目录
摘要
HTMLAgilityPack 是一个开源的.NET库,旨在帮助开发人员处理和操作HTML文档。它提供了解析HTML文档、查询DOM元素以及修改HTML内容的功能。HTMLAgilityPack 基于XPath和LINQ查询,使得开发者能够以类似于操作XML文档的方式来操作HTML文档。这使得从复杂的HTML结构中提取所需数据变得轻而易举。
正文
HTMLAgilityPack 主要用于以下几个方面:
- 解析HTML文档:HTMLAgilityPack 可以将原始的HTML文档解析成一个DOM(文档对象模型)树,使开发者能够轻松地遍历和操作HTML元素。
- 查询和选择元素:通过使用XPath表达式或LINQ查询,您可以轻松地选择和定位HTML文档中的特定元素,从而实现数据的抽取和操作。
- 修改HTML内容:您可以使用HTMLAgilityPack来添加、删除或修改HTML元素和属性,以满足特定的需求。
- HTML格式化与转换:HTMLAgilityPack 还允许您将HTML文档格式化为漂亮的字符串或转换为其他格式,如纯文本或Markdown。
常用方法与学用属性
以下是一些常用的HTMLAgilityPack方法和属性,以及它们的用途:
- HtmlDocument.Load(string path):从指定路径加载HTML文档。
- HtmlDocument.LoadHtml(string html):从字符串加载HTML文档。
- HtmlDocument.DocumentNode:获取整个HTML文档的根节点。
- SelectSingleNode(string xpath):根据XPath表达式选择单个节点。
- SelectNodes(string xpath):根据XPath表达式选择多个节点。
- InnerText:获取或设置元素的文本内容。
- OuterHtml:获取或设置元素及其内部内容的HTML。
- Attributes:获取元素的属性集合。
- AppendChild(HtmlNode newChild):将新节点添加为子节点。
- Remove():从文档中移除当前节点。
Nuget安装 HtmlAgilityPack库
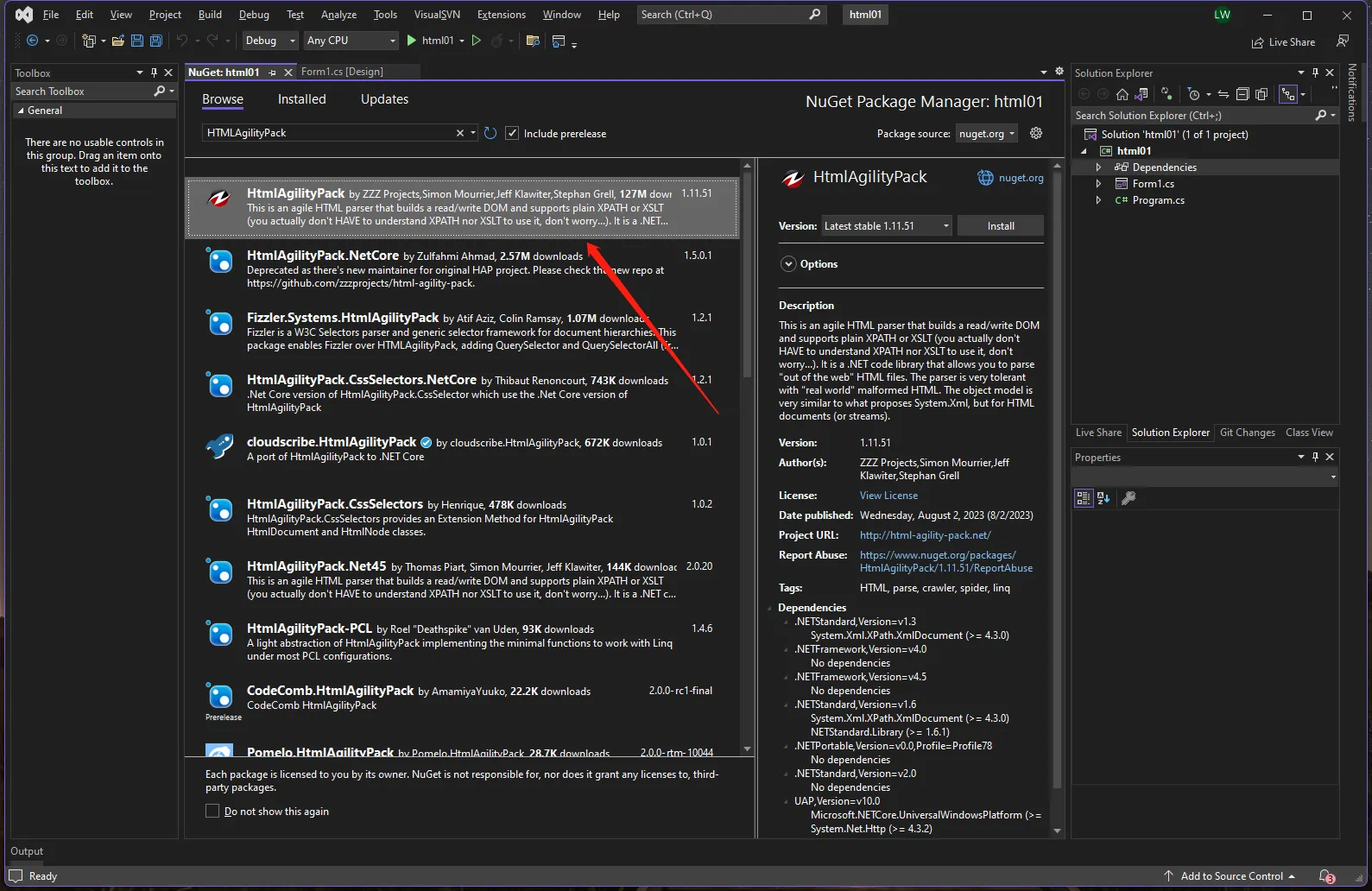
解析并显示标题
我们使用 HttpClient 发送一个 GET 请求到指定的 HTTPS URL,并且读取返回的响应内容。
如果出现 HTTP 状态码 403 (Forbidden) 错误表示您的请求被服务器拒绝,通常是因为服务器认为您没有权限访问该资源。
- 检查网站访问权限:确保您有权访问目标网站。有些网站可能需要登录或具有特定权限才能访问其内容。
- 用户代理头:有些网站要求用户代理标头,您可以尝试在请求中添加一个用户代理标头来模拟浏览器行为
- Cookies 和 Session:如果目标网站使用 cookies 或会话来管理访问权限,请确保您正确处理这些信息。您可能需要发送适当的 cookies 或会话信息以获取访问权限。
- IP封锁:某些网站可能根据 IP 地址阻止访问,如果您的 IP 被封锁,您可能需要使用代理服务器来绕过封锁。
- 代理服务器:如果您的网络中存在代理服务器,请确保代理服务器的设置正确,并且允许访问目标网站。
- 身份验证:如果网站需要身份验证,您可能需要在请求中包含适当的身份验证凭据。您可以使用
HttpClient的DefaultRequestHeaders.Authorization属性来添加身份验证标头。 - 请求头和参数:某些网站可能会要求特定的请求头或查询参数,您需要查看网站的文档或分析网络请求以确定所需的请求标头和参数。
C#private async void btnGetTitle_Click(object sender, EventArgs e)
{
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
string htmlContent = "";
using (HttpClient httpClient = new HttpClient())
{
try
{
httpClient.DefaultRequestHeaders.UserAgent.ParseAdd("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3");
HttpResponseMessage response = await httpClient.GetAsync("https://www.baidu.com");
//检查 HTTP 响应的状态码是否表示成功
response.EnsureSuccessStatusCode();
//读取内容
byte[] bytes = await response.Content.ReadAsByteArrayAsync();
htmlContent = Encoding.UTF8.GetString(bytes);
}
catch (HttpRequestException ex)
{
}
}
doc.LoadHtml(htmlContent);
HtmlNode titleNode = doc.DocumentNode.SelectSingleNode("//title");
if (titleNode != null)
{
string title = titleNode.InnerText;
MessageBox.Show($"页面标题:{title}");
}
}
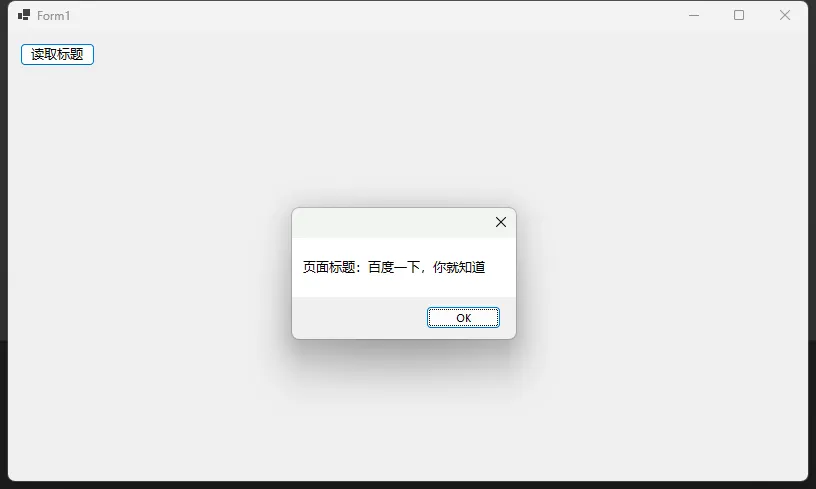
提取所有链接
C#/// <summary>
/// 通过url取得html内容
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
private async Task<string> GetHtml(string url)
{
string htmlContent = "";
using (HttpClient httpClient = new HttpClient())
{
try
{
httpClient.DefaultRequestHeaders.UserAgent.ParseAdd("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3");
HttpResponseMessage response = await httpClient.GetAsync(url);
response.EnsureSuccessStatusCode();
//读取内容
byte[] bytes = await response.Content.ReadAsByteArrayAsync();
htmlContent = Encoding.UTF8.GetString(bytes);
}
catch (HttpRequestException ex)
{
}
}
return htmlContent;
}
private async void btnGetLinks_Click(object sender, EventArgs e)
{
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
string htmlContent =await GetHtml("https://www.baidu.com");
doc.LoadHtml(htmlContent);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//a[@href]");
if (linkNodes != null)
{
foreach (HtmlNode linkNode in linkNodes)
{
string link = linkNode.GetAttributeValue("href", "");
lstLink.Items.Add(link);
}
}
}
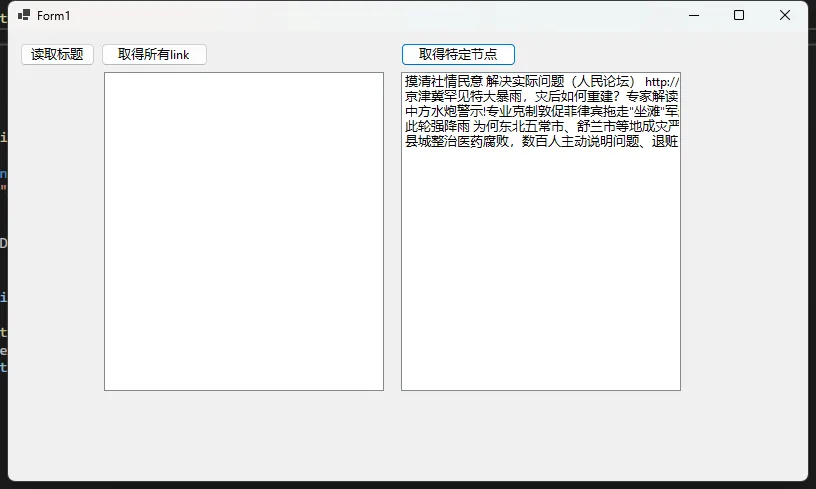
通过class 去找节点
C#private async void btnGetSpecialLink_Click(object sender, EventArgs e)
{
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
string htmlContent = await GetHtml("https://news.baidu.com/");
doc.LoadHtml(htmlContent);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//*[@id=\"pane-news\"]/ul/li[@class=\"bold-item\"]/a");
if (linkNodes != null)
{
foreach (HtmlNode linkNode in linkNodes)
{
string link = linkNode.GetAttributeValue("href", "");
string title = linkNode.InnerText;
lnkSpecialLink.Items.Add(title + " " + link);
}
}
}
快速找到节点path
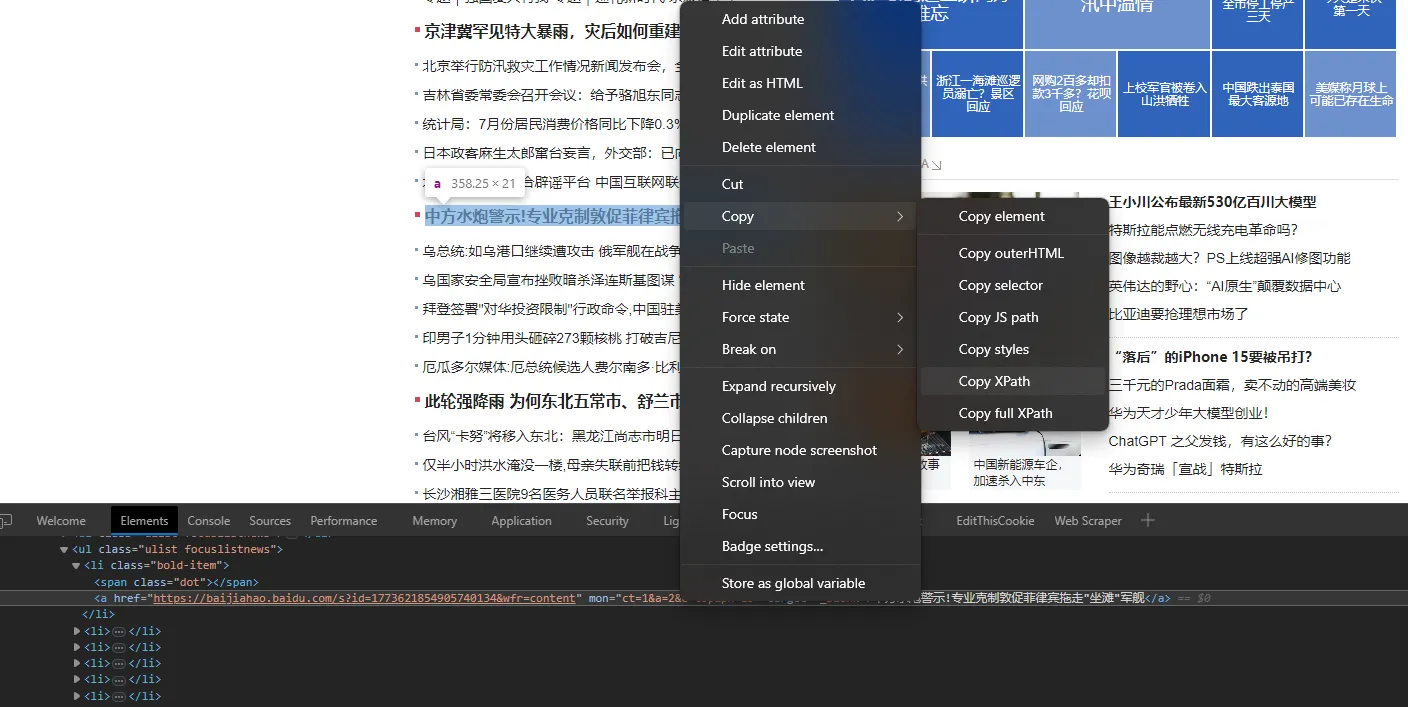
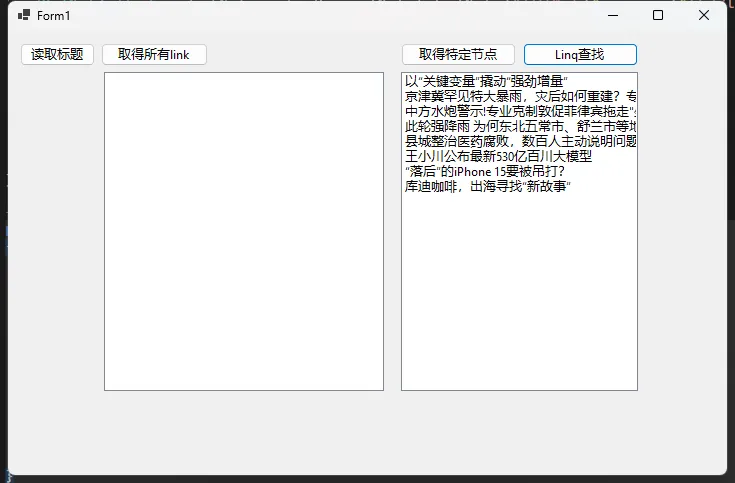
Linq 找查节点
C#private async void btnLinqSearch_Click(object sender, EventArgs e)
{
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
string htmlContent = await GetHtml("https://news.baidu.com/");
doc.LoadHtml(htmlContent);
IEnumerable<HtmlNode> linkNodes = doc.DocumentNode.Descendants("li")
.Where(div => div.Attributes["class"]?.Value.Contains("bold-item") == true);
foreach (HtmlNode linkNode in linkNodes)
{
string title = linkNode.InnerText;
lnkSpecialLink.Items.Add(title);
}
}
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录