
Press Ctrl+ and K to search
目录
在Python开发中,经常会遇到需要处理重复数据、进行集合运算或快速判断元素是否存在的场景。比如在上位机开发中处理传感器数据去重,或者在数据分析时需要找出两个数据集的交集、并集等。今天我们就来深入探讨Python集合(set)的强大功能,从基础概念到实战应用,让你彻底掌握这个高效的数据结构。无论你是刚接触Python编程技巧的新手,还是想要提升代码性能的开发者,这篇文章都将为你提供实用的解决方案。
🎯 什么是Python集合?为什么要用它?
问题分析
在实际Python开发中,我们经常遇到以下问题:
- 列表中有大量重复数据需要去重
- 需要快速判断某个元素是否存在于大量数据中
- 要对两个数据集进行交集、并集、差集运算
- 需要一个高性能的数据结构来存储唯一值
解决方案
Python的集合(set)正是为解决这些问题而生的数据结构,它具有以下特点:
- 唯一性:自动去除重复元素
- 无序性:元素没有固定顺序
- 可变性:可以动态添加和删除元素
- 高效性:查找、添加、删除操作的时间复杂度都是O(1)
🔥 集合的创建与基本操作
创建集合的多种方式
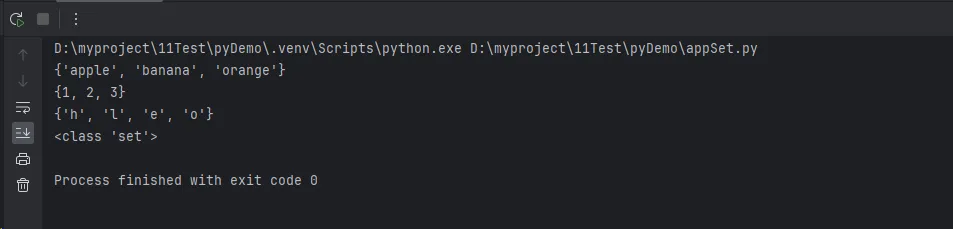
Python# 方式1:使用花括号创建
fruits = {'apple', 'banana', 'orange', 'apple'} # 重复的'apple'会被自动去除
print(fruits)
# 方式2:使用set()函数
numbers = set([1, 2, 3, 2, 1])
print(numbers) # {1, 2, 3}
# 方式3:从字符串创建
chars = set('hello')
print(chars)
# 方式4:创建空集合(注意不能用{},那是字典)
empty_set = set()
print(type(empty_set))
基本操作方法
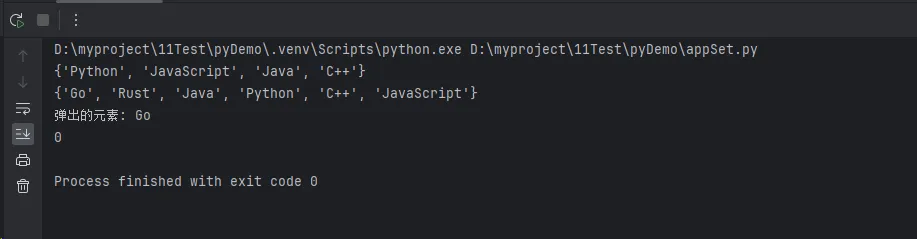
Python# 创建一个示例集合
tech_stack = {'Python', 'Java', 'JavaScript'}
# 添加元素
tech_stack.add('C++')
print(tech_stack)
# 添加多个元素
tech_stack.update(['Go', 'Rust'])
print(tech_stack)
# 删除元素
tech_stack.remove('Java')
tech_stack.discard('PHP')
# 弹出随机元素
popped = tech_stack.pop()
print(f"弹出的元素: {popped}")
# 清空集合
tech_stack.clear()
print(len(tech_stack))
💡 集合运算:交集、并集、差集实战
实战场景:用户权限管理系统
假设我们在开发一个上位机系统,需要管理不同用户的权限:
Python# 定义不同角色的权限
admin_permissions = {'read', 'write', 'delete', 'execute', 'modify'}
user_permissions = {'read', 'write'}
guest_permissions = {'read'}
# 当前登录用户的权限
current_user_permissions = {'read', 'write', 'modify'}
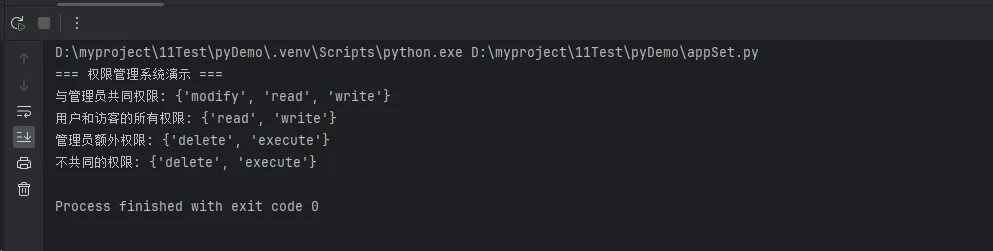
print("=== 权限管理系统演示 ===")
# 1. 交集运算:找出当前用户与管理员的共同权限
common_with_admin = current_user_permissions & admin_permissions
# 或者使用方法:current_user_permissions.intersection(admin_permissions)
print(f"与管理员共同权限: {common_with_admin}")
# 2. 并集运算:合并用户和访客的所有权限
all_permissions = user_permissions | guest_permissions
# 或者使用方法:user_permissions.union(guest_permissions)
print(f"用户和访客的所有权限: {all_permissions}")
# 3. 差集运算:找出管理员比当前用户多的权限
admin_extra = admin_permissions - current_user_permissions
# 或者使用方法:admin_permissions.difference(current_user_permissions)
print(f"管理员额外权限: {admin_extra}")
# 4. 对称差集:找出两个集合中不共同的权限
unique_permissions = admin_permissions ^ current_user_permissions
# 或者使用方法:admin_permissions.symmetric_difference(current_user_permissions)
print(f"不共同的权限: {unique_permissions}")
🚀 高级应用:集合推导式与性能优化
集合推导式让代码更Pythonic
Python# 传统方式:找出1-100中所有平方数
squares_traditional = set()
for i in range(1, 11):
squares_traditional.add(i**2)
# 集合推导式:一行代码搞定
squares_comprehension = {i**2 for i in range(1, 11)}
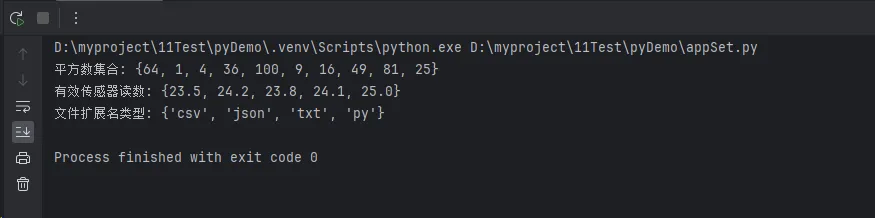
print(f"平方数集合: {squares_comprehension}")
# 实战应用:从数据中筛选有效值
sensor_data = [23.5, 24.1, -999, 25.0, -999, 23.8, 24.2]
valid_readings = {reading for reading in sensor_data if reading > 0}
print(f"有效传感器读数: {valid_readings}")
# 高级筛选:提取文件名中的扩展名
filenames = ['data.csv', 'config.json', 'log.txt', 'backup.csv', 'script.py']
extensions = {filename.split('.')[-1] for filename in filenames}
print(f"文件扩展名类型: {extensions}")
性能对比:集合 vs 列表
Pythonimport time
# 创建大量测试数据
large_list = list(range(100000000))
large_set = set(range(100000000))
target = 99999
# 测试列表查找性能
start_time = time.time()
result_list = target in large_list
list_time = time.time() - start_time
# 测试集合查找性能
start_time = time.time()
result_set = target in large_set
set_time = time.time() - start_time
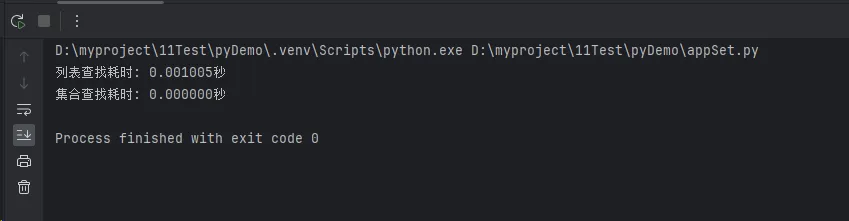
print(f"列表查找耗时: {list_time:.6f}秒")
print(f"集合查找耗时: {set_time:.6f}秒")
🛠️ 实战项目:数据清洗与分析工具
让我们用集合操作来解决一个实际的数据处理问题:
Pythonclass DataAnalyzer:
"""数据分析工具类,使用集合优化性能"""
def __init__(self):
self.processed_ids = set() # 已处理的数据ID
self.error_codes = set() # 错误代码集合
def remove_duplicates(self, data_list):
"""快速去重,保持原始顺序"""
seen = set()
result = []
for item in data_list:
if item not in seen:
seen.add(item)
result.append(item)
return result
def find_common_issues(self, *error_logs):
"""找出多个错误日志的共同问题"""
if not error_logs:
return set()
common_errors = set(error_logs[0])
for log in error_logs[1:]:
common_errors &= set(log)
return common_errors
def analyze_data_quality(self, dataset1, dataset2):
"""分析两个数据集的质量差异"""
set1, set2 = set(dataset1), set(dataset2)
analysis = {
'common_values': set1 & set2, # 共同值
'unique_to_set1': set1 - set2, # 仅在数据集1中
'unique_to_set2': set2 - set1, # 仅在数据集2中
'total_unique': set1 | set2, # 所有唯一值
'jaccard_similarity': len(set1 & set2) / len(set1 | set2) # 相似度
}
return analysis
# 实际应用示例
analyzer = DataAnalyzer()
# 传感器数据去重
sensor_readings = [23.1, 24.5, 23.1, 25.0, 24.5, 23.8, 25.0]
clean_readings = analyzer.remove_duplicates(sensor_readings)
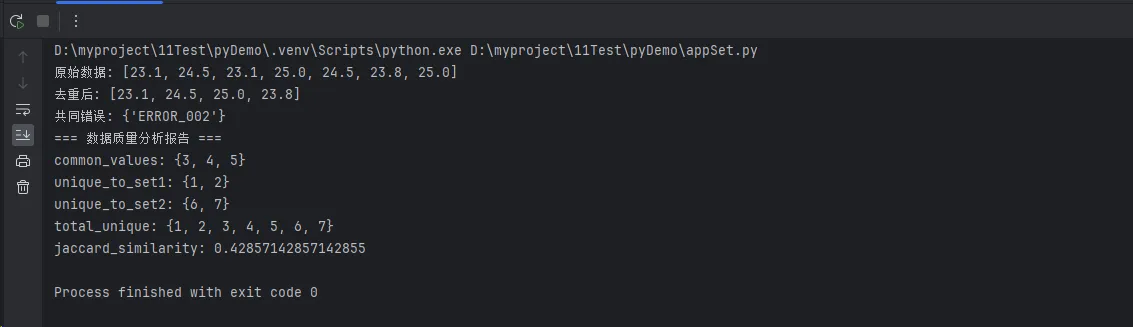
print(f"原始数据: {sensor_readings}")
print(f"去重后: {clean_readings}")
# 错误日志分析
log1 = ['ERROR_001', 'ERROR_002', 'ERROR_003']
log2 = ['ERROR_002', 'ERROR_003', 'ERROR_004']
log3 = ['ERROR_001', 'ERROR_002', 'ERROR_005']
common_errors = analyzer.find_common_issues(log1, log2, log3)
print(f"共同错误: {common_errors}")
# 数据质量分析
dataset_a = [1, 2, 3, 4, 5]
dataset_b = [3, 4, 5, 6, 7]
quality_report = analyzer.analyze_data_quality(dataset_a, dataset_b)
print("=== 数据质量分析报告 ===")
for key, value in quality_report.items():
print(f"{key}: {value}")
🔧 常见陷阱与最佳实践
避免常见错误
Python# 错误:试图创建包含列表的集合
try:
bad_set = {[1, 2], [3, 4]} # 列表不可哈希,会报错
except TypeError as e:
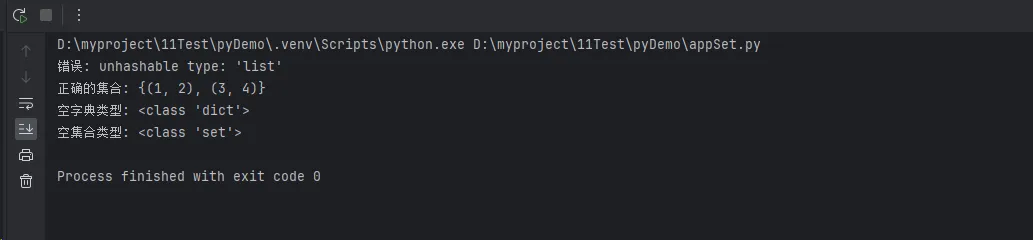
print(f"错误: {e}")
# 正确:使用元组替代列表
good_set = {(1, 2), (3, 4)}
print(f"正确的集合: {good_set}")
# 错误:使用{}创建空集合
empty_dict = {} # 这是字典,这个让人郁闷
empty_set = set() # 这才是空集合
# 正确:集合与字典的区别
print(f"空字典类型: {type(empty_dict)}")
print(f"空集合类型: {type(empty_set)}")
性能优化技巧
Python# 技巧1:使用集合快速判断成员资格
valid_status_codes = {200, 201, 204, 301, 302, 304}
def is_success_code(code):
return code in valid_status_codes # O(1)时间复杂度
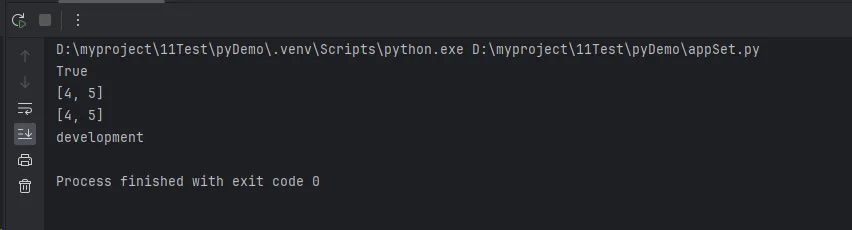
print(is_success_code(200))
# 技巧2:使用集合操作替代循环
def find_common_elements_slow(list1, list2):
"""慢速版本:使用嵌套循环"""
common = []
for item1 in list1:
for item2 in list2:
if item1 == item2 and item1 not in common:
common.append(item1)
return common
print(find_common_elements_slow([1, 2, 3, 4, 5], [4, 5, 6, 7, 8]))
def find_common_elements_fast(list1, list2):
"""快速版本:使用集合交集"""
return list(set(list1) & set(list2))
print(find_common_elements_fast([1, 2, 3, 4, 5], [4, 5, 6, 7, 8]))
# 技巧3:冻结集合(frozenset)用作字典键
config_combinations = {
frozenset(['debug', 'verbose']): 'development',
frozenset(['optimize', 'release']): 'production'
}
print(config_combinations[frozenset(['debug', 'verbose'])])
📊 集合与其他数据结构的选择指南
| 场景 | 推荐数据结构 | 原因 |
|---|---|---|
| 需要去重 | set | 自动去重,O(1)查找 |
| 需要保持顺序 | list | 有序,支持索引 |
| 需要映射关系 | dict | 键值对存储 |
| 需要不可变集合 | frozenset | 可作为字典键 |
| 频繁查找操作 | set | 最快的查找速度 |
🎯 总结:掌握集合操作的三个关键点
通过这篇文章的深入探讨,我们全面了解了Python集合操作的方方面面。让我们来总结三个最重要的要点:
1. 性能优势明显:集合的查找、添加、删除操作都是O(1)时间复杂度,在处理大量数据时比列表快数百倍。这在上位机开发和数据处理场景中尤为重要。
2. 集合运算强大:交集、并集、差集、对称差集等运算让复杂的数据分析变得简单直观。无论是权限管理、数据去重还是错误分析,集合运算都能提供优雅的解决方案。
3. 应用场景广泛:从简单的数据去重到复杂的数据质量分析,集合都能发挥重要作用。配合集合推导式,代码变得更加Pythonic和高效。
掌握这些Python编程技巧,不仅能让你的代码性能显著提升,还能让数据处理逻辑更加清晰。在实际项目中多加练习,你会发现集合操作是Python开发中不可或缺的利器。记住,好的代码不仅要功能正确,更要性能出色!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录