目录
说到Python开发,数据类型真的是绕不开的话题。不管是刚学编程的小白,还是已经写了不少代码的老手,都得对数据类型有扎实的理解。不然,项目写到一半,遇到一堆类型转换的坑,或者选错了数据结构导致性能拉胯,那可就尴尬了。
这篇文章的目标就是帮你搞定这些麻烦事儿!我们会从实战的角度出发,聊聊Python的核心数据类型,像数字、字符串、列表、字典这些常用的东西,怎么用才更高效,怎么避免踩坑。而且,还会分享一些可以直接上手的小技巧,让你写代码时更加得心应手。
🔍 问题分析:为什么数据类型如此重要?
在实际开发中,我们经常遇到以下问题:
🚨 常见痛点
- 类型错误:字符串和数字混用导致程序崩溃
- 性能问题:不合适的数据结构导致程序运行缓慢
- 内存浪费:错误的类型选择占用过多内存
- 代码可读性差:数据类型不明确导致维护困难
这些问题的根源往往在于对Python数据类型的理解不够深入。
💡 解决方案:系统性掌握Python数据类型
🏗️ Python数据类型体系结构
Python的数据类型可以分为以下几大类,其实数据类型,大多数语言都是一样的。
MarkdownPython数据类型
├── 数值类型(Numbers)
│ ├── int(整数)
│ ├── float(浮点数)
│ └── complex(复数)
├── 序列类型(Sequences)
│ ├── str(字符串)
│ ├── list(列表)
│ └── tuple(元组)
├── 集合类型(Sets)
│ ├── set(可变集合)
│ └── frozenset(不可变集合)
├── 映射类型(Mappings)
│ └── dict(字典)
└── 布尔类型(Boolean)
└── bool(布尔值)
🚀 代码实战:深入理解每种数据类型
1️⃣ 数值类型:精确计算的基础
🔢 整数类型 (int)
Python# 基础用法
age = 25
user_id = 12345
# 不同进制表示
binary_num = 0b1010 # 二进制,值为10
octal_num = 0o12 # 八进制,值为10
hex_num = 0xa # 十六进制,值为10
# 大整数支持(Python 3无限制)
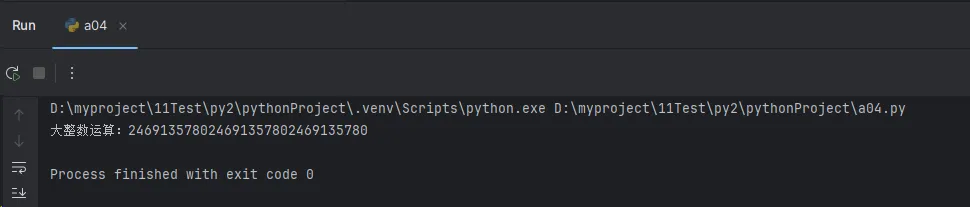
big_number = 123456789012345678901234567890
print(f"大整数运算:{big_number * 2}")
# 实战技巧:类型检查
def safe_divide(a, b):
if isinstance(a, int) and isinstance(b, int) and b != 0:
return a / b
else:
raise ValueError("参数必须为非零整数") a
🔢 浮点数类型 (float)
注意:float会有精度问题,这块与javascript中的浮点类型一回事。
Python# 基础用法
price = 99.99
temperature = -15.5
# 科学计数法
large_num = 1.5e6 # 1,500,000
small_num = 1.5e-6 # 0.0000015
# ⚠️ 浮点数精度问题及解决方案
from decimal import Decimal
# 错误示例
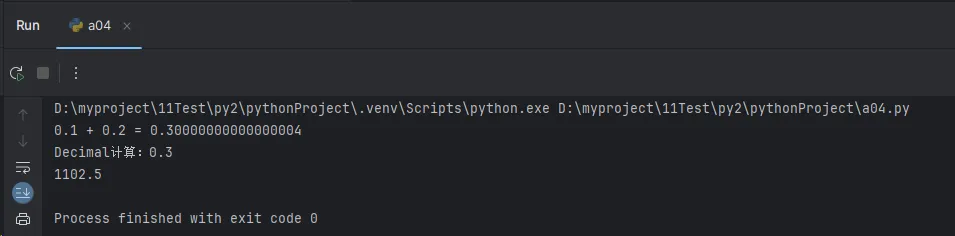
result1 = 0.1 + 0.2
print(f"0.1 + 0.2 = {result1}") # 0.30000000000000004
# 正确做法
result2 = Decimal('0.1') + Decimal('0.2')
print(f"Decimal计算:{result2}") # 0.3
# 实战应用:金融计算
def calculate_interest(principal, rate, time):
"""计算复利,使用Decimal避免精度问题"""
principal = Decimal(str(principal))
rate = Decimal(str(rate))
time = Decimal(str(time))
amount = principal * (1 + rate) ** time
return float(amount)
print(calculate_interest(1000, 0.05, 2))
2️⃣ 字符串类型:文本处理的利器
Python# 字符串创建的多种方式
name1 = "张三"
name2 = '李四'
multiline = """
这是一个
多行字符串a
"""
raw_string = r"C:\Users\张三\Documents" # 原始字符串,避免转义
# 🔥 字符串格式化最佳实践
user_name = "Python学习者"
score = 98.5
level = "高级"
# f-string(推荐)
message1 = f"恭喜{user_name},您的得分是{score:.1f},等级:{level}"
# format方法
message2 = "恭喜{},您的得分是{:.1f},等级:{}".format(user_name, score, level)
# 字符串常用操作
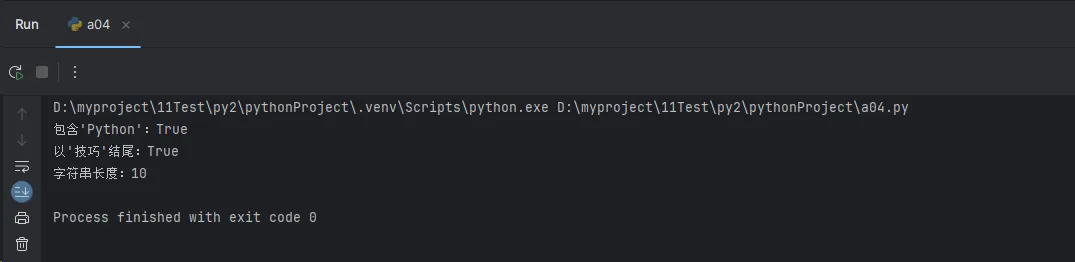
text = "Python编程技巧"
# 检查操作
print(f"包含'Python':{text.startswith('Python')}")
print(f"以'技巧'结尾:{text.endswith('技巧')}")
print(f"字符串长度:{len(text)}")
# 实战函数:验证输入格式
def validate_email(email):
"""简单的邮箱格式验证"""
if isinstance(email, str) and '@' in email and '.' in email:
return email.lower().strip()
else:
raise ValueError("邮箱格式不正确")
3️⃣ 列表类型:动态数据容器
Python# 列表创建和基础操作
numbers = [1, 2, 3, 4, 5]
mixed_list = [1, "hello", 3.14, True]
empty_list = []
# 🔥 列表高级操作技巧
# 列表推导式(性能优异)
squares = [x ** 2 for x in range(10)]
even_squares = [x ** 2 for x in range(10) if x % 2 == 0]
# 切片操作
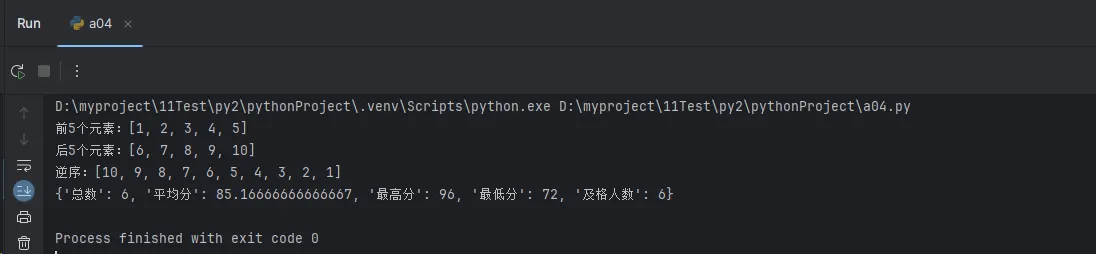
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(f"前5个元素:{data[:5]}")
print(f"后5个元素:{data[-5:]}")
print(f"逆序:{data[::-1]}")
# 实战应用:数据处理
def process_user_scores(scores):
"""处理用户分数数据"""
if not scores:
return {"error": "分数列表为空"}
# 过滤有效分数
valid_scores = [s for s in scores if isinstance(s, (int, float)) and 0 <= s <= 100]
if not valid_scores:
return {"error": "没有有效分数"}
return {
"总数": len(valid_scores),
"平均分": sum(valid_scores) / len(valid_scores),
"最高分": max(valid_scores),
"最低分": min(valid_scores),
"及格人数": len([s for s in valid_scores if s >= 60])
}
# 测试
test_scores = [85, 92, 78, 96, 88, "无效", 105, -5, 72]
result = process_user_scores(test_scores)
print(result)
4️⃣ 字典类型:键值对数据结构
Python# 字典创建方式
user_info = {
"name": "张三",
"age": 28,
"city": "北京",
"skills": ["Python", "JavaScript", "SQL"]
}
# 使用dict()构造函数
config = dict(
host="localhost",
port=8080,
debug=True
)
# 🔥 字典高级操作
# 字典推导式
word_count = {"apple": 5, "banana": 3, "cherry": 8}
filtered_words = {k: v for k, v in word_count.items() if v > 4} # {'apple': 5, 'cherry': 8}
# 安全获取值
def get_user_info(user_dict, key, default="未知"):
"""安全获取用户信息"""
return user_dict.get(key, default)
# 字典合并(Python 3.9+)
default_config = {"timeout": 30, "retries": 3}
user_config = {"timeout": 60, "debug": True}
final_config = default_config | user_config # 合并配置
# 实战应用:数据统计
def analyze_log_data(log_entries):
"""分析日志数据,统计各种信息"""
stats = {
"total_requests": 0,
"status_codes": {},
"ip_addresses": {},
"error_count": 0
}
for entry in log_entries:
if not isinstance(entry, dict):
continue
# 统计总请求数
stats["total_requests"] += 1
# 统计状态码
status = entry.get("status_code", "unknown")
stats["status_codes"][status] = stats["status_codes"].get(status, 0) + 1
# 统计IP地址
ip = entry.get("ip", "unknown")
stats["ip_addresses"][ip] = stats["ip_addresses"].get(ip, 0) + 1
# 统计错误
if isinstance(status, int) and status >= 400:
stats["error_count"] += 1
# 计算错误率
if stats["total_requests"] > 0:
stats["error_rate"] = (stats["error_count"] / stats["total_requests"]) * 100
return stats
# 打印final_config
print(final_config)
# 打印filtered_words
print(filtered_words)
# 构造测试日志数据
test_log_entries = [
{"ip": "192.168.1.1", "status_code": 200},
{"ip": "192.168.1.2", "status_code": 404},
{"ip": "192.168.1.1", "status_code": 500},
{"ip": "192.168.1.3", "status_code": 200},
{"ip": "192.168.1.4", "status_code": 302},
{"ip": "192.168.1.2", "status_code": 200},
{"ip": "192.168.1.3", "status_code": 404},
{"ip": "192.168.1.1", "status_code": 403},
{"ip": "192.168.1.4", "status_code": 200},
{"ip": "192.168.1.5", "status_code": 502},
]
# 调用分析方法并输出结果
result = analyze_log_data(test_log_entries)
print(result)

5️⃣ 集合类型:去重和集合运算
Python# 集合创建
numbers_set = {1, 2, 3, 4, 5}
empty_set = set() # 注意:{}创建的是空字典,不是空集合
# 从列表创建集合(自动去重)
duplicated_list = [1, 2, 2, 3, 3, 3, 4, 5]
unique_numbers = set(duplicated_list) # {1, 2, 3, 4, 5}
# 🔥 集合运算实战
set_a = {1, 2, 3, 4, 5}
set_b = {4, 5, 6, 7, 8}
print(f"并集:{set_a | set_b}") # {1, 2, 3, 4, 5, 6, 7, 8}
print(f"交集:{set_a & set_b}") # {4, 5}
print(f"差集:{set_a - set_b}") # {1, 2, 3}
print(f"对称差集:{set_a ^ set_b}") # {1, 2, 3, 6, 7, 8}
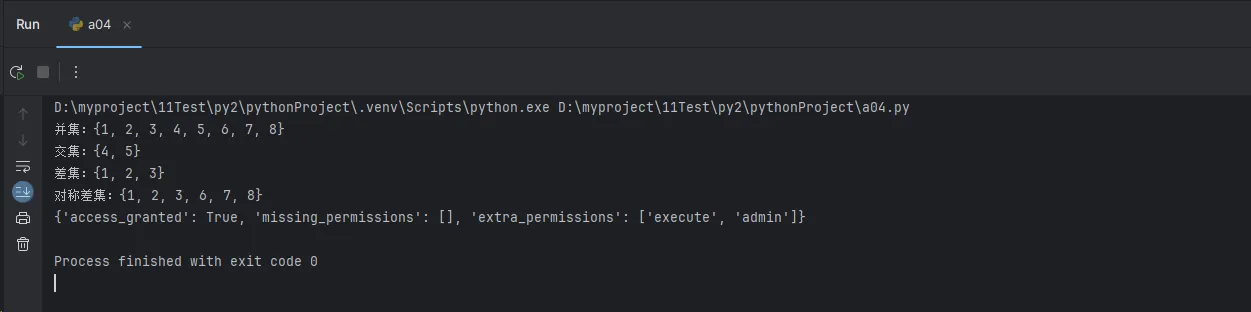
# 实战应用:权限管理系统
def check_user_permissions(user_permissions, required_permissions):
"""检查用户是否具备所需权限"""
user_perms = set(user_permissions)
required_perms = set(required_permissions)
# 检查是否有所需的所有权限
has_all_permissions = required_perms.issubset(user_perms)
missing_permissions = required_perms - user_perms
extra_permissions = user_perms - required_perms
return {
"access_granted": has_all_permissions,
"missing_permissions": list(missing_permissions),
"extra_permissions": list(extra_permissions)
}
# 测试权限系统
user_perms = ["read", "write", "execute", "admin"]
required_perms = ["read", "write"]
result = check_user_permissions(user_perms, required_perms)
print(result)
6️⃣ 布尔类型和None:逻辑控制
Python# 布尔值和真值测试
is_active = True
is_deleted = False
# Python的真值测试
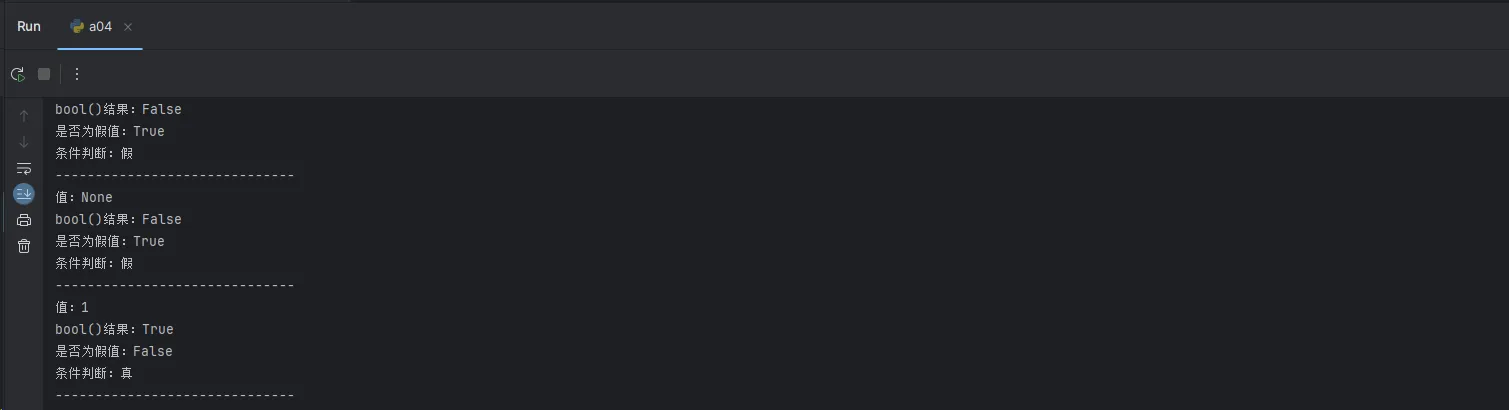
def is_truthy(value):
"""测试值的真假性"""
falsy_values = [False, None, 0, 0.0, "", [], {}, set()]
print(f"值:{repr(value)}")
print(f"bool()结果:{bool(value)}")
print(f"是否为假值:{value in falsy_values}")
print(f"条件判断:{'真' if value else '假'}")
print("-" * 30)
# 测试各种值
test_values = [True, False, 1, 0, "hello", "", [1, 2], [], None]
for val in test_values:
is_truthy(val)
# 实战应用:配置验证
def validate_config(config):
"""验证配置参数"""
errors = []
# 检查必需字段
required_fields = ["host", "port", "database"]
for field in required_fields:
if not config.get(field): # 利用真值测试
errors.append(f"缺少必需字段:{field}")
# 检查端口号
port = config.get("port")
if port and (not isinstance(port, int) or port <= 0 or port > 65535):
errors.append("端口号必须是1-65535之间的整数")
return {
"valid": len(errors) == 0,
"errors": errors
}
is_truthy(1)
🎯 性能优化技巧
🚀 数据类型选择的性能考量
Pythonimport time
from collections import deque
def performance_comparison():
"""比较不同数据类型的性能"""
# 列表 vs 集合:查找性能
large_list = list(range(10000))
large_set = set(range(10000))
# 列表查找
start_time = time.time()
for i in range(100000):
_ = 9999 in large_list
list_time = time.time() - start_time
# 集合查找
start_time = time.time()
for i in range(100000):
_ = 9999 in large_set
set_time = time.time() - start_time
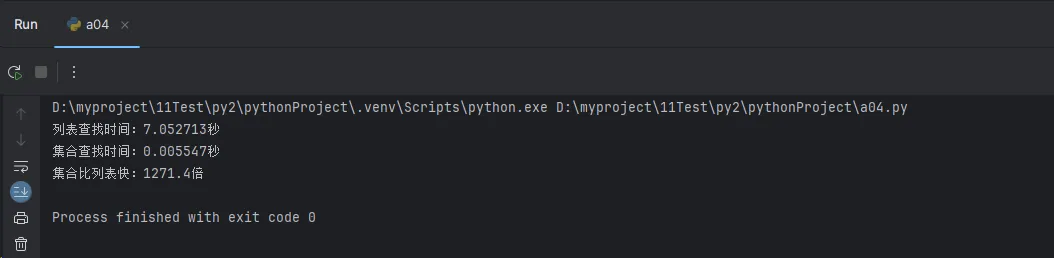
print(f"列表查找时间:{list_time:.6f}秒")
print(f"集合查找时间:{set_time:.6f}秒")
print(f"集合比列表快:{list_time / set_time:.1f}倍")
# 内存使用优化
def memory_efficient_processing(data):
"""内存高效的数据处理"""
# 使用生成器表达式而非列表推导式
return (x * 2 for x in data if x > 0) # 生成器,按需计算
# 字典默认值优化
from collections import defaultdict
def count_words_efficient(text):
"""高效的单词计数"""
word_count = defaultdict(int) # 自动提供默认值0
for word in text.split():
word_count[word] += 1 # 无需检查键是否存在
return dict(word_count)
performance_comparison()
🛠️ 实战项目:数据类型综合应用
Pythonclass DataProcessor:
"""数据处理器:综合运用各种数据类型"""
def __init__(self):
self.data_cache = {} # 字典:缓存处理结果
self.processed_ids = set() # 集合:记录已处理的ID
self.processing_log = [] # 列表:处理日志
def process_user_data(self, users_data):
"""
处理用户数据
users_data: [{"id": 1, "name": "张三", "scores": [85, 90, 88]}, ...]
"""
results = {
"total_users": 0,
"processed_users": 0,
"average_scores": {},
"top_performers": [],
"processing_errors": []
}
for user in users_data:
try:
# 类型检查
if not isinstance(user, dict):
raise ValueError("用户数据必须是字典类型")
user_id = user.get("id")
if not isinstance(user_id, int):
raise ValueError("用户ID必须是整数")
# 避免重复处理
if user_id in self.processed_ids:
continue
results["total_users"] += 1
# 处理分数数据
scores = user.get("scores", [])
if isinstance(scores, list) and scores:
# 过滤有效分数
valid_scores = [s for s in scores if isinstance(s, (int, float)) and 0 <= s <= 100]
if valid_scores:
avg_score = sum(valid_scores) / len(valid_scores)
results["average_scores"][user.get("name", f"User_{user_id}")] = round(avg_score, 2)
# 记录高分用户
if avg_score >= 90:
results["top_performers"].append({
"name": user.get("name", f"User_{user_id}"),
"average_score": avg_score
})
# 标记为已处理
self.processed_ids.add(user_id)
results["processed_users"] += 1
# 记录处理日志
self.processing_log.append(f"成功处理用户 {user_id}")
except Exception as e:
error_msg = f"处理用户数据时出错:{str(e)}"
results["processing_errors"].append(error_msg)
self.processing_log.append(error_msg)
# 按平均分排序top performers
results["top_performers"].sort(key=lambda x: x["average_score"], reverse=True)
# 缓存结果
cache_key = f"batch_{len(self.processed_ids)}"
self.data_cache[cache_key] = results
return results
def get_processing_summary(self):
"""获取处理摘要"""
return {
"cached_results": len(self.data_cache),
"total_processed_ids": len(self.processed_ids),
"log_entries": len(self.processing_log),
"last_logs": self.processing_log[-5:] if self.processing_log else []
}
# 测试数据处理器
if __name__ == "__main__":
processor = DataProcessor()
# 测试数据
test_data = [
{"id": 1, "name": "张三", "scores": [85, 90, 88]},
{"id": 2, "name": "李四", "scores": [92, 95, 89]},
{"id": 3, "name": "王五", "scores": [78, 82, 85]},
{"id": 4, "name": "赵六", "scores": [95, 98, 94]},
]
# 处理数据
results = processor.process_user_data(test_data)
# 输出结果
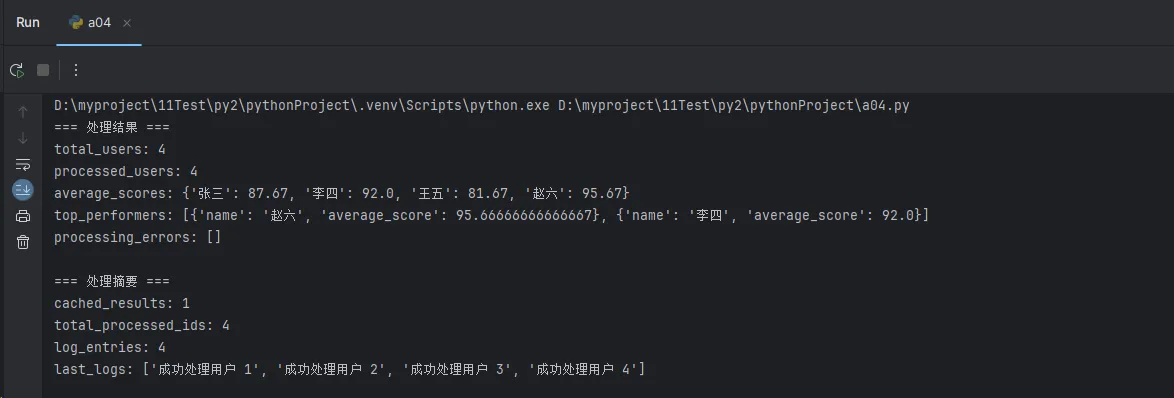
print("=== 处理结果 ===")
for key, value in results.items():
print(f"{key}: {value}")
print("\n=== 处理摘要 ===")
summary = processor.get_processing_summary()
for key, value in summary.items():
print(f"{key}: {value}")
🎯 结尾呼应
通过本文的深入学习,我们系统性地掌握了Python数据类型的核心知识和实战技巧。让我们来总结三个关键要点:
🔑 核心要点一:类型选择决定性能
正确选择数据类型不仅能避免程序错误,更能显著提升程序性能。记住集合用于查找、字典用于映射、列表用于序列操作的基本原则,在实际开发中会事半功倍。
🔑 核心要点二:实战应用是检验标准
理论知识只有与实际项目结合才能发挥真正价值。本文提供的数据处理器、权限管理系统等实例都是可以直接应用到你的Python开发项目中的。在Windows环境下进行上位机开发时,这些技巧将帮助你构建更加健壮和高效的应用程序。
🔑 核心要点三:持续优化是进阶之路
掌握基础数据类型只是开始,通过性能分析、内存优化等编程技巧,你可以将代码质量提升到新的高度。记住,优秀的程序员不仅要写出能运行的代码,更要写出优雅、高效、可维护的代码。
希望这篇文章能够成为你Python学习路上的有力助手。数据类型是编程的基石,掌握它们就掌握了构建优秀程序的核心能力。继续实践,不断探索,你一定能在Python开发的道路上走得更远!
💡 延伸学习建议:深入学习Python的高级数据结构(如collections模块)、类型注解和数据类验证,将进一步提升你的编程水平。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!