目录
摘要
多类分类是机器学习中一种重要的分类任务类型,它指的是将数据分为多个不同的类别或标签。与二分类问题不同,多类分类问题可以有任意数量的类别,从两个到数百个不等。在解决多类分类问题时,可以使用多种机器学习算法,如朴素贝叶斯、支持向量机、决策树、神经网络等。
这些算法可以学习从输入特征到输出类别的映射关系,并进行分类预测。例如,在电子邮件分类的问题中,模型需要将输入的邮件内容和其他特征映射到多个可能的类别中的一个,如垃圾邮件、广告邮件、工作邮件等。
多类分类在实际应用中非常广泛,如文本分类、图像分类、语音识别等。通过训练一个准确的多类分类模型,可以帮助解决各种问题,如自动垃圾邮件过滤、图像识别、情感分析等。
正文
常用场景
- 邮件分类:自动将电子邮件分类为垃圾邮件、个人、工作、社交通知等不同类别。
- 图像识别:在计算机视觉中,用于识别图片中的物体类别,如动物种类、车辆类型或医学图像中的不同组织和病变。
- 文本分类:新闻文章、博客帖子或其他文本文档可以根据其内容被分类到不同的主题或类别,如体育、政治、科技等。
- 语音识别:将语音指令分类到预定的命令集中,如智能助手理解的不同功能请求。
- 手写识别:将手写输入识别为不同的字符或数字。
- 生物信息学:在基因分类任务中,根据它们的表达模式将基因分到不同的功能类别。
- 医疗诊断:根据患者的各种医学指标将疾病分为多种类别,如不同类型的癌症或其他疾病。
- 客户分割:基于购买行为、偏好或其他特征将客户分为不同的细分市场。
- 情感分析:除了简单的正面/负面分类,情感分析可以更细致地将文本内容分到多种情绪状态,如高兴、悲伤、愤怒、惊讶等。
- 金融服务:在信用评分中,将贷款申请者根据风险等级分类到不同的信用等级中。
- 交通管理:智能交通系统可以识别道路上的不同类型的车辆,如摩托车、轿车、卡车等,以优化交通流。
- 商品分类:电商平台上的商品自动分类到不同的类目,如家电、服装、食品等。
- 语言识别:识别和分类不同的语言或方言。
- 推荐系统:根据用户的历史行为和偏好,将产品或内容分为不同的推荐类别。
为了实现多类分类,可以使用多种机器学习算法,包括决策树、随机森林、朴素贝叶斯、支持向量机、神经网络等。在处理多类分类问题时,通常需要考虑类别不平衡问题,即不同类别的样本数量可能有很大差异,这可能需要采取特定的策略来处理。
nuget安装ML.net
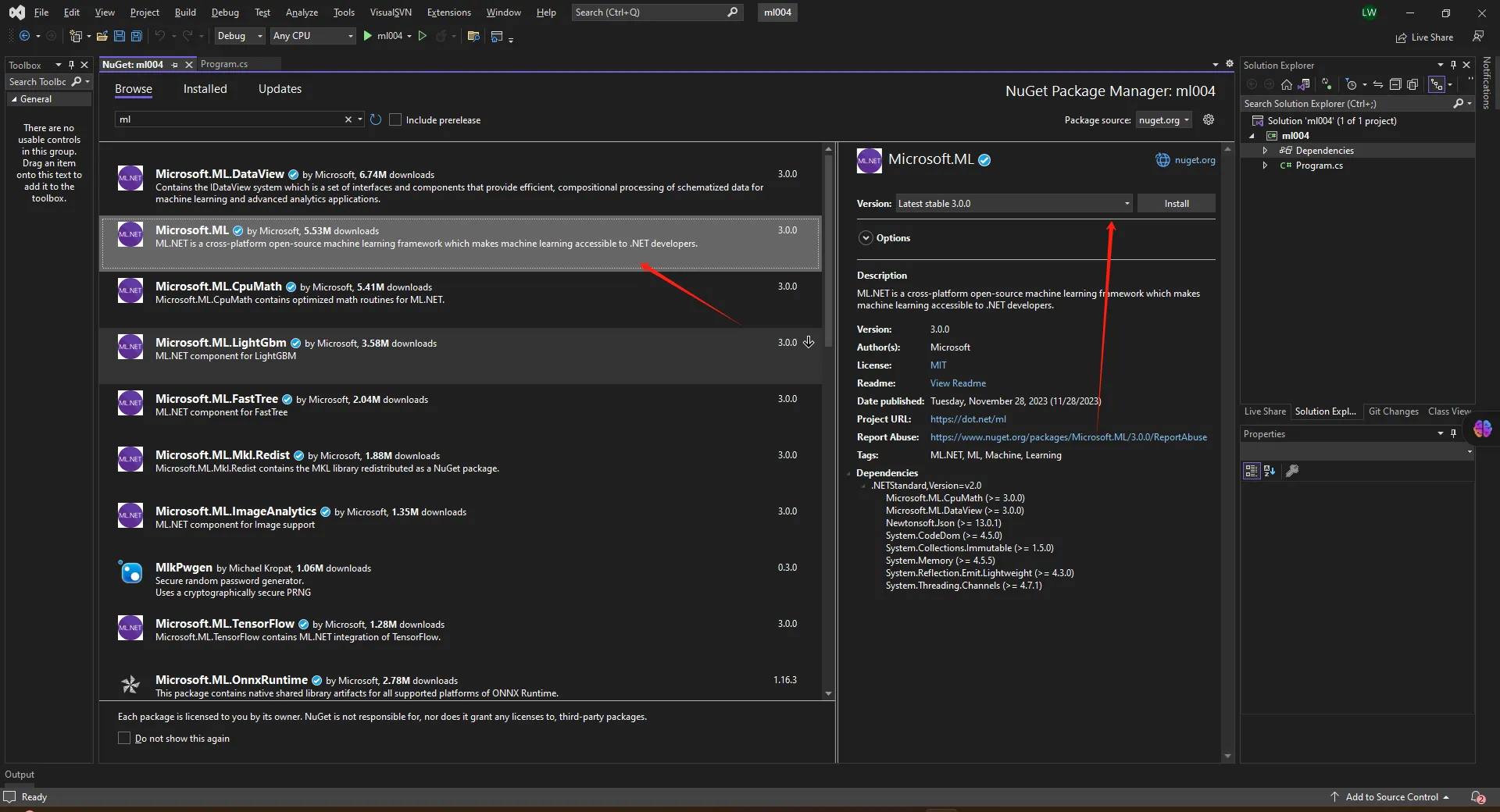
训练文件copy到data目录
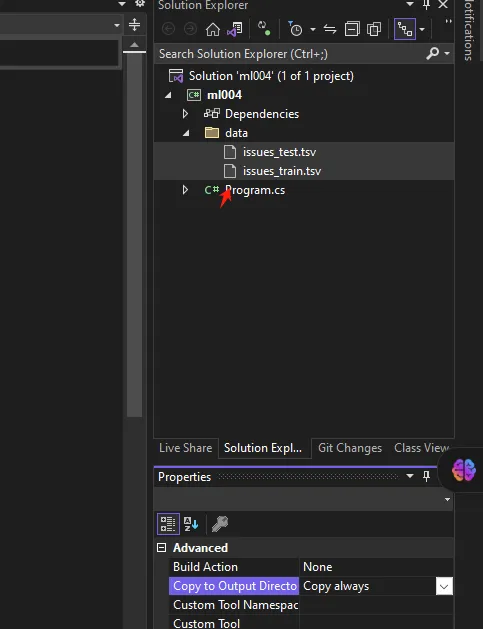
第一个数据集用于定型机器学习模型,第二个数据集可用来评估模型的准确度。
初使化
C#public class GitHubIssue
{
[LoadColumn(0)]
public string? ID { get; set; }
[LoadColumn(1)]
public string? Area { get; set; }
[LoadColumn(2)]
public required string Title { get; set; }
[LoadColumn(3)]
public required string Description { get; set; }
}
C#public class IssuePrediction
{
[ColumnName("PredictedLabel")]
public string? Area;
}
GitHubIssue 是输入数据集类,具有以下 String 字段:
- 第一列
ID(GitHub 问题 ID) - 第二列
Area(定型预测) - 第三列
Title(GitHub 问题标题)是用于预测Area的第一个feature - 第四列
Description是用于预测Area的第二个feature
IssuePrediction 是在定型模型后用于预测的类。 它有一个 string (Area) 和一个 PredictedLabel``ColumnName 属性。 PredictedLabel 在预测和评估过程中使用。 对于计算,将使用带定型数据的输入、预测值和模型。
全局声明
C#static string _trainDataPath = "./Data/issues_train.tsv";
static string _testDataPath = "./Data/issues_test.tsv";
static string _modelPath = "./Models/model.zip";
static MLContext _mlContext;
static PredictionEngine<GitHubIssue, IssuePrediction> _predEngine;
static ITransformer _trainedModel;
static IDataView _trainingDataView;
创建全局字段,来保存最近下载的文件的路径以及 MLContext、DataView 和 PredictionEngine 的全局变量:
_trainDataPath具有用于定型模型的数据集路径。_testDataPath具有用于评估模型的数据集路径。_modelPath具有在其中保存定型模型的路径。_mlContext是用于提供处理上下文的 MLContext。_trainingDataView是用于处理定型数据集的 IDataView。_predEngine是用于单个预测的 PredictionEngine<TSrc,TDst>。
初始化变量
C#//通过使用new关键字创建了一个MLContext对象,并通过构造函数的seed参数设置了一个随机种子(seed)为0。设置随机种子可以确保在多次训练过程中得到可重复的结果,这对于调试和验证模型的稳定性非常有用。如果不设置随机种子,每次运行代码时都会得到不同的结果。
_mlContext = new MLContext(seed: 0);
加载数据
C#// 通过从GitHubIssue数据模型类型中推断数据集模式创建TextLoader。
Console.WriteLine($"=============== 加载数据集 ===============");
_trainingDataView = _mlContext.Data.LoadFromTextFile<GitHubIssue>(_trainDataPath, hasHeader: true);
Console.WriteLine($"=============== 数据集加载完成 ===============");
C# var pipeline = ProcessData();
- 提取并转换数据。
- 返回处理管道。
提取功能和转换数据
C#public static IEstimator<ITransformer> ProcessData()
{
Console.WriteLine($"=============== 处理数据 ===============");
// 步骤2:常见的数据处理配置,使用管道数据转换
var pipeline = _mlContext.Transforms.Conversion.MapValueToKey(inputColumnName: "Area", outputColumnName: "Label")
.Append(_mlContext.Transforms.Text.FeaturizeText(inputColumnName: "Title", outputColumnName: "TitleFeaturized"))
.Append(_mlContext.Transforms.Text.FeaturizeText(inputColumnName: "Description", outputColumnName: "DescriptionFeaturized"))
.Append(_mlContext.Transforms.Concatenate("Features", "TitleFeaturized", "DescriptionFeaturized"))
//对DataView进行缓存,这样估计器在多次迭代数据时,不需要每次都从文件中读取,使用缓存可能会获得更好的性能。
.AppendCacheCheckpoint(_mlContext);
Console.WriteLine($"=============== 完成数据处理 ===============");
return pipeline;
}
由于要预测 GitHubIssue 的区域 GitHub 标签,因此请使用 MapValueToKey() 方法将 Area 列转换为数字键类型 Label 列(分类算法所接受的格式)并将其添加为新的数据集列:
接下来,调用 mlContext.Transforms.Text.FeaturizeText,它会将文本(Title 和 Description)列转换为每个名为 TitleFeaturized 和 DescriptionFeaturized 的值的数字向量。 使用以下代码将两列的特征化附加到管道:
数据准备最后一步使用 Concatenate() 方法将所有特征列合并到“特征”列。 默认情况下,学习算法仅处理“特征”列的特征。 使用以下代码将此转换附加到管道:
生成和定型模型
C#var trainingPipeline = BuildAndTrainModel(_trainingDataView, pipeline);
- 创建定型算法类。
- 定型模型。
- 根据定型数据预测区域。
- 返回模型。
C#// 步骤3:创建训练算法/训练器
// 使用多类别SDCA算法根据特征预测标签。
// 设置训练器/算法并将标签映射为可读状态的值。
var trainingPipeline = pipeline.Append(_mlContext.MulticlassClassification.Trainers.SdcaMaximumEntropy("Label", "Features"))
.Append(_mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
// 步骤4:训练模型并拟合数据集
Console.WriteLine($"=============== 训练模型 ===============");
_trainedModel = trainingPipeline.Fit(trainingDataView);
Console.WriteLine($"=============== 完成训练模型 结束时间: {DateTime.Now.ToString()} ===============");
// (可选)使用“刚训练的模型”进行单个预测(在保存模型之前)
Console.WriteLine($"=============== 单个预测 刚训练的模型 ===============");
// 创建与加载的训练模型相关的预测引擎
_predEngine = _mlContext.Model.CreatePredictionEngine<GitHubIssue, IssuePrediction>(_trainedModel);
GitHubIssue issue = new GitHubIssue()
{
Title = "WebSockets communication is slow in my machine",
Description = "The WebSockets communication used under the covers by SignalR looks like is going slow in my development machine.."
};
var prediction = _predEngine.Predict(issue);
Console.WriteLine($"=============== 单个预测 刚训练的模型 - 结果: {prediction.Area} ===============");
return trainingPipeline;
评估模型
C#Evaluate(_trainingDataView.Schema);
C#public static void Evaluate(DataViewSchema trainingDataViewSchema)
{
// 步骤5:评估模型以获取模型的准确度指标
Console.WriteLine($"=============== 评估模型以获取准确度指标 - 开始时间: {DateTime.Now.ToString()} ===============");
// 将测试数据集加载到IDataView中
// <SnippetLoadTestDataset>
var testDataView = _mlContext.Data.LoadFromTextFile<GitHubIssue>(_testDataPath, hasHeader: true);
// </SnippetLoadTestDataset>
// 在测试数据集上评估模型并计算模型的指标
// <SnippetEvaluate>
var testMetrics = _mlContext.MulticlassClassification.Evaluate(_trainedModel.Transform(testDataView));
// </SnippetEvaluate>
Console.WriteLine($"=============== 评估模型以获取准确度指标 - 结束时间: {DateTime.Now.ToString()} ===============");
// <SnippetDisplayMetrics>
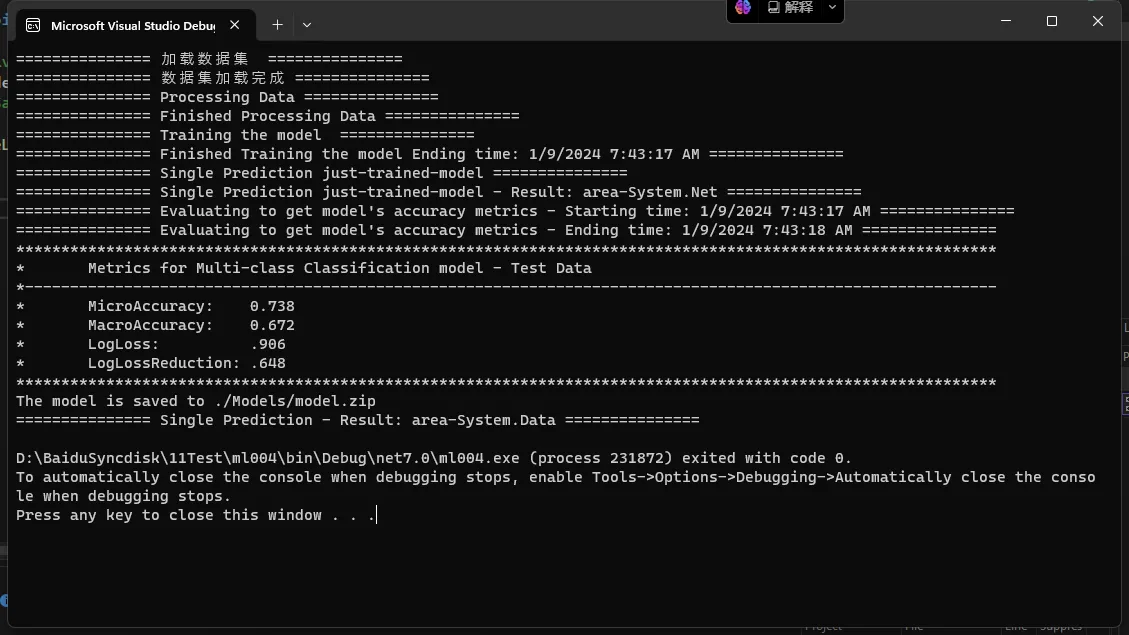
Console.WriteLine($"*************************************************************************************************************");
Console.WriteLine($"* 多类别分类模型的指标 - 测试数据集 ");
Console.WriteLine($"*------------------------------------------------------------------------------------------------------------");
Console.WriteLine($"* 微准确度: {testMetrics.MicroAccuracy:0.###}");
Console.WriteLine($"* 宏准确度: {testMetrics.MacroAccuracy:0.###}");
Console.WriteLine($"* 对数损失: {testMetrics.LogLoss:#.###}");
Console.WriteLine($"* 对数损失减少: {testMetrics.LogLossReduction:#.###}");
Console.WriteLine($"*************************************************************************************************************");
// </SnippetDisplayMetrics>
// 将新模型保存为 .ZIP 文件
// <SnippetCallSaveModel>
SaveModelAsFile(_mlContext, trainingDataViewSchema, _trainedModel);
// </SnippetCallSaveModel>
}
针对多类分类评估以下指标:
- 微观准确性 - 每个“样本-类”对准确性指标的贡献度相同。 通常会希望微观准确性尽可能接近 1。
- 宏观准确性 - 每个类对准确性指标的贡献度相同。 占比较小的类与占比较大的类拥有同等的权重。 通常会希望宏观准确性尽可能接近 1。
- 对数损失 - 请参阅对数损失。 通常会希望对数损失尽可能接近 0。
- 对数损失减小 - 取值范围为 [-inf,1.00],其中 1.00 表示非常精准的预测结果,0 表示准确性一般的预测。 通常会希望对数损失减少尽可能接近 1。
预测
C#public static void PredictIssue()
{
// <SnippetLoadModel>
ITransformer loadedModel = _mlContext.Model.Load(_modelPath, out var modelInputSchema);
// </SnippetLoadModel>
// <SnippetAddTestIssue>
GitHubIssue singleIssue = new GitHubIssue() { Title = "Entity Framework crashes", Description = "When connecting to the database, EF is crashing" };
// </SnippetAddTestIssue>
// 对单个硬编码问题进行预测标签
// <SnippetCreatePredictionEngine>
_predEngine = _mlContext.Model.CreatePredictionEngine<GitHubIssue, IssuePrediction>(loadedModel);
// </SnippetCreatePredictionEngine>
// <SnippetPredictIssue>
var prediction = _predEngine.Predict(singleIssue);
// </SnippetPredictIssue>
// <SnippetDisplayResults>
Console.WriteLine($"=============== 单个预测 - 结果: {prediction.Area} ===============");
// </SnippetDisplayResults>
}
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!