目录
作为Python开发者,你是否遇到过这样的困扰:项目文件越来越多,模块导入变得混乱,不知道如何合理组织代码结构?或者看到别人项目中那些神秘的__init__.py文件,却不知道它们的真正作用?
本文将深入解析Python包的概念和__init__.py文件的核心机制,帮你构建更加专业和可维护的项目架构。通过实战案例,你将学会如何利用包管理让代码组织井然有序,提升Python开发效率。
🔍 什么是Python包?模块与包的本质区别
📁 模块 vs 包:一个文件 vs 一个文件夹
在Python编程中,很多开发者容易混淆模块和包的概念:
模块(Module):
- 本质上就是一个
.py文件 - 包含Python代码、函数、类等
- 可以被其他程序导入使用
包(Package):
- 是一个包含多个模块的文件夹
- 必须包含
__init__.py文件(Python 3.3+可选,但强烈推荐) - 可以包含子包,形成层次结构
💡 为什么需要包?
想象你在开发一个上位机开发项目,涉及串口通信、数据处理、界面显示等多个功能模块:
Markdownmain.py
serial_comm.py
data_parser.py
ui_manager.py
config_handler.py
logger_utils.py
database_ops.py
# ... 更多文件
随着项目增长,根目录会变得杂乱无章。使用包管理后:
Markdownmain.py
src/
├── __init__.py
├── communication/
│ ├── __init__.py
│ ├── serial_comm.py
│ └── tcp_comm.py
├── data/
│ ├── __init__.py
│ ├── parser.py
│ └── validator.py
├── ui/
│ ├── __init__.py
│ ├── main_window.py
│ └── dialogs.py
└── utils/
├── __init__.py
├── config.py
└── logger.py
🔥 init.py:包的灵魂文件
🎯 init.py的核心作用
__init__.py文件是Python包的标识符和初始化器,它有四个重要作用:
- 标识包:告诉Python这个文件夹是一个包
- 初始化包:包被导入时执行的代码
- 控制导入:定义
from package import *的行为 - 简化导入路径:创建便捷的导入接口
💻 实战案例:构建一个数据处理包
让我们创建一个完整的数据处理包来演示__init__.py的强大功能:
Python# data_processor/__init__.py
"""
数据处理包 - 提供数据清洗、分析和可视化功能
适用于上位机开发中的数据处理需求
"""
# 包的版本信息
__version__ = "1.0.0"
__author__ = "Python技术分享"
# 导入核心模块
from .cleaner import DataCleaner
from .analyzer import DataAnalyzer
from .visualizer import DataVisualizer
# 定义公开的API
__all__ = [
'DataCleaner',
'DataAnalyzer',
'DataVisualizer',
'quick_analysis'
]
# 包级别的便捷函数
def quick_analysis(data, chart_type='line'):
"""
快速数据分析函数
Args:
data: 原始数据
chart_type: 图表类型
Returns:
分析结果和图表对象
"""
cleaner = DataCleaner()
analyzer = DataAnalyzer()
visualizer = DataVisualizer()
clean_data = cleaner.clean(data)
result = analyzer.analyze(clean_data)
chart = visualizer.plot(result, chart_type)
return result, chart
# 包初始化时的配置
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
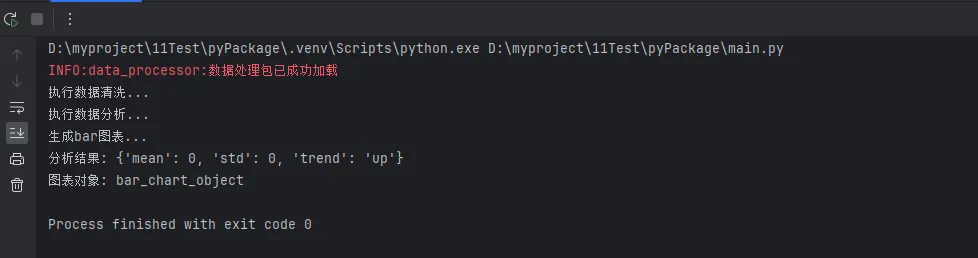
logger.info("数据处理包已成功加载")
📊 子模块实现
data_processor/cleaner.py
Pythonclass DataCleaner:
"""数据清洗类"""
def clean(self, data):
"""清洗数据中的异常值和缺失值"""
print("执行数据清洗...")
# 实际的数据清洗逻辑
return data
def remove_outliers(self, data, threshold=3):
"""移除异常值"""
print(f"移除阈值为{threshold}的异常值...")
return data
data_processor/analyzer.py
Pythonclass DataAnalyzer:
"""数据分析类"""
def analyze(self, data):
"""执行统计分析"""
print("执行数据分析...")
return {"mean": 0, "std": 0, "trend": "up"}
def correlation_analysis(self, data):
"""相关性分析"""
print("执行相关性分析...")
return {}
data_processor/visualizer.py
Pythonclass DataVisualizer:
"""数据可视化类"""
def plot(self, data, chart_type='line'):
"""生成图表"""
print(f"生成{chart_type}图表...")
return f"{chart_type}_chart_object"
def export_chart(self, chart, filename):
"""导出图表"""
print(f"导出图表到{filename}")
🔆使用
Pythonimport data_processor
def main():
# 示例数据
raw_data = [1, 2, None, 4, 100, 6, 7, 8, None, 10]
# 使用包级别的便捷函数进行快速分析
result, chart = data_processor.quick_analysis(raw_data, chart_type='bar')
print("分析结果:", result)
print("图表对象:", chart)
if __name__ == "__main__":
main()
🚀 init.py的高级用法
🎨 动态导入和延迟加载
对于大型项目,可以实现动态导入来提升性能:
Python"""
advanced_package.py
示例高级包:包含延迟加载器、重型处理类和轻量函数。
"""
import importlib
from typing import Optional
class LazyLoader:
"""延迟加载器"""
def __init__(self, module_name: str):
self.module_name = module_name
self._module: Optional[object] = None
def __getattr__(self, item):
if self._module is None:
# 第一次访问时导入目标模块
self._module = importlib.import_module(self.module_name)
return getattr(self._module, item)
class HeavyProcessing:
def __init__(self):
# 模拟沉重的初始化过程
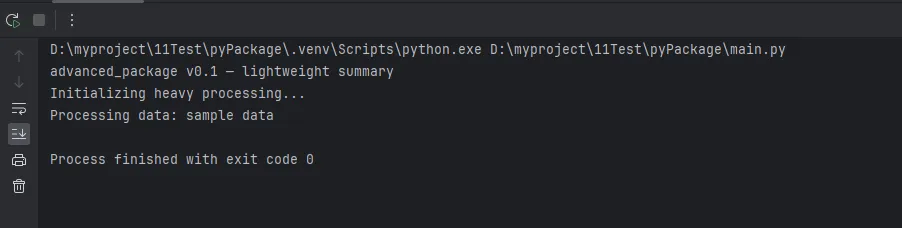
print("Initializing heavy processing...")
def process(self, data):
# 模拟沉重的处理任务
print(f"Processing data: {data}")
return f"Processed {data}"
def quick_summary():
"""轻量函数:快速返回包信息,不触发重量级导入"""
return "advanced_package v0.1 — lightweight summary"
Pythonclass HeavyProcessing:
def __init__(self):
# Simulate a heavy initialization process
print("Initializing heavy processing...")
def process(self, data):
# Simulate a heavy processing task
print(f"Processing data: {data}")
return f"Processed {data}"
📈 包管理最佳实践
✅ init.py设计原则
- 保持简洁:只导入必要的公共API
- 版本控制:包含版本信息和变更日志
- 异常处理:统一的异常类定义
- 文档完善:清晰的docstring和使用说明
- 向后兼容:考虑API的稳定性
🎯 常见陷阱避免
Python# ❌ 错误做法:循环导入
# package/__init__.py
from .module_a import ClassA
from .module_b import ClassB
# package/module_a.py
from .module_b import ClassB # 可能导致循环导入
# ✅ 正确做法:延迟导入或重构设计
# package/__init__.py
def get_class_a():
from .module_a import ClassA
return ClassA
def get_class_b():
from .module_b import ClassB
return ClassB
🛠️ 调试技巧
Python# debug_package/__init__.py
"""
包调试和诊断工具
"""
import sys
import os
# 调试模式检测
DEBUG = os.getenv('PYTHON_DEBUG', 'False').lower() == 'true'
if DEBUG:
import logging
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)
# 打印导入信息
logger.debug(f"包路径: {__file__}")
logger.debug(f"Python版本: {sys.version}")
logger.debug(f"包搜索路径: {sys.path}")
# 导入跟踪
def trace_imports():
import importlib.util
logger.debug("开始导入跟踪...")
trace_imports()
🎊 总结要点
通过本文的深入解析,你已经掌握了Python包管理的核心知识:
🔑 三个关键要点:
- 包的本质:包是包含
__init__.py的文件夹,用于组织多个相关模块,让项目结构更清晰 - init.py的威力:它不仅是包的标识符,更是控制导入行为、提供便捷API的强大工具
- 实战应用:在上位机开发和Python编程项目中,合理的包设计能显著提升代码的可维护性和专业度
掌握这些编程技巧后,你的Python项目将告别杂乱无章,拥有更加专业和优雅的代码架构。记住,好的包设计不仅让代码组织井然有序,更能让团队协作事半功倍!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录