目录
在Python开发中,你是否遇到过这样的困扰:项目越来越大,代码文件越来越多,不知道如何优雅地组织和复用代码?或者在导入模块时总是出现ModuleNotFoundError错误,不知道该如何解决?
作为一名Windows下的Python开发者,掌握模块导入与使用技巧是构建大型应用程序的基础。本文将从实战角度出发,深入浅出地讲解Python模块系统的核心概念,帮你解决模块导入的常见问题,让你的代码更加模块化、可维护。无论你是初学者还是有一定经验的开发者,这篇文章都将为你的Python编程技巧带来质的提升。
🔍 问题分析:为什么要使用模块?
代码复用性差的痛点
在实际开发中,我们经常遇到以下问题:
- 代码重复:相同的函数在多个文件中重复定义
- 文件过大:单个.py文件包含过多功能,难以维护
- 命名冲突:不同功能的函数使用相同名称
- 团队协作困难:多人开发时代码组织混乱
模块化开发的优势
Python的模块系统完美解决了这些问题:
- 代码复用:一次编写,多处使用
- 命名空间隔离:避免命名冲突
- 逻辑分离:不同功能模块独立开发和测试
- 提升可维护性:代码结构清晰,便于后期维护
💡 解决方案:Python模块系统详解
🏗️ 模块的基本概念
在Python中,**模块(Module)**就是一个包含Python代码的.py文件。每个模块都是一个独立的命名空间,可以定义函数、类和变量。
📦 包(Package)的概念
**包(Package)**是包含多个模块的文件夹,必须包含__init__.py文件(Python 3.3+中可选)。包提供了更高层次的代码组织方式。
Pythonmyproject/ ├── __init__.py ├── utils/ │ ├── __init__.py │ ├── file_helper.py │ └── data_processor.py └── core/ ├── __init__.py └── main_logic.py
🔧 代码实战:模块导入的各种方式
🌟 基础导入方式
import 语句
Python# 导入整个模块
import os
import sys
import datetime
# 使用模块中的功能
current_path = os.getcwd()
current_time = datetime.datetime.now()
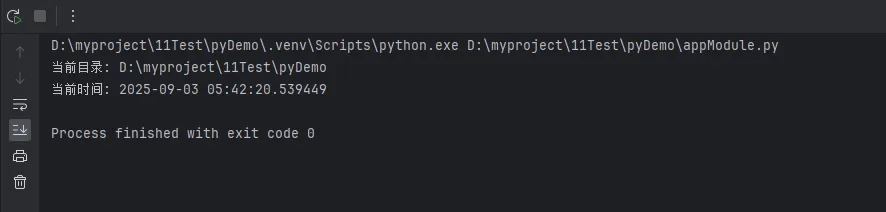
print(f"当前目录: {current_path}")
print(f"当前时间: {current_time}")
from...import 语句
Python# 从模块中导入特定功能
from os import getcwd, listdir
from datetime import datetime, timedelta
# 直接使用导入的功能
current_path = getcwd()
current_time = datetime.now()
使用别名(as)
Python# 为模块或功能起别名
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
matplotlib.use('TkAgg')
data = np.array([1, 2, 3, 4, 5])
plt.plot(data)
plt.show()

🔥 实战案例:构建模块化的文件处理工具
让我们通过一个完整的例子来演示模块化开发:
步骤1:创建工具模块 file_utils.py
Python# file_utils.py - 文件处理工具模块
import os
import json
import csv
from typing import List, Dict, Any
class FileManager:
"""文件管理器类"""
def __init__(self, base_path: str = "."):
self.base_path = base_path
def list_files(self, extension: str = None) -> List[str]:
"""列出指定扩展名的文件"""
files = []
for file in os.listdir(self.base_path):
if extension is None or file.endswith(extension):
files.append(file)
return files
def read_json(self, filename: str) -> Dict[Any, Any]:
"""读取JSON文件"""
filepath = os.path.join(self.base_path, filename)
try:
with open(filepath, 'r', encoding='utf-8') as f:
return json.load(f)
except FileNotFoundError:
print(f"文件 {filename} 不存在")
return {}
except json.JSONDecodeError:
print(f"文件 {filename} 不是有效的JSON格式")
return {}
def write_json(self, data: Dict[Any, Any], filename: str):
"""写入JSON文件"""
filepath = os.path.join(self.base_path, filename)
with open(filepath, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=2)
def get_file_size(filepath: str) -> int:
"""获取文件大小(字节)"""
try:
return os.path.getsize(filepath)
except OSError:
return -1
def create_backup(source_file: str, backup_suffix: str = "_backup"):
"""创建文件备份"""
name, ext = os.path.splitext(source_file)
backup_file = f"{name}{backup_suffix}{ext}"
try:
with open(source_file, 'rb') as src:
with open(backup_file, 'wb') as dst:
dst.write(src.read())
print(f"备份创建成功: {backup_file}")
return backup_file
except IOError as e:
print(f"备份创建失败: {e}")
return None
步骤2:创建数据处理模块 data_processor.py
Python# data_processor.py - 数据处理模块
import pandas as pd
from typing import List, Dict
import statistics
class DataAnalyzer:
"""数据分析器"""
def __init__(self, data: List[Dict] = None):
self.data = data or []
def load_from_csv(self, filename: str):
"""从CSV文件加载数据"""
try:
df = pd.read_csv(filename)
self.data = df.to_dict('records')
print(f"成功加载 {len(self.data)} 条数据")
except Exception as e:
print(f"加载CSV文件失败: {e}")
def get_summary(self, column: str) -> Dict:
"""获取数值列的统计摘要"""
if not self.data:
return {}
values = []
for record in self.data:
if column in record and isinstance(record[column], (int, float)):
values.append(record[column])
if not values:
return {"error": f"列 '{column}' 不存在或不包含数值数据"}
return {
"count": len(values),
"mean": statistics.mean(values),
"median": statistics.median(values),
"min": min(values),
"max": max(values),
"std": statistics.stdev(values) if len(values) > 1 else 0
}
def filter_data(self, condition_func) -> List[Dict]:
"""根据条件过滤数据"""
return [record for record in self.data if condition_func(record)]
def clean_text_data(text_list: List[str]) -> List[str]:
"""清理文本数据"""
cleaned = []
for text in text_list:
if isinstance(text, str):
# 去除首尾空格,转换为小写
cleaned_text = text.strip().lower()
if cleaned_text: # 过滤空字符串
cleaned.append(cleaned_text)
return cleaned
步骤3:创建主应用 main.py
Python# main.py - 主应用程序
from file_utils import FileManager, get_file_size, create_backup
from data_processor import DataAnalyzer, clean_text_data
import os
def demo_file_operations():
"""演示文件操作功能"""
print("=== 文件操作演示 ===")
# 创建文件管理器实例
fm = FileManager("./data") # 假设有一个data文件夹
# 列出所有Python文件
python_files = fm.list_files(".py")
print(f"Python文件: {python_files}")
# 创建示例数据
sample_data = {
"project": "Python模块化开发",
"author": "Python专家",
"files": python_files
}
# 写入JSON文件
fm.write_json(sample_data, "project_info.json")
# 读取JSON文件
loaded_data = fm.read_json("project_info.json")
print(f"读取的数据: {loaded_data}")
def demo_data_analysis():
"""演示数据分析功能"""
print("\n=== 数据分析演示 ===")
# 创建示例数据
sample_records = [
{"name": "张三", "age": 25, "salary": 8000},
{"name": "李四", "age": 30, "salary": 12000},
{"name": "王五", "age": 28, "salary": 10000},
{"name": "赵六", "age": 35, "salary": 15000}
]
# 创建数据分析器
analyzer = DataAnalyzer(sample_records)
# 获取薪资统计
salary_summary = analyzer.get_summary("salary")
print(f"薪资统计: {salary_summary}")
# 过滤高薪员工
high_salary = analyzer.filter_data(lambda x: x.get("salary", 0) > 10000)
print(f"高薪员工: {high_salary}")
# 文本清理演示
dirty_texts = [" Hello World ", "PYTHON Programming", "", " data science "]
clean_texts = clean_text_data(dirty_texts)
print(f"清理后的文本: {clean_texts}")
def main():
"""主函数"""
print("🚀 Python模块化开发演示")
print("=" * 40)
# 确保data目录存在
if not os.path.exists("./data"):
os.makedirs("./data")
try:
demo_file_operations()
demo_data_analysis()
print("\n✅ 演示完成!")
except Exception as e:
print(f"❌ 运行出错: {e}")
if __name__ == "__main__":
main()

🎯 高级导入技巧
动态导入
Python# 根据条件动态导入模块
def get_processor(processor_type: str):
if processor_type == "json":
from json import loads, dumps
return loads, dumps
elif processor_type == "csv":
import csv
return csv.reader, csv.writer
else:
raise ValueError(f"不支持的处理器类型: {processor_type}")
# 使用示例
reader, writer = get_processor("csv")
条件导入和异常处理
Python# 处理可选依赖
try:
import pandas as pd
HAS_PANDAS = True
except ImportError:
HAS_PANDAS = False
print("警告: 未安装pandas,部分功能不可用")
def advanced_data_process(data):
if HAS_PANDAS:
# 使用pandas处理
df = pd.DataFrame(data)
return df.describe()
else:
# 使用基础方法处理
return {"message": "请安装pandas以使用高级功能"}
def basic_data_process(data):
# 基础数据处理逻辑
return {"length": len(data)}
def main():
sample_data = [1, 2, 3, 4, 5]
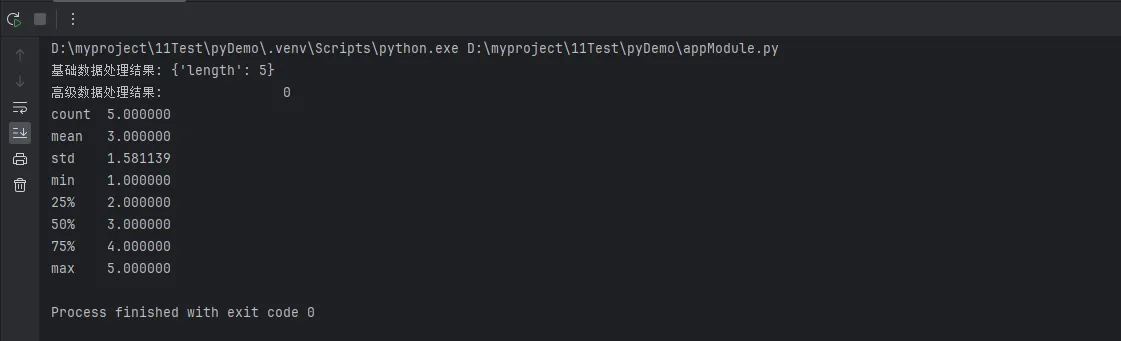
print("基础数据处理结果:", basic_data_process(sample_data))
print("高级数据处理结果:", advanced_data_process(sample_data))
if __name__ == "__main__":
main()
🛠️ 模块导入的最佳实践
导入顺序规范
Python# 1. 标准库导入
import os
import sys
import json
from typing import List, Dict
# 2. 第三方库导入
import numpy as np
import pandas as pd
import requests
# 3. 本地应用导入
from .utils import FileManager
from .processors import DataAnalyzer
避免循环导入
Python# ❌ 错误示例 - 容易造成循环导入
# module_a.py
from module_b import function_b
def function_a():
return function_b()
# module_b.py
from module_a import function_a # 循环导入!
def function_b():
return function_a()
# ✅ 正确做法 - 将共同依赖提取到第三个模块
# common.py
def shared_function():
return "shared logic"
# module_a.py
from common import shared_function
# module_b.py
from common import shared_function
🚀 实际应用场景
Windows桌面应用开发示例
Python# gui_app.py - 使用tkinter开发桌面应用
import tkinter as tk
from tkinter import filedialog, messagebox
from file_utils import FileManager, create_backup
from data_processor import DataAnalyzer
class FileProcessorApp:
def __init__(self):
self.root = tk.Tk()
self.root.title("文件处理工具")
self.root.geometry("500x400")
self.file_manager = FileManager()
self.setup_ui()
def setup_ui(self):
# 文件选择按钮
select_btn = tk.Button(
self.root,
text="选择文件",
command=self.select_file,
font=("微软雅黑", 12)
)
select_btn.pack(pady=20)
# 结果显示区域
self.result_text = tk.Text(
self.root,
height=20,
width=60,
font=("Consolas", 10)
)
self.result_text.pack(padx=20, pady=20, fill=tk.BOTH, expand=True)
def select_file(self):
filename = filedialog.askopenfilename(
title="选择要处理的文件",
filetypes=[("JSON文件", "*.json"), ("所有文件", "*.*")]
)
if filename:
self.process_file(filename)
def process_file(self, filename):
try:
# 创建备份
backup_file = create_backup(filename)
# 处理文件
if filename.endswith('.json'):
data = self.file_manager.read_json(filename)
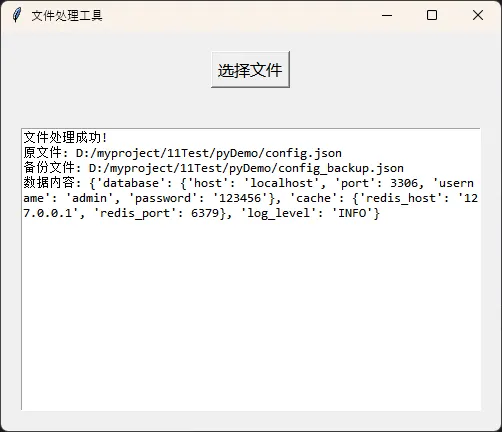
result = f"文件处理成功!\n"
result += f"原文件: {filename}\n"
result += f"备份文件: {backup_file}\n"
result += f"数据内容: {data}\n"
self.result_text.delete(1.0, tk.END)
self.result_text.insert(tk.END, result)
except Exception as e:
messagebox.showerror("错误", f"文件处理失败: {e}")
def run(self):
self.root.mainloop()
# 启动应用
if __name__ == "__main__":
app = FileProcessorApp()
app.run()
💪 常见问题与解决方案
🔍 模块搜索路径调试
Pythonimport sys
print("Python模块搜索路径:")
for i, path in enumerate(sys.path):
print(f"{i+1}. {path}")
# 查看模块所在位置
import os
print(f"os模块位置: {os.__file__}")
# 查看当前工作目录
print(f"当前工作目录: {os.getcwd()}")

✨ 总结核心要点
通过本文的深入讲解和实战演示,我们掌握了Python模块导入与使用的核心技能。让我们回顾三个关键要点:
1. 模块化设计思维:将功能按逻辑分组,创建专门的工具模块,如文件处理、数据分析等,提高代码的复用性和可维护性。这种设计思维不仅适用于个人项目,在团队协作和大型应用开发中更是必不可少。
2. 灵活的导入策略:根据实际需求选择合适的导入方式,掌握绝对导入、相对导入、动态导入和条件导入的使用场景。特别是在Windows环境下开发上位机应用时,合理的导入策略能有效避免路径问题和依赖冲突。
3. 实战应用能力:通过文件处理工具和桌面应用的完整示例,我们看到了模块化开发在实际项目中的强大威力。这些模式可以直接应用到你的Python开发项目中,无论是数据处理、GUI应用还是自动化脚本。
掌握这些技能后,你将能够构建更加专业、可扩展的Python应用程序。继续实践这些概念,探索更多的模块化设计模式,让你的Python编程技巧更上一层楼!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!