目录
正则表达式是一种强大的文本处理工具,它允许你进行复杂的文本匹配、提取和替换操作。在C#中,正则表达式通过 System.Text.RegularExpressions.Regex 类提供支持。本文将介绍如何在C#中使用正则表达式的捕获组和反向引用,并通过示例来演示它们的用法。
捕获组
捕获组是正则表达式中用圆括号 () 包围的部分,它可以捕获匹配的文本供后续使用。每个捕获组会按照它们在正则表达式中出现的顺序自动编号,编号从1开始。
示例 1:捕获单词
C#string pattern = @"(\w+)\s(\w+)";
string input = "Hello World";
Match match = Regex.Match(input, pattern);
if (match.Success)
{
Console.WriteLine($"第一个单词:{match.Groups[1].Value}");
Console.WriteLine($"第二个单词:{match.Groups[2].Value}");
}
输出:
C#第一个单词:Hello 第二个单词:World
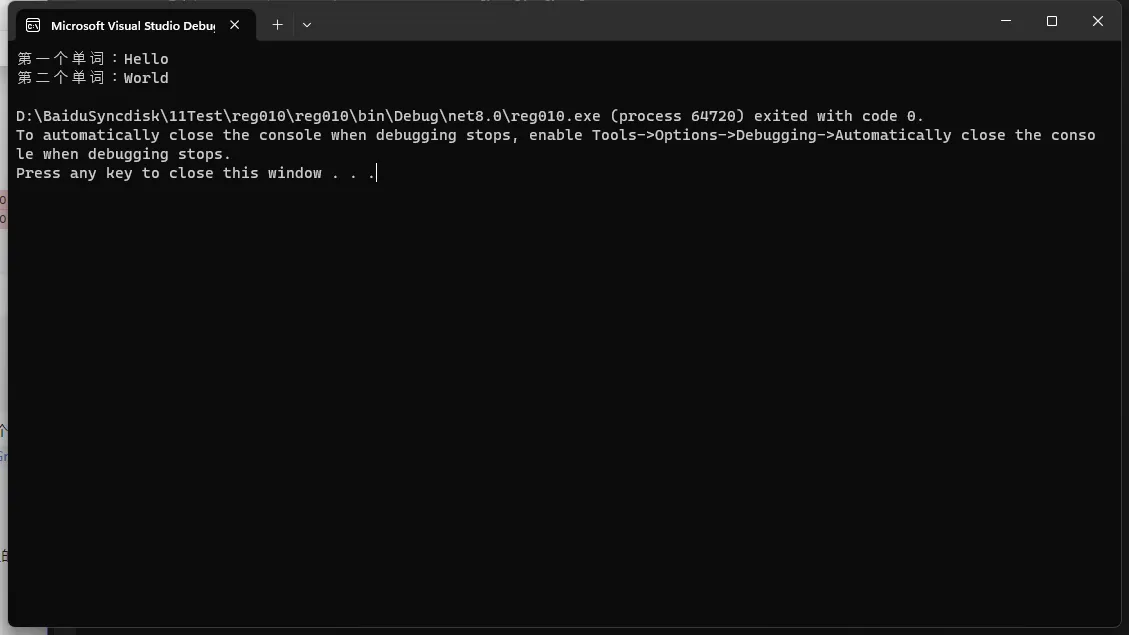 在这个示例中,正则表达式
在这个示例中,正则表达式 (\w+)\s(\w+) 包含两个捕获组,每个捕获组匹配一个单词(\w+),并且单词之间由空格分隔(\s)。match.Groups[1].Value 和 match.Groups[2].Value 分别包含第一个和第二个捕获组匹配到的文本。
反向引用
反向引用允许在同一个正则表达式内部引用前面定义的捕获组。反向引用的语法是 \数字,其中“数字”是你想要引用的捕获组的编号。
示例 2:匹配重复的单词
C#string pattern = @"(\w+)\s\1";
string input = "Hello Hello World World";
MatchCollection matches = Regex.Matches(input, pattern);
foreach (Match match in matches)
{
Console.WriteLine($"匹配到的重复单词:{match.Groups[1].Value}");
}
输出:
C#匹配到的重复单词:Hello 匹配到的重复单词:World
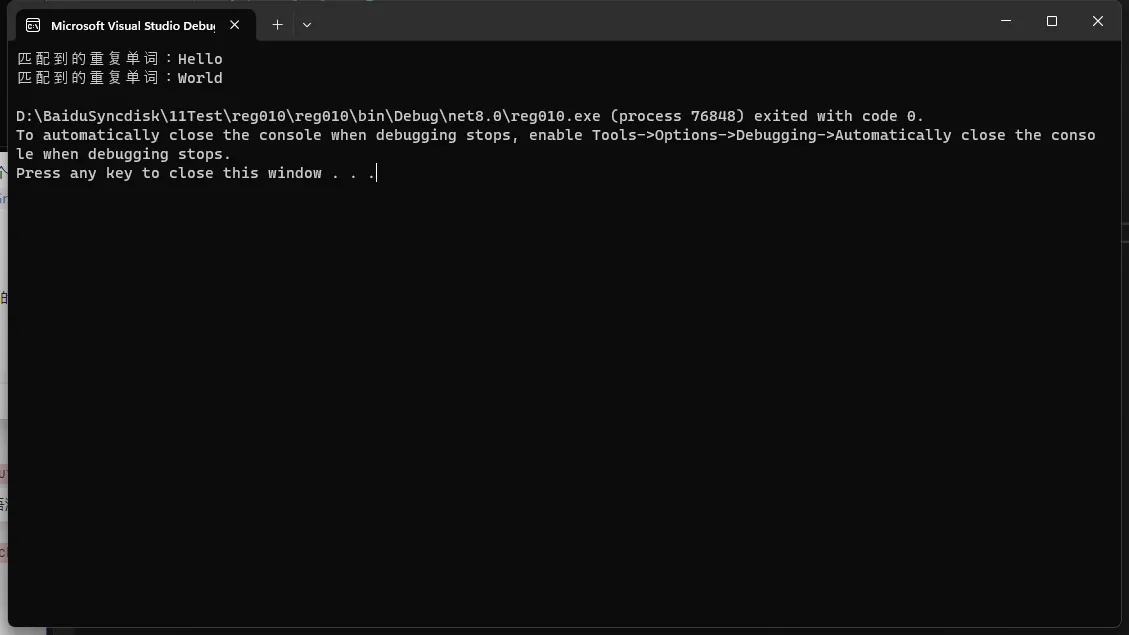
在这个示例中,正则表达式 (\w+)\s\1 使用 \1 来引用第一个捕获组匹配到的单词,这样就可以匹配重复的单词对。
示例 3:替换重复的字符
C#string pattern = @"(\w)\1";
string input = "Boookkeeper";
string result = Regex.Replace(input, pattern, "$1");
Console.WriteLine(result);
输出:
C#Bookeper
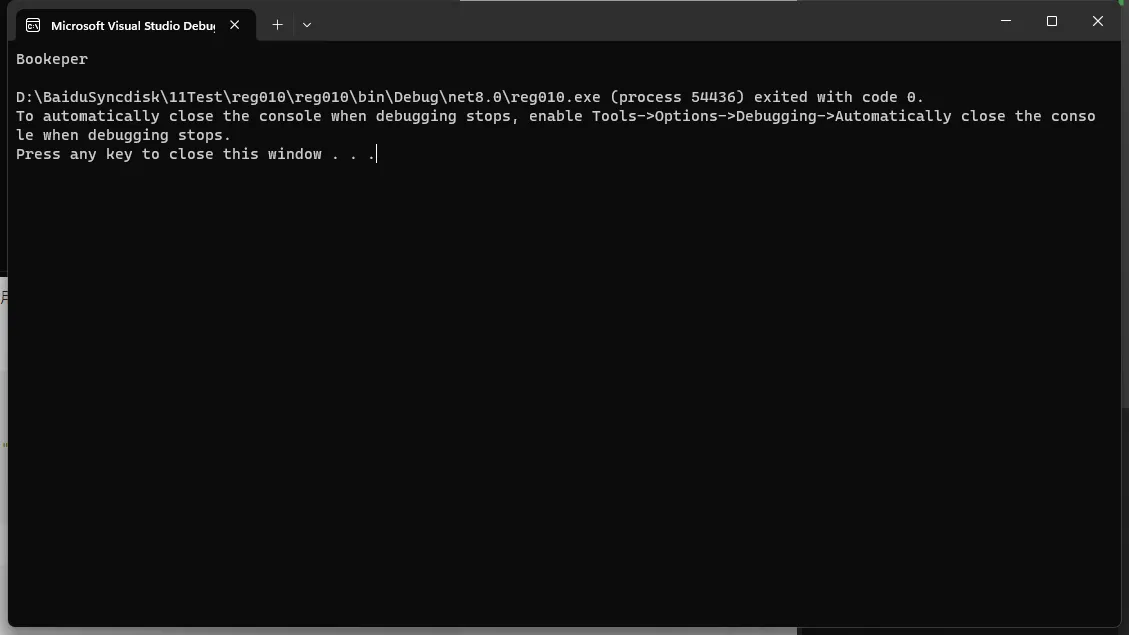
在这个示例中,正则表达式 (\w)\1 匹配相邻的重复字符。Regex.Replace 方法使用 $1(捕获组的引用)来替换匹配到的文本,从而删除重复的字符。
示例 4:匹配成对的标签
C#string pattern = @"<(\w+)>(.*?)</\1>";
string input = "<b>粗体文本</b> <i>斜体文本</i>";
MatchCollection matches = Regex.Matches(input, pattern);
foreach (Match match in matches)
{
Console.WriteLine($"匹配到的标签:{match.Groups[1].Value}");
Console.WriteLine($"标签内的文本:{match.Groups[2].Value}");
}
输出:
C#匹配到的标签:b 标签内的文本:粗体文本 匹配到的标签:i 标签内的文本:斜体文本
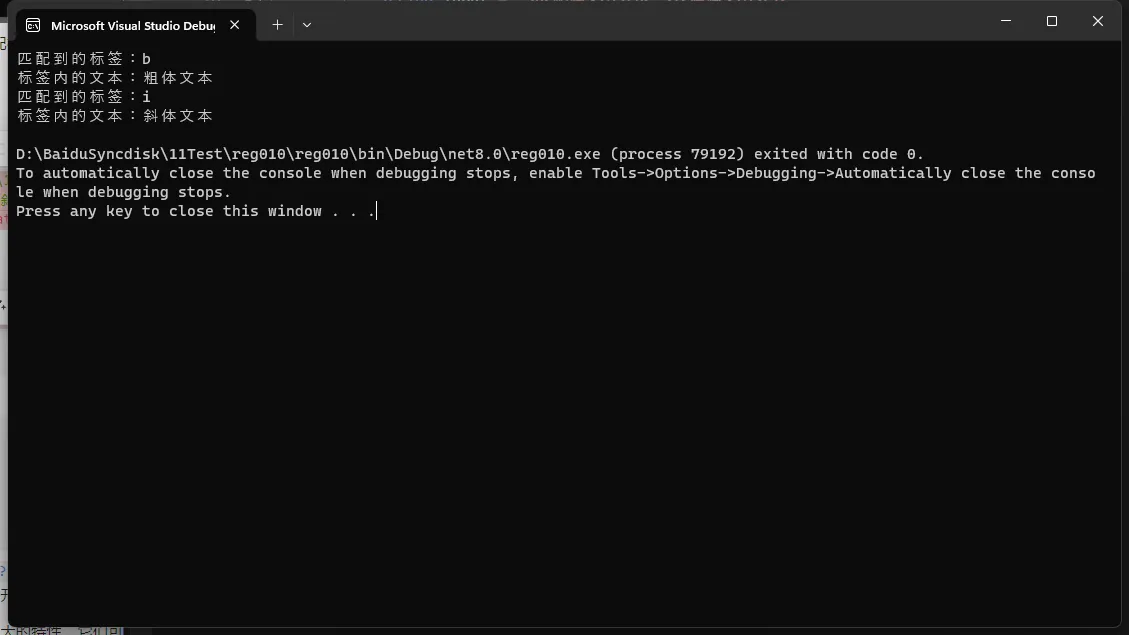
在这个示例中,正则表达式 <(\w+)>(.*?)</\1> 匹配成对的HTML标签。第一个捕获组 (\w+) 匹配标签名,而 \1 用于反向引用这个标签名,确保结束标签与开始标签相匹配。第二个捕获组 (.*?) 以非贪婪模式匹配标签内的任意文本。
捕获组和反向引用是正则表达式中非常强大的特性,它们可以极大地提高你在文本处理中的灵活性和效率。通过这些示例,你可以开始在自己的C#项目中使用这些工具来解决复杂的文本处理问题。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!