目录
规范化是一种数据库设计技术,旨在将数据分解为更小的、更简单的关系,以消除冗余数据。通过将数据分解为多个表,并通过关系建立表之间的联系,可以有效地组织和管理数据。
规范化理论由爱德加·科德提出,并被广泛应用于关系型数据库设计中。它定义了一系列规则,用于确定如何将数据分解为不同的关系,并确保数据的一致性和完整性。
第一范式(1NF)
第一范式要求表中的每个字段都是原子的,不能再分解。此外,每个表都应该有一个唯一的主键。
实例数据表 - 未规范化
| OrderID | CustomerName | OrderDate | ProductName | Quantity | Price |
|---|---|---|---|---|---|
| 1 | John Doe | 2023-01-10 | Apple | 10 | 2.00 |
| 1 | John Doe | 2023-01-10 | Banana | 5 | 1.50 |
| 2 | Jane Smith | 2023-01-11 | Apple | 5 | 2.00 |
SQL-- 创建Orders表
CREATE TABLE Orders (
OrderID INT,
CustomerName NVARCHAR(100),
OrderDate DATE,
ProductName NVARCHAR(100),
Quantity INT,
Price DECIMAL(10, 2)
);
-- 插入数据到Orders表
INSERT INTO Orders (OrderID, CustomerName, OrderDate, ProductName, Quantity, Price) VALUES
(1, 'John Doe', '2023-01-10', 'Apple', 10, 2.00),
(1, 'John Doe', '2023-01-10', 'Banana', 5, 1.50),
(2, 'Jane Smith', '2023-01-11', 'Apple', 5, 2.00);
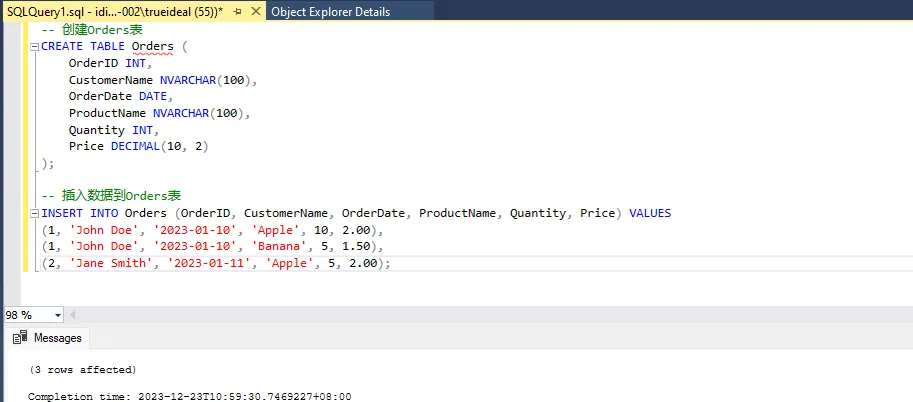 在这个未规范化的表中,
在这个未规范化的表中,OrderID 不是唯一的,且 ProductName、Quantity 和 Price 字段的组合可以进一步分解。
规范化到1NF
我们将上述表分解为两个表:Orders 和 OrderDetails。
Orders Table
| OrderID | CustomerName | OrderDate |
|---|---|---|
| 1 | John Doe | 2023-01-10 |
| 2 | Jane Smith | 2023-01-11 |
SQL-- 创建Orders 表
CREATE TABLE Orders (
OrderID INT,
CustomerName NVARCHAR(100),
OrderDate DATE
);
-- 插入数据到Orders 表
INSERT INTO Orders (OrderID, CustomerName, OrderDate) VALUES
(1, 'John Doe', '2023-01-10'),
(2, 'Jane Smith', '2023-01-11');
OrderDetails Table
| OrderDetailID | OrderID | ProductName | Quantity | Price |
|---|---|---|---|---|
| 1 | 1 | Apple | 10 | 2.00 |
| 2 | 1 | Banana | 5 | 1.50 |
| 3 | 2 | Apple | 5 | 2.00 |
SQL-- 创建OrderDetails表
CREATE TABLE OrderDetails (
OrderDetailID INT,
OrderID INT,
ProductName NVARCHAR(100),
Quantity INT,
Price DECIMAL(10, 2)
);
-- 插入数据到OrderDetails表
INSERT INTO OrderDetails (OrderDetailID, OrderID, ProductName, Quantity, Price) VALUES
(1, 1, 'Apple', 10, 2.00),
(2, 1, 'Banana', 5, 1.50),
(3, 2, 'Apple', 5, 2.00);
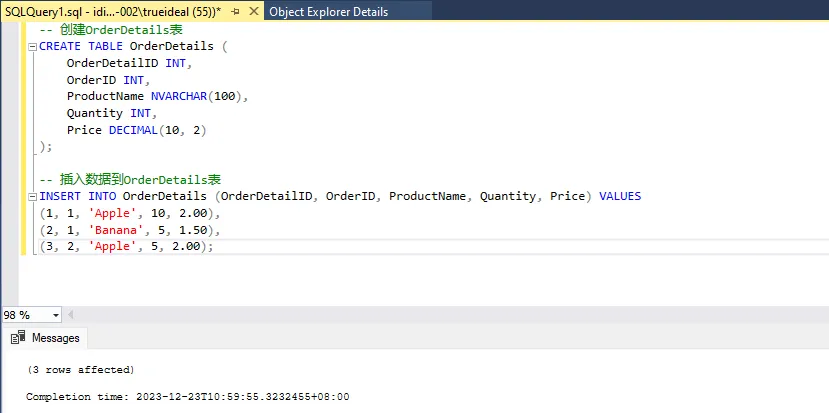
现在,Orders 表中的 OrderID 是唯一的,而 OrderDetails 表中的 OrderDetailID 是唯一的主键。
第二范式(2NF)
第二范式要求表达到1NF,并且所有非主键字段完全依赖于主键。
从1NF到2NF
在 OrderDetails 表中,ProductName、Quantity 和 Price 完全依赖于 OrderDetailID,但 Price 可能只依赖于 ProductName。为了达到2NF,我们需要将产品信息分离到单独的表中。
Products Table
| ProductID | ProductName | Price |
|---|---|---|
| 1 | Apple | 2.00 |
| 2 | Banana | 1.50 |
SQL-- 创建Products表
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName NVARCHAR(100),
Price DECIMAL(10, 2)
);
-- 插入数据到Products表
INSERT INTO Products (ProductID, ProductName, Price) VALUES
(1, 'Apple', 2.00),
(2, 'Banana', 1.50);
OrderDetails Table (Updated)
| OrderDetailID | OrderID | ProductID | Quantity |
|---|---|---|---|
| 1 | 1 | 1 | 10 |
| 2 | 1 | 2 | 5 |
| 3 | 2 | 1 | 5 |
SQL-- 创建 OrderDetails 表
CREATE TABLE OrderDetails (
OrderDetailID INT PRIMARY KEY,
OrderID INT,
ProductID INT,
Quantity INT
);
-- 插入数据到 OrderDetails 表
INSERT INTO OrderDetails (OrderDetailID, OrderID, ProductID, Quantity) VALUES
(1, 1, 1, 10),
(2, 1, 2, 5),
(3, 2, 1, 5);
在更新后的 OrderDetails 表中,所有非主键字段(ProductID 和 Quantity)都完全依赖于主键(OrderDetailID)。
第三范式(3NF)
第三范式要求表达到2NF,并且所有非主键字段直接依赖于主键,而不是通过另外一个非主键字段间接依赖。
从2NF到3NF
在 Orders 表中,CustomerName 可能并不直接依赖于 OrderID,而是依赖于客户的ID。因此,我们需要创建一个客户表来存储客户信息。
Customers Table
| CustomerID | CustomerName |
|---|---|
| 101 | John Doe |
| 102 | Jane Smith |
SQL-- 创建 Customers 表
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName NVARCHAR(255)
);
-- 插入数据到 Customers 表
INSERT INTO Customers (CustomerID, CustomerName) VALUES
(101, 'John Doe'),
(102, 'Jane Smith');
Orders Table (Updated)
| OrderID | CustomerID | OrderDate |
|---|---|---|
| 1 | 101 | 2023-01-10 |
| 2 | 102 | 2023-01-11 |
SQL-- 创建 Orders 表
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
OrderDate DATE
);
-- 插入数据到 Orders 表
INSERT INTO Orders (OrderID, CustomerID, OrderDate) VALUES
(1, 101, '2023-01-10'),
(2, 102, '2023-01-11');
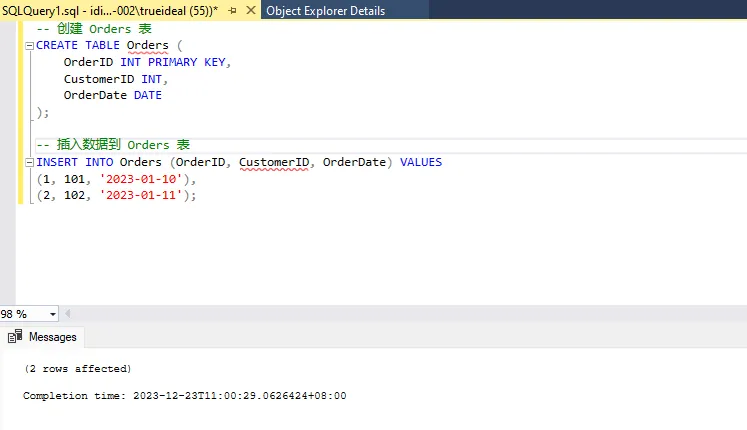
现在,Orders 表中的 CustomerName 被替换为 CustomerID,确保了所有非主键字段直接依赖于主键。
总结
规范化是数据库设计的一个重要环节,它有助于减少数据冗余,提高数据一致性,以及简化数据维护工作。在SQL Server中,通过逐步应用规范化理论的不同范式,可以创建出结构良好的数据库。然而,过度规范化可能导致性能下降,因此在实际应用中需要根据具体情况平衡规范化程度和性能需求。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!