目录
在Python开发过程中,循环语句是我们处理重复性任务的核心工具。无论是批量处理文件、数据分析还是Windows上位机开发,掌握for和while循环的精髓都能让你的代码效率倍增。
很多初学者在使用循环时容易陷入性能陷阱,或者不知道如何选择合适的循环方式。本文将从实战角度出发,通过具体的代码示例和最佳实践,帮你彻底掌握Python循环语句的核心技巧。我们将重点解决:如何选择合适的循环类型、如何优化循环性能、以及如何避免常见的循环陷阱。
🔍 问题分析:循环选择的困惑
📊 for vs while:何时使用哪种循环?
在Python开发中,新手经常面临这样的困惑:
- 已知循环次数时该用for还是while?
- 遍历数据结构时如何选择最优方案?
- 无限循环和条件循环的最佳实践是什么?
让我们通过对比分析来解决这些问题:
| 场景 | 推荐循环 | 理由 |
|---|---|---|
| 遍历序列/集合 | for | 代码简洁,自动处理索引 |
| 已知循环次数 | for + range() | 明确的循环边界 |
| 条件驱动循环 | while | 灵活的条件控制 |
| 无限循环 | while True | 清晰的意图表达 |
💡 解决方案:循环语句的核心原理
🏗️ for循环的内部机制
for循环在Python中是基于迭代器协议实现的,理解这一点对编程技巧提升至关重要。
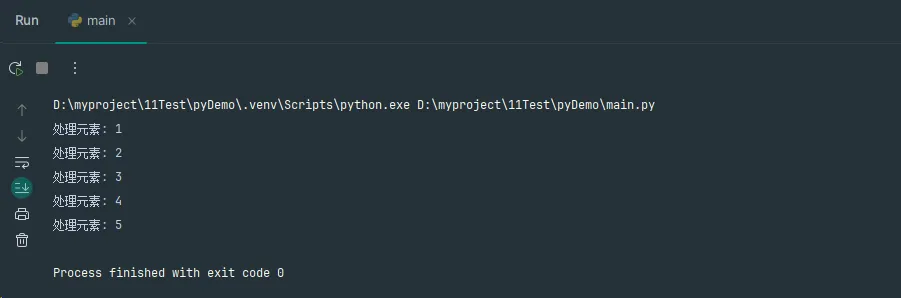
Python# for循环的本质原理
def simulate_for_loop(iterable):
"""模拟for循环的内部工作原理"""
iterator = iter(iterable) # 获取迭代器
while True:
try:
item = next(iterator) # 获取下一个元素
# 处理item的逻辑
print(f"处理元素: {item}")
except StopIteration:
break # 迭代结束
user=[1,2,3,4,5]
simulate_for_loop(user)
⚙️ while循环的控制策略
while循环的核心在于条件控制,掌握条件设计是关键:
Python# while循环的标准模式
def while_loop_patterns():
"""while循环的常用模式"""
# 模式1:计数器控制
count = 0
while count < 10:
print(f"计数: {count}")
count += 1 # 避免忘记更新条件
while_loop_patterns()
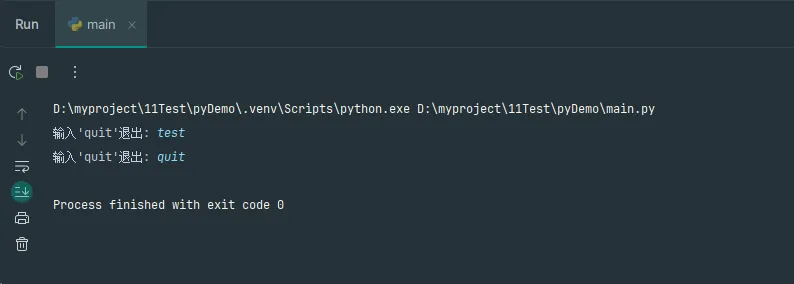
Python# while循环的标准模式
def while_loop_patterns():
"""while循环的常用模式"""
# 模式2:条件标志控制
is_running = True
while is_running:
user_input = input("输入'quit'退出: ")
if user_input.lower() == 'quit':
is_running = False
while_loop_patterns()
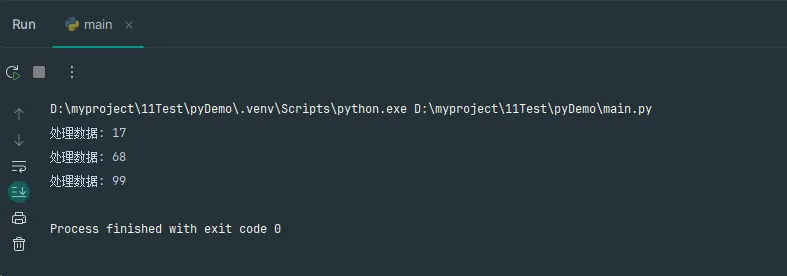
Pythonimport random
def get_data():
# 随机返回整数或None
if random.random() < 0.2: # 有20%的概率返回None作为哨兵值
return None
return random.randint(1, 100)
def process_data(data):
# 示例处理函数
print(f"处理数据: {data}")
def while_loop_patterns():
"""while循环的哨兵值控制标准模式"""
while True:
data = get_data()
if data is None: # 哨兵值
break
process_data(data)
while_loop_patterns()
🚀 代码实战:实际项目中的循环应用
📁 实战案例1:批量文件处理(Windows环境)
Pythonimport os
import time
from pathlib import Path
def batch_process_files(directory_path, file_extension='.txt'):
"""
批量处理指定目录下的文件
适用于Windows上位机开发中的日志文件处理
"""
directory = Path(directory_path)
# 使用for循环遍历文件
processed_count = 0
for file_path in directory.glob(f'*{file_extension}'):
try:
# 文件处理逻辑
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
# 假设进行某种处理
processed_content = content.upper()
# 写入处理后的文件
output_path = file_path.with_suffix('.processed' + file_extension)
with open(output_path, 'w', encoding='utf-8') as output_file:
output_file.write(processed_content)
processed_count += 1
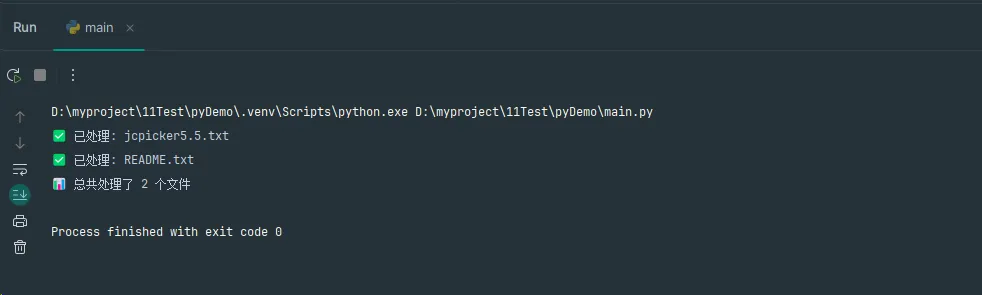
print(f"✅ 已处理: {file_path.name}")
except Exception as e:
print(f"❌ 处理失败 {file_path.name}: {e}")
print(f"📊 总共处理了 {processed_count} 个文件")
# 使用示例
if __name__ == "__main__":
batch_process_files(r"d:\software", ".txt") # 推荐方式
📡 实战案例2:数据采集与监控
Pythonimport time
import random
from datetime import datetime
class DataCollector:
"""数据采集器 - 适用于上位机监控系统"""
def __init__(self, max_samples=100):
self.data_buffer = []
self.max_samples = max_samples
self.is_collecting = False
def collect_sensor_data(self):
"""模拟传感器数据采集"""
# 模拟从硬件设备读取数据
temperature = round(random.uniform(20.0, 35.0), 2)
humidity = round(random.uniform(30.0, 80.0), 2)
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
return {
'timestamp': timestamp,
'temperature': temperature,
'humidity': humidity
}
def start_collection(self, interval=1.0):
"""开始数据采集 - 使用while循环实现持续监控"""
self.is_collecting = True
sample_count = 0
print("🔄 开始数据采集...")
while self.is_collecting and sample_count < self.max_samples:
try:
# 采集数据
data = self.collect_sensor_data()
self.data_buffer.append(data)
sample_count += 1
# 实时显示
print(f"📊 样本 {sample_count}: "
f"温度={data['temperature']}°C, "
f"湿度={data['humidity']}%")
# 检查异常条件
if data['temperature'] > 30.0:
print("⚠️ 温度过高警告!")
# 等待下次采集
time.sleep(interval)
except KeyboardInterrupt:
print("\n🛑 用户中断采集")
break
except Exception as e:
print(f"❌ 采集错误: {e}")
continue
self.is_collecting = False
print(f"✅ 采集完成,共收集 {len(self.data_buffer)} 个样本")
return self.data_buffer
# 使用示例
collector = DataCollector(max_samples=10)
data = collector.start_collection(interval=0.5)
🔧 实战案例3:循环优化技巧
Pythonimport time
from typing import List, Generator
def performance_comparison():
"""循环性能优化对比"""
# 测试数据
large_list = list(range(1000000))
# ❌ 低效方式:频繁的列表操作
def inefficient_loop():
result = []
start_time = time.time()
for i in range(len(large_list)):
if large_list[i] % 2 == 0:
result.append(large_list[i] * 2)
end_time = time.time()
return result, end_time - start_time
# ✅ 高效方式1:直接迭代
def efficient_loop_v1():
result = []
start_time = time.time()
for item in large_list:
if item % 2 == 0:
result.append(item * 2)
end_time = time.time()
return result, end_time - start_time
# ✅ 高效方式2:列表推导式
def efficient_loop_v2():
start_time = time.time()
result = [item * 2 for item in large_list if item % 2 == 0]
end_time = time.time()
return result, end_time - start_time
# ✅ 高效方式3:生成器(内存友好)
def efficient_generator():
def process_data() -> Generator[int, None, None]:
for item in large_list:
if item % 2 == 0:
yield item * 2
start_time = time.time()
result = list(process_data()) # 只有在需要时才转换为列表
end_time = time.time()
return result, end_time - start_time
# 性能测试
print("🏃♂️ 循环性能对比测试")
print("-" * 50)
methods = [
("低效循环", inefficient_loop),
("高效循环v1", efficient_loop_v1),
("列表推导式", efficient_loop_v2),
("生成器方式", efficient_generator)
]
for name, method in methods:
result, duration = method()
print(f"{name}: {duration:.4f}秒 (结果长度: {len(result)})")
# 运行性能测试
if __name__ == "__main__":
performance_comparison()
🎛️ 实战案例4:嵌套循环的优化
Pythondef optimize_nested_loops():
"""嵌套循环优化示例"""
# 模拟二维数据处理场景
matrix = [[random.randint(1, 100) for _ in range(100)] for _ in range(100)]
# ❌ 低效的嵌套循环
def inefficient_nested():
start_time = time.time()
result = []
for i in range(len(matrix)):
for j in range(len(matrix[i])):
if matrix[i][j] > 50:
result.append((i, j, matrix[i][j]))
return result, time.time() - start_time
# ✅ 优化的嵌套循环
def efficient_nested():
start_time = time.time()
result = []
for row_idx, row in enumerate(matrix):
for col_idx, value in enumerate(row):
if value > 50:
result.append((row_idx, col_idx, value))
return result, time.time() - start_time
# ✅ 更进一步的优化:使用列表推导式
def most_efficient():
start_time = time.time()
result = [(i, j, matrix[i][j])
for i, row in enumerate(matrix)
for j, value in enumerate(row)
if value > 50]
return result, time.time() - start_time
# 测试对比
print("🔄 嵌套循环优化对比")
print("-" * 40)
methods = [
("低效嵌套循环", inefficient_nested),
("优化嵌套循环", efficient_nested),
("列表推导式", most_efficient)
]
for name, method in methods:
result, duration = method()
print(f"{name}: {duration:.4f}秒 (找到 {len(result)} 个元素)")
🎯 高级技巧:循环语句的进阶应用
🔗 循环与异常处理的结合
Pythondef robust_loop_processing():
"""健壮的循环处理 - 带异常处理"""
urls = [
"https://api.example1.com/data",
"https://api.example2.com/data",
"invalid-url", # 故意的错误URL
"https://api.example3.com/data"
]
successful_requests = 0
failed_requests = 0
for index, url in enumerate(urls, 1):
try:
print(f"🔄 正在处理第 {index} 个URL: {url}")
# 模拟网络请求
if "invalid" in url:
raise ValueError("无效的URL格式")
# 模拟请求成功
time.sleep(0.1) # 模拟网络延迟
successful_requests += 1
print(f"✅ 成功处理: {url}")
except ValueError as e:
failed_requests += 1
print(f"❌ URL格式错误: {e}")
continue # 跳过当前循环,继续下一个
except Exception as e:
failed_requests += 1
print(f"❌ 处理失败: {e}")
# 根据错误类型决定是否继续
if "critical" in str(e).lower():
print("🚨 遇到严重错误,停止处理")
break
print(f"\n📊 处理统计: 成功 {successful_requests}, 失败 {failed_requests}")
🎮 循环控制的最佳实践
Pythondef loop_control_best_practices():
"""循环控制的最佳实践"""
# ✅ 使用else子句优化循环逻辑
def find_in_list_with_else():
numbers = [1, 3, 5, 7, 9, 2, 4, 6, 8]
target = 2
for num in numbers:
if num == target:
print(f"✅ 找到目标数字: {target}")
break
else:
# 只有在循环正常结束(没有break)时才执行
print(f"❌ 未找到目标数字: {target}")
# ✅ 合理使用continue优化逻辑
def process_with_continue():
data_list = [1, -2, 3, 0, -5, 7, 8, -1]
processed_count = 0
for item in data_list:
# 跳过负数和零
if item <= 0:
continue
# 处理正数
result = item ** 2
print(f"处理 {item} -> {result}")
processed_count += 1
print(f"共处理了 {processed_count} 个正数")
# ✅ 使用enumerate获取索引
def efficient_enumeration():
fruits = ['苹果', '香蕉', '橙子', '葡萄']
# 推荐方式
for index, fruit in enumerate(fruits, start=1):
print(f"{index}. {fruit}")
# 运行示例
print("🔍 查找示例:")
find_in_list_with_else()
print("\n⚡ Continue优化:")
process_with_continue()
print("\n📝 枚举示例:")
efficient_enumeration()
# 运行最佳实践示例
loop_control_best_practices()
🏆 结尾呼应
通过本文的深入分析和实战演练,我们掌握了Python循环语句的核心精髓。三个关键要点需要牢记:
🎯 选择合适的循环类型:for循环适合已知范围的迭代,while循环适合条件驱动的场景。理解迭代器协议和条件控制是关键。
⚡ 性能优化至关重要:避免不必要的索引访问,善用列表推导式和生成器,合理处理嵌套循环。在Windows上位机开发中,这些优化技巧能显著提升应用响应速度。
🛡️ 健壮性设计不可忽视:结合异常处理机制,使用else子句和continue语句优化控制流程,让你的Python代码在面对复杂业务场景时更加稳定可靠。
掌握这些循环语句的实战技巧,不仅能让你的Python开发效率倍增,更能在实际项目中写出高质量、高性能的代码。记住,优秀的代码不仅要功能正确,更要性能卓越、易于维护。
💡 想了解更多Python开发技巧?关注我们获取更多实战教程和最佳实践分享!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!