目录
在Python开发中,字符串操作可以说是每个程序员的必修课。无论你是在开发Windows桌面应用、Web后端服务,还是数据分析项目,字符串处理都是绕不开的话题。很多初学者在面对Python丰富的字符串方法时常感到困惑:什么时候用split()?什么时候用partition()?strip()和lstrip()有什么区别?
本文将以实战的角度,系统梳理Python字符串的70多个核心方法,通过大量的代码示例和应用场景,帮你彻底掌握字符串操作的精髓。不再背诵枯燥的方法列表,而是真正理解每个方法的使用场景和最佳实践。
🔍 问题分析:为什么字符串操作如此重要?
在实际的Python开发项目中,字符串处理占据了相当大的比重:
- 数据清洗:处理CSV文件、日志分析时需要去除多余空格、分割字段
- 用户输入验证:检查邮箱格式、手机号码格式是否正确
- 文件路径处理:在Windows环境下处理文件路径和文件名
- API数据处理:解析JSON响应、格式化输出结果
- 配置文件解析:读取INI文件、环境变量配置
掌握字符串操作,就是掌握了Python开发的基础技能。
💡 解决方案:字符串方法分类解析
🔎 查找与判断类方法
这类方法主要用于查找字符串位置和判断字符串特征。
位置查找方法
Python# 实战场景:日志文件分析
log_line = "2024-01-15 10:30:45 ERROR: Database connection failed"
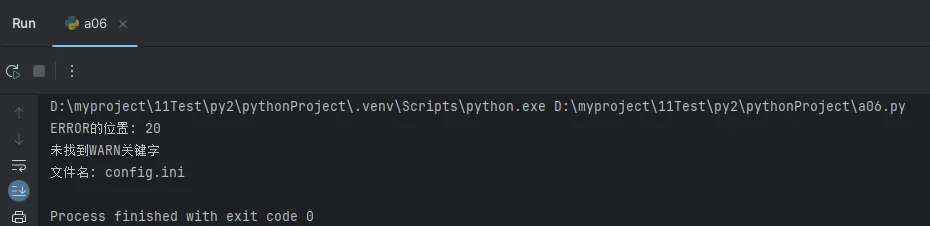
# find() vs index() 的区别
error_pos = log_line.find("ERROR") # 找不到返回-1
print("ERROR的位置:", error_pos)
try:
warn_pos = log_line.index("WARN") # 找不到会抛出ValueError异常
except ValueError:
print("未找到WARN关键字")
# 实用技巧:从右侧查找
file_path = "C:\\Project\\src\\main\\config.ini"
last_slash = file_path.rfind("\\") # 从右侧查找最后一个反斜杠
filename = file_path[last_slash + 1:] # 提取文件名
print(f"文件名: {filename}")
内容判断方法
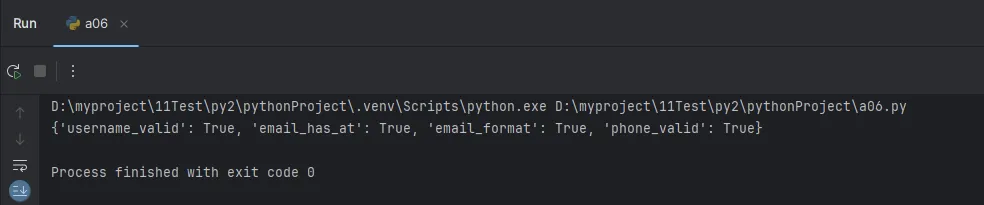
Python# 实战场景:用户输入验证
def validate_user_input(username, email, phone):
results = {}
# 用户名验证(只能包含字母数字)
results['username_valid'] = username.isalnum()
# 邮箱基础验证
results['email_has_at'] = '@' in email
results['email_format'] = email.count('@') == 1
# 手机号验证(假设只包含数字)
results['phone_valid'] = phone.isdigit() and len(phone) == 11
return results
# 测试
user_data = validate_user_input("user123", "test@email.com", "13812345678")
print(user_data)
✂️ 分割与连接类方法
这类方法是数据处理中最常用的操作。
字符串分割
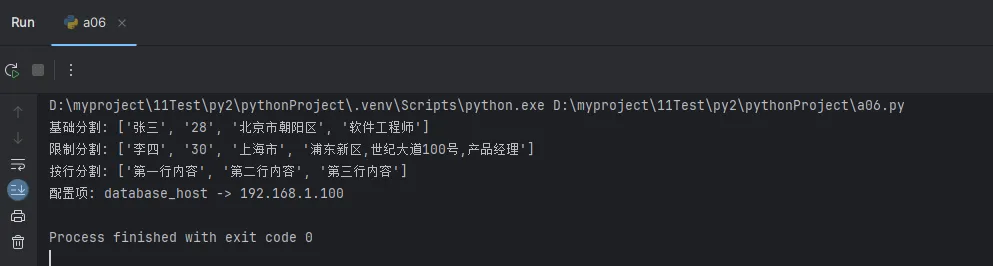
Python# 实战场景:CSV数据处理
csv_line = "张三,28,北京市朝阳区,软件工程师"
# 基础分割
fields = csv_line.split(",")
print("基础分割:", fields)
# 限制分割次数(处理包含逗号的地址)
csv_line2 = "李四,30,上海市,浦东新区,世纪大道100号,产品经理"
fields_limited = csv_line2.split(",", 3) # 只分割前3个逗号
print("限制分割:", fields_limited)
# 处理多行文本
text_block = """第一行内容
第二行内容
第三行内容"""
lines = text_block.splitlines()
print("按行分割:", lines)
# partition() 的妙用:解析键值对
config_line = "database_host=192.168.1.100"
key, separator, value = config_line.partition("=")
print(f"配置项: {key} -> {value}")
字符串连接
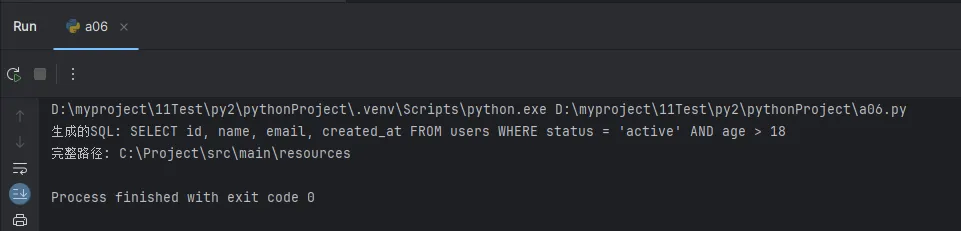
Python# 实战场景:动态SQL构建
def build_select_query(table, columns, conditions=None):
# 使用join()连接字段名
column_str = ", ".join(columns)
query = f"SELECT {column_str} FROM {table}"
if conditions:
# 连接WHERE条件
condition_str = " AND ".join(conditions)
query += f" WHERE {condition_str}"
return query
# 测试
columns = ["id", "name", "email", "created_at"]
conditions = ["status = 'active'", "age > 18"]
sql = build_select_query("users", columns, conditions)
print("生成的SQL:", sql)
# 路径连接的最佳实践
import os
base_path = "C:\\Project"
folders = ["src", "main", "resources"]
full_path = os.path.join(base_path, *folders) # 推荐使用os.path.join
# 或者使用字符串连接
full_path_str = base_path + "\\" + "\\".join(folders)
print("完整路径:", full_path)
🔄 替换与转换类方法
这类方法用于数据清洗和格式转换。
大小写转换
Python# 实战场景:统一数据格式
def normalize_data(raw_data):
"""标准化用户输入数据"""
normalized = {}
for key, value in raw_data.items():
if key == "email":
# 邮箱统一转小写
normalized[key] = value.lower().strip()
elif key == "name":
# 姓名首字母大写
normalized[key] = value.title().strip()
elif key == "department":
# 部门名称全大写
normalized[key] = value.upper().strip()
return normalized
# 测试数据
user_input = {
"email": " JOHN.DOE@COMPANY.COM ",
"name": "john doe",
"department": "it development"
}
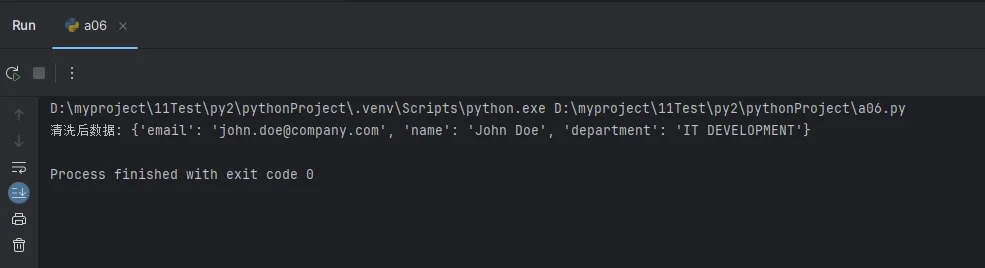
clean_data = normalize_data(user_input)
print("清洗后数据:", clean_data)
内容替换
Python# 实战场景:敏感信息脱敏
def mask_sensitive_info(text):
"""脱敏处理"""
# 手机号脱敏
import re
phone_pattern = r'(\d{3})\d{4}(\d{4})'
text = re.sub(phone_pattern, r'\1****\2', text)
return text
# 字符替换表的高级用法
def clean_filename(filename):
"""清理文件名中的非法字符"""
# 创建字符替换表
illegal_chars = '<>:"/\\|?*'
replace_table = str.maketrans(illegal_chars, '_' * len(illegal_chars))
clean_name = filename.translate(replace_table)
return clean_name
# 测试
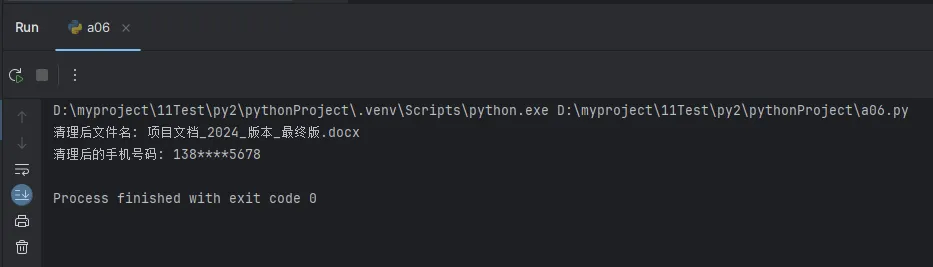
dirty_filename = "项目文档<2024>版本:最终版.docx"
clean_name = clean_filename(dirty_filename)
print("清理后文件名:", clean_name)
mobile_phone = "13812345678"
mobile_phone = mask_sensitive_info(mobile_phone)
print("清理后的手机号码:", mobile_phone)
🎨 格式化与填充类方法
这类方法主要用于输出格式化和数据展示。
去除空白字符
Python# 实战场景:用户输入清理
def clean_form_data(form_dict):
"""清理表单数据中的多余空白"""
cleaned = {}
for key, value in form_dict.items():
if isinstance(value, str):
# 去除首尾空白
cleaned_value = value.strip()
# 特殊处理:去除左侧的BOM标记
if key == "content":
cleaned_value = cleaned_value.lstrip('\ufeff')
cleaned[key] = cleaned_value
else:
cleaned[key] = value
return cleaned
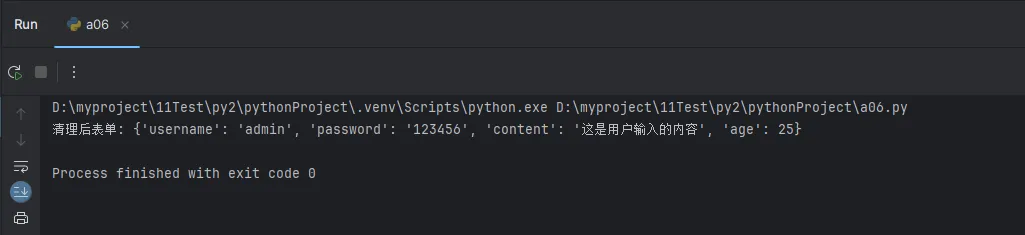
# 测试数据(模拟用户输入)
form_data = {
"username": " admin ",
"password": "123456 ",
"content": "\ufeff这是用户输入的内容 ",
"age": 25
}
clean_form = clean_form_data(form_data)
print("清理后表单:", clean_form)
对齐与填充
Python# 实战场景:生成报表
def generate_report(data):
"""生成对齐的数据报表"""
print("=" * 60)
print(f"{'姓名':<10} {'部门':<15} {'薪资':<10} {'入职日期':<15}")
print("=" * 60)
for record in data:
name = record['name'][:8] # 限制长度
dept = record['department'][:12]
salary = f"{record['salary']:,}" # 千分位格式
date = record['hire_date']
# 使用ljust进行左对齐
print(f"{name.ljust(10)} {dept.ljust(15)} {salary.rjust(10)} {date.ljust(15)}")
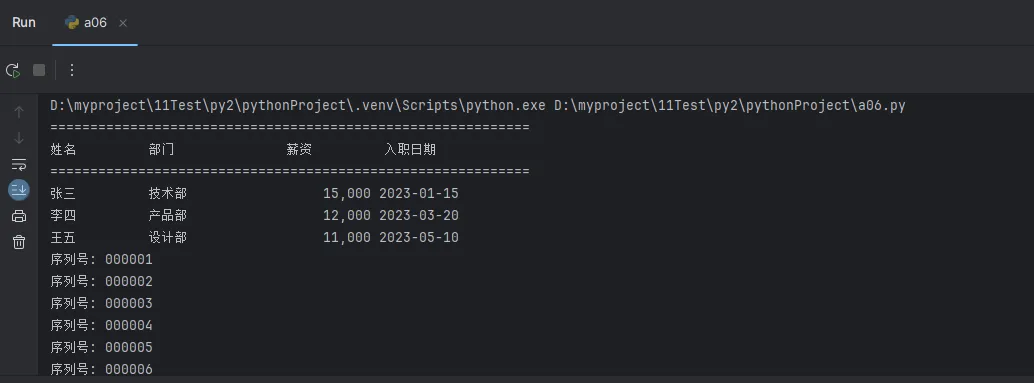
# 测试数据
employees = [
{"name": "张三", "department": "技术部", "salary": 15000, "hire_date": "2023-01-15"},
{"name": "李四", "department": "产品部", "salary": 12000, "hire_date": "2023-03-20"},
{"name": "王五", "department": "设计部", "salary": 11000, "hire_date": "2023-05-10"}
]
generate_report(employees)
# 数字填充的实用技巧
def format_serial_number(num, width=6):
"""格式化序列号"""
return str(num).zfill(width)
# 生成序列号
for i in range(1, 11):
serial = format_serial_number(i)
print(f"序列号: {serial}")
🛠️ 代码实战:综合应用案例
📁 案例一:日志文件分析器
Pythonclass LogAnalyzer:
"""日志文件分析器"""
def __init__(self, log_file_path):
self.log_file_path = log_file_path
self.error_count = 0
self.warning_count = 0
self.info_count = 0
def analyze_log(self):
"""分析日志文件"""
try:
with open(self.log_file_path, 'r', encoding='utf-8') as file:
for line_num, line in enumerate(file, 1):
line = line.strip() # 去除首尾空白
if not line: # 跳过空行
continue
# 提取日志级别
level = self._extract_log_level(line)
# 统计不同级别的日志
if level == "ERROR":
self.error_count += 1
self._process_error_log(line, line_num)
elif level == "WARN":
self.warning_count += 1
elif level == "INFO":
self.info_count += 1
except FileNotFoundError:
print(f"日志文件不存在: {self.log_file_path}")
except Exception as e:
print(f"分析日志时出错: {e}")
def _extract_log_level(self, line):
"""提取日志级别"""
# 假设日志格式:2024-01-15 10:30:45 ERROR: Database connection failed
if " ERROR:" in line:
return "ERROR"
elif " WARN:" in line:
return "WARN"
elif " INFO:" in line:
return "INFO"
return "UNKNOWN"
def _process_error_log(self, line, line_num):
"""处理错误日志"""
# 提取时间戳
parts = line.split(" ", 2)
if len(parts) >= 3:
date_part = parts[0]
time_part = parts[1]
message_part = parts[2]
# 提取错误消息(去除ERROR:前缀)
if "ERROR:" in message_part:
error_msg = message_part.split("ERROR:", 1)[1].strip()
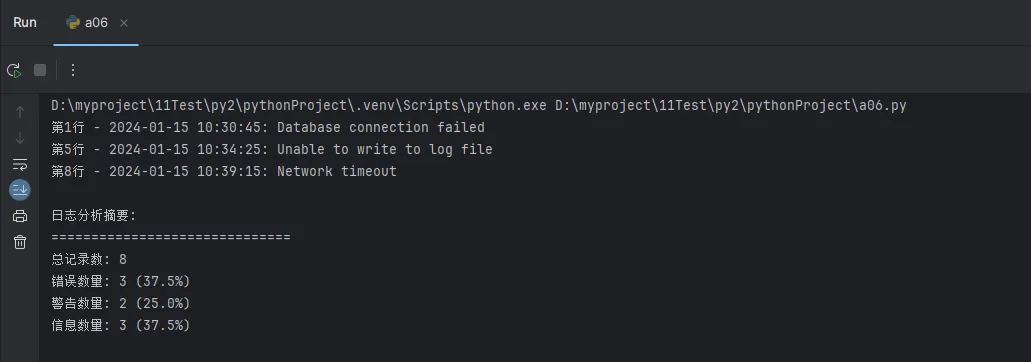
print(f"第{line_num}行 - {date_part} {time_part}: {error_msg}")
def get_summary(self):
"""获取分析摘要"""
total = self.error_count + self.warning_count + self.info_count
if total == 0:
return "没有找到有效的日志记录"
summary = f"""
日志分析摘要:
{'=' * 30}
总记录数: {total}
错误数量: {self.error_count} ({self.error_count / total * 100:.1f}%)
警告数量: {self.warning_count} ({self.warning_count / total * 100:.1f}%)
信息数量: {self.info_count} ({self.info_count / total * 100:.1f}%)
"""
return summary
# 使用示例
analyzer = LogAnalyzer("application.log")
analyzer.analyze_log()
print(analyzer.get_summary())
application.log
text2024-01-15 10:30:45 ERROR: Database connection failed 2024-01-15 10:31:00 INFO: Starting backup process 2024-01-15 10:32:10 WARN: Disk space low 2024-01-15 10:33:20 INFO: Backup completed successfully 2024-01-15 10:34:25 ERROR: Unable to write to log file 2024-01-15 10:35:50 WARN: User login attempt failed 2024-01-15 10:38:05 INFO: User logged out 2024-01-15 10:39:15 ERROR: Network timeout
🔐 案例二:配置文件解析器
Pythonclass ConfigParser:
"""简单的INI配置文件解析器"""
def __init__(self):
self.config_data = {}
def load_config(self, file_path):
"""加载配置文件"""
current_section = "DEFAULT"
try:
with open(file_path, 'r', encoding='utf-8') as file:
for line_num, line in enumerate(file, 1):
line = line.strip()
# 跳过空行和注释行
if not line or line.startswith('#') or line.startswith(';'):
continue
# 处理节标题 [section]
if line.startswith('[') and line.endswith(']'):
current_section = line[1:-1].strip()
if current_section not in self.config_data:
self.config_data[current_section] = {}
continue
# 处理键值对
if '=' in line:
key, value = line.split('=', 1) # 只分割第一个等号
key = key.strip()
value = value.strip()
# 去除值两边的引号
if (value.startswith('"') and value.endswith('"')) or \
(value.startswith("'") and value.endswith("'")):
value = value[1:-1]
# 确保当前节存在
if current_section not in self.config_data:
self.config_data[current_section] = {}
self.config_data[current_section][key] = value
except FileNotFoundError:
print(f"配置文件不存在: {file_path}")
except Exception as e:
print(f"解析配置文件时出错: {e}")
def get_value(self, section, key, default=None):
"""获取配置值"""
return self.config_data.get(section, {}).get(key, default)
def get_int(self, section, key, default=0):
"""获取整数配置值"""
value = self.get_value(section, key, str(default))
try:
return int(value)
except ValueError:
return default
def get_bool(self, section, key, default=False):
"""获取布尔配置值"""
value = self.get_value(section, key, str(default)).lower()
return value in ('true', '1', 'yes', 'on')
def print_config(self):
"""打印所有配置"""
for section, items in self.config_data.items():
print(f"[{section}]")
for key, value in items.items():
print(f"{key} = {value}")
print()
# 使用示例
config_content = """
# 数据库配置
[database]
host = "192.168.1.100"
port = 3306
username = admin
password = "secret123"
database = myapp
[app]
debug = true
log_level = INFO
max_connections = 100
"""
# 创建配置文件进行测试
with open("config.ini", "w", encoding="utf-8") as f:
f.write(config_content)
# 解析配置
parser = ConfigParser()
parser.load_config("config.ini")
# 获取配置值
db_host = parser.get_value("database", "host")
db_port = parser.get_int("database", "port")
debug_mode = parser.get_bool("app", "debug")
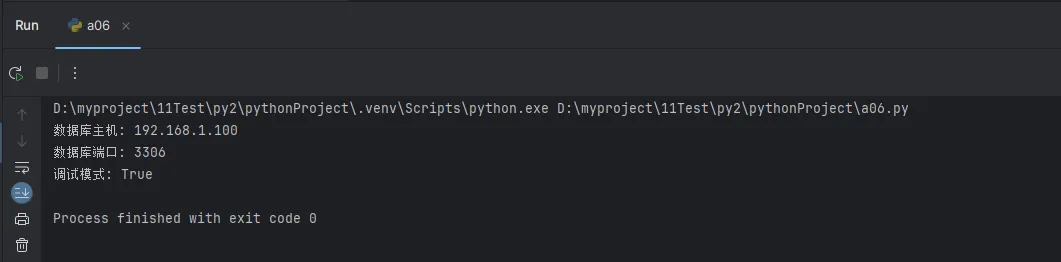
print(f"数据库主机: {db_host}")
print(f"数据库端口: {db_port}")
print(f"调试模式: {debug_mode}")
🎯 性能优化技巧
⚡ 字符串操作性能对比
Pythonimport time
def performance_test():
"""字符串操作性能测试"""
data = ["item" + str(i) for i in range(100000)]
# 方法1:使用 + 连接(性能较差)
start_time = time.time()
result1 = ""
for item in data:
result1 += item + ","
time1 = time.time() - start_time
# 方法2:使用 join() 连接(推荐)
start_time = time.time()
result2 = ",".join(data)
time2 = time.time() - start_time
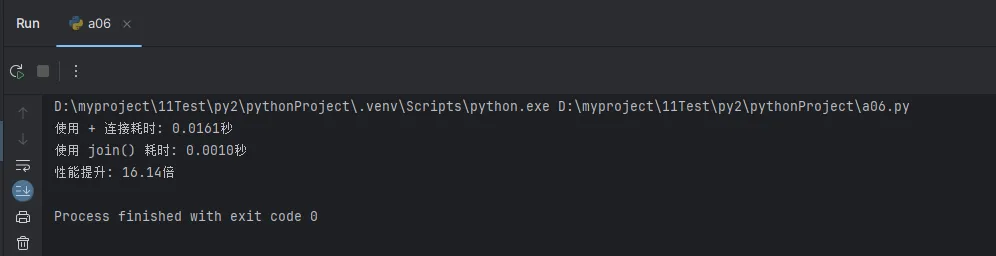
print(f"使用 + 连接耗时: {time1:.4f}秒")
print(f"使用 join() 耗时: {time2:.4f}秒")
print(f"性能提升: {time1 / time2:.2f}倍")
performance_test()
🔧 字符串处理最佳实践
Pythonclass StringUtils:
"""字符串工具类 - 最佳实践集合"""
@staticmethod
def safe_strip(text, chars=None):
"""安全的去除空白,处理None值"""
if text is None:
return ""
return str(text).strip(chars)
@staticmethod
def smart_split(text, delimiter=",", max_parts=None):
"""智能分割,自动处理空值和引号"""
if not text:
return []
# 处理CSV格式的引号
parts = []
current_part = ""
in_quotes = False
for char in text:
if char == '"':
in_quotes = not in_quotes
elif char == delimiter and not in_quotes:
parts.append(current_part.strip())
current_part = ""
if max_parts and len(parts) >= max_parts:
current_part = text[text.index(char) + 1:]
break
else:
current_part += char
if current_part:
parts.append(current_part.strip())
return parts
@staticmethod
def format_size(size_bytes):
"""格式化文件大小"""
if size_bytes == 0:
return "0 B"
size_names = ["B", "KB", "MB", "GB", "TB"]
import math
i = int(math.floor(math.log(size_bytes, 1024)))
p = math.pow(1024, i)
s = round(size_bytes / p, 2)
return f"{s} {size_names[i]}"
@staticmethod
def truncate_string(text, max_length, suffix="..."):
"""截断字符串并添加省略号"""
if len(text) <= max_length:
return text
return text[:max_length - len(suffix)] + suffix
# 使用示例
utils = StringUtils()
# 测试各种方法
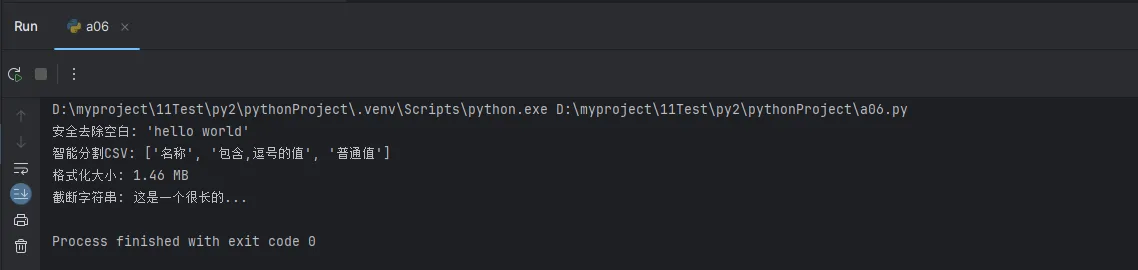
print("安全去除空白:", repr(utils.safe_strip(" hello world ")))
print("智能分割CSV:", utils.smart_split('名称,"包含,逗号的值",普通值'))
print("格式化大小:", utils.format_size(1536000))
print("截断字符串:", utils.truncate_string("这是一个很长的字符串内容", 10))
🎯 总结与提升
通过本文的深入讲解,我们系统掌握了Python字符串操作的三个核心要点:
1. 方法分类使用:将70多个字符串方法按功能分为查找判断、分割连接、替换转换、格式化填充四大类,每类都有其特定的使用场景和最佳实践。
2. 实战应用导向:通过日志分析器、配置文件解析器等实际项目案例,展示了如何将字符串方法组合使用,解决复杂的业务问题。
3. 性能优化意识:在处理大量字符串数据时,选择合适的方法至关重要。使用join()而不是+连接,使用strip()而不是正则表达式处理简单场景,这些细节决定了程序的运行效率。
掌握这些字符串操作技巧,不仅能让你的Python代码更加优雅高效,更能在数据处理、文件操作、用户交互等各个环节游刃有余。记住,优秀的程序员不是记住所有方法,而是知道在什么场景下使用什么方法。
延伸学习建议:建议深入学习正则表达式、文件编码处理、以及字符串国际化等高级主题,这将进一步提升你的Python开发水平。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!