甚至2位量化模型来控制NPC行为,在保持智能反应的同时显著降低CPU占用。
如何选择合适的量化精度
选择合适的量化精度需要考虑以下因素:
- 硬件限制:设备的内存、计算能力和能耗要求
- 精度要求:任务对模型精度的敏感程度
- 延迟要求:应用的实时性需求
- 部署环境:边缘设备还是服务器环境
| 量化精度 | 适用场景 | 性能影响 | 内存节省 |
|---|---|---|---|
| 16比特 | 训练和高精度要求场景 | 几乎无影响 | 50% |
| 8比特 | 通用推理场景 | 轻微影响 | 75% |
| 4比特 | 资源受限设备 | 中等影响 | 87.5% |
| 2比特 | 极端压缩场景 | 显著影响 | 93.75% |
总结与建议
模型量化技术正在改变AI行业的发展方向,使大型模型能够运行在更多设备上。对于不同应用场景,我们建议:
- 高精度要求场景:选择16比特全参数微调
- 通用应用部署:优先考虑8位量化
- 移动设备应用:探索4位量化的可能性
- 对精度不敏感的场景:可以尝试2位甚至二值化模型
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录