目录
摘要
K 平均值聚类(K-means clustering)是一种广泛使用的无监督学习算法,用于将数据点划分为K个不同的簇(cluster),其中K是用户指定的参数,表示希望数据被分成多少个簇。算法的目标是将数据点分配到簇中,以便簇内的数据点之间的相似度高,而不同簇之间的数据点的相似度低。
K 平均值聚类算法的基本步骤如下:
- 初始化:随机选择K个数据点作为初始的簇中心(centroid)。
- 分配:将每个数据点分配给最近的簇中心,即每个数据点归属于与其距离最近的簇。
- 更新:重新计算每个簇的中心,通常是取簇内所有点的均值作为新的簇中心。
- 迭代:重复步骤2和步骤3,直到满足停止条件,例如簇中心的变化小于某个阈值,或者达到预设的迭代次数。
- 收敛:当质心不再发生变化,或变化非常小,使得数据点的簇分配也不再变化时,算法停止。
正文
简单算法
让我们通过一个简单的例子来解释 K 平均值聚类分析的计算逻辑。假设我们有以下 2D 空间中的 6 个数据点,我们想将它们聚类成 K=2 个簇。
数据点如下:
- A(1, 1)
- B(1, 2)
- C(2, 2)
- D(8, 8)
- E(8, 9)
- F(9, 8)
下面是 K 平均值聚类分析的步骤:
- 初始化:随机选择 K=2 个质心。假设我们选择了点 A(1, 1) 和点 D(8, 8) 作为初始质心。
- 分配步骤:
- 计算每个数据点到两个质心的距离,并将每个点分配给最近的质心。
- A, B, C 被分配到质心 A(1, 1),因为它们离 A 更近。
- D, E, F 被分配到质心 D(8, 8),因为它们离 D 更近。
- 更新步骤:
- 对于由 A, B, C 组成的簇,新的质心是这三个点坐标的平均值,即 (1+1+2)/3, (1+2+2)/3 = (4/3, 5/3) ≈ (1.33, 1.67)。
- 对于由 D, E, F 组成的簇,新的质心是这三个点坐标的平均值,即 (8+8+9)/3, (8+9+8)/3 = (25/3, 25/3) ≈ (8.33, 8.33)。
- 迭代:
- 使用新的质心 (1.33, 1.67) 和 (8.33, 8.33),重复分配步骤和更新步骤。
- 在这个简单的例子中,由于数据点是均匀分布的,新的质心可能与原来的质心非常接近,所以算法可能会在这一步结束。
- 收敛:
- 当质心不再变化,或者变化非常小,使得数据点的簇分配也不再变化时,算法停止。
- 在这个例子中,我们可能已经达到了收敛,因为在第一次迭代后,簇分配没有变化。
最终,我们有两个簇:
- 簇 1:A, B, C,质心大约在 (1.33, 1.67)
- 簇 2:D, E, F,质心大约在 (8.33, 8.33)
常用应用场景
- 市场细分:企业可以使用K-平均值聚类对客户进行分组,以便更好地理解不同的市场细分,并根据购买行为、兴趣、收入水平等因素制定定制化的营销策略。
- 图像分割:在图像处理领域,K-平均值聚类可以用于颜色量化或图像分割,将图像中的像素分组成几个颜色簇,以简化图像或减少颜色的数量。
- 文档聚类:文本挖掘中,K-平均值聚类可以帮助组织、分类和检索大量的文档或新闻文章,通过分析文档中的词频来发现相似的文档。
- 异常检测:在一组数据中,通过聚类可以识别与大多数数据点显著不同的异常值或离群值。
- 基因表达分析:生物信息学中,K-平均值聚类被用来分析基因表达数据,以发现具有相似表达模式的基因,这可能表明它们参与了相同的生物过程。
- 社交网络分析:在社交网络分析中,K-平均值聚类可以帮助识别具有相似兴趣或行为的用户群体。
- 客户细分:零售和电子商务网站可以使用K-平均值聚类对客户进行分组,以便为不同类型的客户提供个性化的推荐和服务。
- 库存分类:零售商可以使用K-平均值聚类对产品进行分类,以优化库存管理和销售策略。
- 城市规划:城市规划者可能会使用K-平均值聚类来识别城市中的不同区域,以便更有效地规划资源和服务的分配。
- 天文数据分析:天文学家使用K-平均值聚类对星体进行分类,以便对大量天文数据进行分析和解释。
K-平均值聚类的关键挑战之一是选择合适的K值(即簇的数量)。通常需要使用如肘部法则(Elbow Method)、轮廓分析(Silhouette Method)等技术来确定最佳的K值。此外,由于K-平均值聚类对初始簇中心的选择敏感,可能需要多次运行算法以获得稳定的聚类结果。
nuget 安装ml.net
准备数据
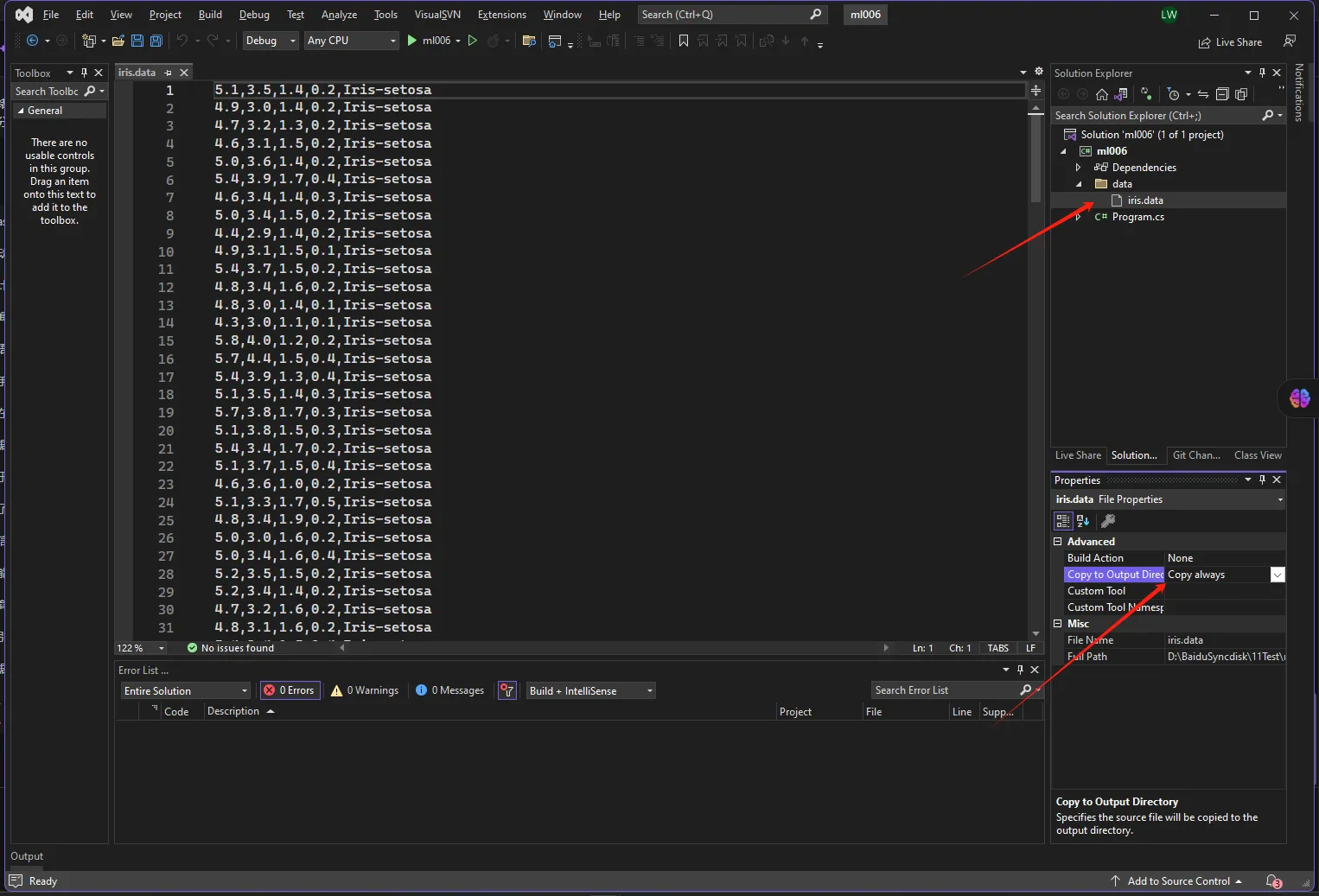
该 iris.data 文件包含五列,分别代表以下内容 :
- 花萼长度(厘米)
- 花萼宽度(厘米)
- 花瓣长度(厘米)
- 花瓣宽度(厘米)
- 鸢尾花类型 (忽略)
创建数据类
IrisData类
C#public class IrisData
{
[LoadColumn(0)]
public float SepalLength;
[LoadColumn(1)]
public float SepalWidth;
[LoadColumn(2)]
public float PetalLength;
[LoadColumn(3)]
public float PetalWidth;
}
[LoadColumn(n)] 是一个属性(Attribute),它在这里用来指示机器学习数据加载过程中,每个字段应当从数据文件中的哪一列加载。这通常用在基于.NET的机器学习库,如ML.NET中,用于数据预处理和加载的过程。n 是列索引,从0开始计数,对应于数据文件中的列。
例如,[LoadColumn(0)] 表明 SepalLength 应当从数据集的第一列加载,[LoadColumn(1)] 表明 SepalWidth 应当从第二列加载,以此类推。
ClusterPrediction类
C#public class ClusterPrediction
{
[ColumnName("PredictedLabel")]
public uint PredictedClusterId;
[ColumnName("Score")]
public float[]? Distances;
}
ClusterPrediction 是用来表示聚类模型的预测结果的数据结构。这个类定义了两个属性:
PredictedClusterId: 表示预测的聚类ID,用于标识数据点被分配到的聚类。它被定义为public uint(无符号整型),这意味着它是公开可访问的,并且只能存储非负整数值。[ColumnName("PredictedLabel")]属性指定了当预测结果被输出时,这个字段应当对应的列名是"PredictedLabel"。Distances: 表示数据点到各个聚类中心的距离数组。这是一个可空(nullable)的浮点数数组,意味着它可以包含零个或多个浮点数,或者是null。[ColumnName("Score")]属性指定了当预测结果被输出时,这个字段应当对应的列名是"Score"。
定义数据和模型路径
C#static readonly string _dataPath = "./data/iris.data";
static readonly string _modelPath = "./data/IrisClusteringModel.zip";
创建 ML 上下文
C#// 创建一个新的 MLContext 实例,用于随机化和其他设置。这是开始使用 ML.NET 时的入口点。
var mlContext = new MLContext(seed: 0);
设置数据加载
C#// 从文本文件加载数据。这里的 'IrisData' 是一个将定义数据结构的类。
IDataView dataView = mlContext.Data.LoadFromTextFile<IrisData>(_dataPath, hasHeader: false, separatorChar: ',');
创建学习管道
C#// 创建一个数据处理管道。首先,它将四个特征列合并到一个特征向量中,然后应用 KMeans 聚类算法。
string featuresColumnName = "Features";
var pipeline = mlContext.Transforms
.Concatenate(featuresColumnName, "SepalLength", "SepalWidth", "PetalLength", "PetalWidth")
.Append(mlContext.Clustering.Trainers.KMeans(featuresColumnName, numberOfClusters: 3));
- 将加载的列连接到“Features”列,由聚类分析训练程序使用 ;
- 借助 KMeansTrainer 训练程序使用 k - 平均值 + + 聚类分析算法来定型模型。
定型模型
C#// 训练模型。这将运行数据通过管道,并输出一个训练好的模型。
var model = pipeline.Fit(dataView);
保存模型
C#// 保存模型到文件。这样,您就可以在其他地方加载和使用它。
using (var fileStream = new FileStream(_modelPath, FileMode.Create, FileAccess.Write, FileShare.Write))
{
mlContext.Model.Save(model, dataView.Schema, fileStream);
}
使用预测模型
C#// 创建一个预测引擎。这可以用来对新的、未见过的数据进行预测。
var predictor = mlContext.Model.CreatePredictionEngine<IrisData, ClusterPrediction>(model);
使用预测模型
TestIrisData 类测试数据实例
C#internal static readonly IrisData Setosa = new IrisData
{
SepalLength = 5.1f,
SepalWidth = 3.5f,
PetalLength = 1.4f,
PetalWidth = 0.2f
};
C#// 使用预测引擎对一个示例数据进行预测。这里 'Setosa' 是一个包含花卉测量数据的实例。
var prediction = predictor.Predict(Setosa);
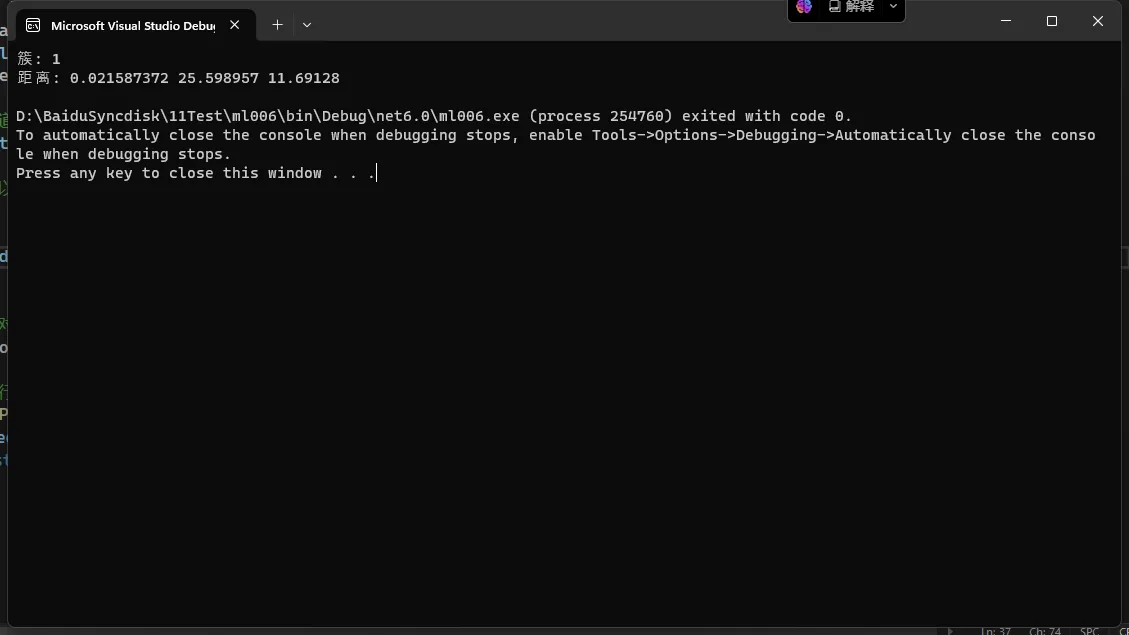
Console.WriteLine($"簇: {prediction.PredictedClusterId}");
Console.WriteLine($"距离: {string.Join(" ", prediction.Distances)}");
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!