目录
在.NET中,性能优化是一个永恒的话题,尤其是在处理大量数据或高并发场景下。ArrayPool<T>作为.NET的一个高性能特性,能够显著减少数组的创建和销毁对内存和垃圾回收(GC)的影响,从而提高应用程序的性能。本文将探讨ArrayPool<T>的应用场景,并通过具体示例展示如何在实际开发中使用它。
ArrayPool简介
ArrayPool<T>是.NET中用于数组重用的对象池。它允许开发者从池中租用数组,使用完毕后再将其归还,以便于数组可以被后续操作重用。这种机制减少了数组创建的次数,降低了GC的压力,特别是在处理大型数组或频繁操作数组的场景中。
应用场景
场景一:大量数据处理
在数据分析、图像处理或文件操作等需要处理大量数据的应用中,频繁地创建和销毁大型数组会严重影响性能。
示例:使用ArrayPool<T>处理大型数据集
C#static void Main(string[] args)
{
// 获取共享的ArrayPool实例
var pool = ArrayPool<float>.Shared;
// 从池中租用一个包含100万个元素的数组
var largeArray = pool.Rent(1000000);
try
{
// 使用租用的数组处理大量数据
ProcessData(largeArray);
// 打印数组的前10个元素,以验证数据处理
for (int i = 0; i < 10; i++)
{
Console.WriteLine(largeArray[i]);
}
}
finally
{
// 归还数组到池中,并指定清除数组内容
pool.Return(largeArray, clearArray: true);
}
}
// 定义处理大量数据的方法
static void ProcessData(float[] data)
{
// 假设的数据处理:简单地将每个元素的值设置为其索引值
for (int i = 0; i < data.Length; i++)
{
data[i] = i;
}
}
在这个例子中,ProcessData方法遍历数组,将每个元素的值设置为其索引值。这是一个简单的操作,旨在模拟处理大量数据的场景。在真实的应用场景中,这里的数据处理逻辑可能会更复杂,比如进行数值计算、数据分析、图像处理等。
注意,在finally块中,我们使用了pool.Return(largeArray, clearArray: true);来归还数组。clearArray: true参数确保归还前数组的内容被清除,这是一个好习惯,特别是在处理包含敏感信息的数据时,可以防止数据泄露。
场景二:高并发环境
在Web服务器或并行计算场景下,可能需要为每个请求或任务分配独立的缓冲区。使用ArrayPool<T>可以避免为每个并发任务创建新的数组。
示例:在并发环境下使用ArrayPool<T>
C#static void Main(string[] args)
{
var pool = ArrayPool<byte>.Shared;
Parallel.For(0, 100, (i) =>
{
var buffer = pool.Rent(1024); // 为每个任务租用一个1KB的数组
try
{
// 执行并发任务
PerformTask(buffer, (byte)i);
// 打印每个任务处理的数组的前5个字节
Console.WriteLine($"Task {i}: [{string.Join(", ", buffer[0..5])}]");
}
finally
{
pool.Return(buffer, clearArray: false);
}
});
}
// 定义执行并发任务的方法
static void PerformTask(byte[] buffer, byte taskId)
{
// 将数组的每个字节设置为当前任务的编号
for (int i = 0; i < buffer.Length; i++)
{
buffer[i] = taskId;
}
}
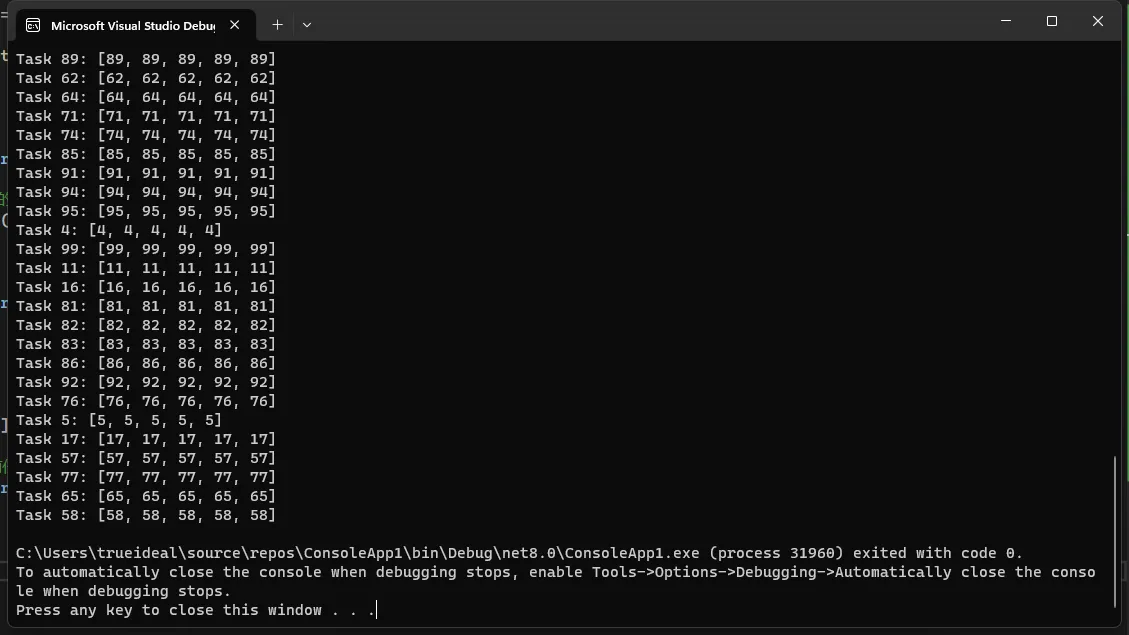
在这个例子中,PerformTask方法接受一个字节数组buffer和一个字节taskId作为参数。方法将数组中的每个字节设置为taskId,模拟对数据的处理。由于我们在Parallel.For循环中并发执行此方法,每个任务都会并发地修改其各自的数组。
请注意,由于Parallel.For的并发性质,输出的顺序可能与任务的启动顺序不同。此外,pool.Return(buffer, clearArray: false);在finally块中被调用,确保即使发生异常,数组也会被正确地归还到池中。这里我们选择不清除数组内容(clearArray: false),因为我们假设数组的下一个使用者会完全覆盖或不关心旧数据。在处理包含敏感信息的数据时,建议将clearArray设置为true以清除数据。
场景三:IO操作缓冲
在进行文件读写或网络数据传输时,通常需要临时缓冲区。ArrayPool<T>提供了一种高效的方式来重用这些缓冲区。
示例:使用ArrayPool<T>进行文件读取
C#static void Main(string[] args)
{
var pool = ArrayPool<byte>.Shared;
var buffer = pool.Rent(4096); // 租用一个4KB的数组作为缓冲区
try
{
using (var stream = new FileStream("./example.txt", FileMode.Open))
{
int bytesRead;
while ((bytesRead = stream.Read(buffer, 0, buffer.Length)) > 0)
{
// 处理读取的数据
ProcessBufferData(buffer, bytesRead);
}
}
}
finally
{
pool.Return(buffer, clearArray: false);
}
}
// 定义处理读取的数据的方法
static void ProcessBufferData(byte[] buffer, int bytesRead)
{
// 将字节转换为字符串
string text = Encoding.UTF8.GetString(buffer, 0, bytesRead);
// 打印到控制台
Console.WriteLine(text);
}
在这个示例中,ProcessBufferData方法接收一个字节数组buffer和一个表示读取的字节数的bytesRead参数。它使用Encoding.UTF8.GetString方法将字节数组的有效部分(即实际读取的部分)转换为字符串,并将其打印到控制台。
请注意,在处理完所有数据并在finally块中归还数组之后,我们没有清除数组内容(clearArray: false)。这是因为在这个特定的示例中,我们不关心数组中剩余的数据。然而,在处理包含敏感信息的数据时,出于安全考虑,建议在归还数组时将clearArray设置为true。
总结
ArrayPool<T>是.NET中一个强大的工具,它通过减少数组的创建和销毁,降低了GC的压力,从而提高了应用程序的性能。无论是在处理大量数据、高并发环境下的任务分配,还是作为IO操作的缓冲区,ArrayPool<T>都能提供显著的性能优势。正确地使用ArrayPool<T>,可以使我们的.NET应用更加高效、稳定。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!