
Press Ctrl+ and K to search
目录
项目概述
本项目使用ML.NET构建一个预测性维护系统,通过机器学习模型预测设备故障风险。
Nuget 安装包
C#dotnet add package Microsoft.ML
SDCA(Stochastic Dual Coordinate Ascent)逻辑回归训练器
算法原理
SDCA(随机对偶坐标上升)算法
- 一种凸优化算法
- 专门用于处理大规模线性分类问题
- 计算效率高,适合高维特征数据
核心工作机制:
`1. 初始化模型参数
- 随机选择数据点
- 基于当前参数计算损失
- 更新模型参数
- 重复迭代,直到收敛或达到最大迭代次数`
算法特点
优点
- 计算复杂度低 O(nd)
- 内存使用效率高
- 适合稀疏数据
- 对大规模数据集表现良好
- 可解释性强
局限性
- 只适合线性可分问题
- 对非线性数据拟合能力较弱
- 需要特征工程
数据模型定义
此数据集包含模拟数据,表示对各种工业设备(包括涡轮机、压缩机和泵)的实时监控。数据集中的每一行都对应于一个捕获关键参数(如温度、压力、振动和湿度)的唯一观测值。该数据集还包括有关设备类型、位置以及设备是否被分类为故障的信息。
创建模型
C#using Microsoft.ML.Data;
namespace App14
{
public class EquipmentData
{
[LoadColumn(0)]
public float Temperature { get; set; }
[LoadColumn(1)]
public float Pressure { get; set; }
[LoadColumn(2)]
public float Vibration { get; set; }
[LoadColumn(3)]
public float Humidity { get; set; }
[LoadColumn(4)]
public string Equipment { get; set; }
[LoadColumn(5)]
public string Location { get; set; }
[LoadColumn(6)]
public float Faulty { get; set; }
}
}
预测结果类
C#using Microsoft.ML.Data;
namespace App14
{
// 预测模型
public class Prediction
{
[ColumnName("PredictedLabel")]
public bool IsFaulty { get; set; }
public float Probability { get; set; }
}
}
主程序入口
C#using Microsoft.ML;
using System.Reflection;
namespace App14
{
internal class Program
{
static void Main(string[] args)
{
var mlContext = new MLContext(seed: 0);
string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "equipment_anomaly_data.csv");
// 创建 MLContext
var context = new MLContext();
// 读取 CSV 文件
IDataView dataView = context.Data.LoadFromTextFile<EquipmentData>(_dataPath, separatorChar: ',', hasHeader: true);
// 数据预处理
var pipeline = mlContext.Transforms.Conversion.MapValue("Faulty",
new Dictionary<float, bool> {
{ 0.0f, false },
{ 1.0f, true }
})
.Append(mlContext.Transforms.Categorical.OneHotEncoding("Equipment"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding("Location"))
.Append(mlContext.Transforms.NormalizeMinMax("NormalizedTemperature", "Temperature"))
.Append(mlContext.Transforms.NormalizeMinMax("NormalizedPressure", "Pressure"))
.Append(mlContext.Transforms.NormalizeMinMax("NormalizedVibration", "Vibration"))
.Append(mlContext.Transforms.NormalizeMinMax("NormalizedHumidity", "Humidity"))
.Append(mlContext.Transforms.Concatenate("Features",
"Temperature", "Pressure", "Vibration", "Humidity",
"Equipment", "Location"));// 关键步骤:创建特征列
// 定义学习算法
var trainer = mlContext.BinaryClassification.Trainers
.SdcaLogisticRegression(labelColumnName: "Faulty", maximumNumberOfIterations: 100);
// 创建训练管道
var trainingPipeline = pipeline.Append(trainer);
// 训练模型
var model = trainingPipeline.Fit(dataView);
// 进行预测
var predictions = model.Transform(dataView);
var metrics = mlContext.BinaryClassification.Evaluate(predictions, labelColumnName: "Faulty");
// 输出评估指标
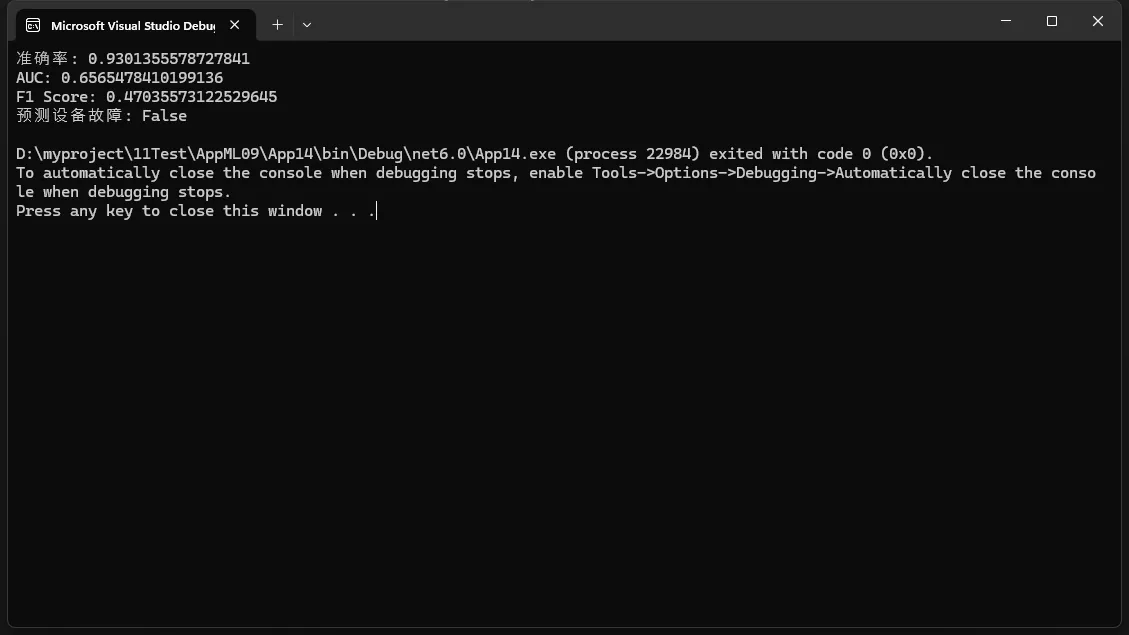
Console.WriteLine($"准确率: {metrics.Accuracy}");
Console.WriteLine($"AUC: {metrics.AreaUnderRocCurve}");
Console.WriteLine($"F1 Score: {metrics.F1Score}");
// 预测示例
var sampleData = new EquipmentData()
{
Temperature = 75,
Pressure = 30,
Vibration = 1,
Humidity = 55,
Equipment = "Compressor",
Location = "Chicago"
};
var predEngine = mlContext.Model.CreatePredictionEngine<EquipmentData, Prediction>(model);
var predictionResult = predEngine.Predict(sampleData);
Console.WriteLine($"预测设备故障: {predictionResult.IsFaulty}");
}
}
}
数据预处理管道详细解析
C#// 数据预处理管道详细解析
var pipeline = mlContext.Transforms.Conversion.MapValue("Faulty",
new Dictionary<float, bool> {
// 将数值型的故障标签转换为布尔类型
// 0.0f 映射为 false(正常)
// 1.0f 映射为 true(故障)
{ 0.0f, false },
{ 1.0f, true }
})
// 对类别型特征进行one-hot编码
// 将分类变量转换为机器学习算法可以处理的数值特征
.Append(mlContext.Transforms.Categorical.OneHotEncoding("Equipment"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding("Location"))
// 对数值型特征进行最小-最大归一化
// 将特征缩放到 [0,1] 区间,消除量纲差异,避免某些特征主导学习过程
.Append(mlContext.Transforms.NormalizeMinMax("NormalizedTemperature", "Temperature"))
.Append(mlContext.Transforms.NormalizeMinMax("NormalizedPressure", "Pressure"))
.Append(mlContext.Transforms.NormalizeMinMax("NormalizedVibration", "Vibration"))
.Append(mlContext.Transforms.NormalizeMinMax("NormalizedHumidity", "Humidity"))
// 将所有特征合并到一个特征向量中
// 机器学习算法通常需要一个统一的特征列进行训练
.Append(mlContext.Transforms.Concatenate("Features",
"Temperature", "Pressure", "Vibration", "Humidity",
"Equipment", "Location"));
- **标签转换 **
MapValue("Faulty")- 目的:将数值型的故障标签转换为布尔类型
- 原因:机器学习算法需要明确的布尔或数值类型标签
- 转换规则:
- 0.0f -> false(设备正常)
- 1.0f -> true(设备故障)
- 分类特征One-Hot编码
- 目的:将分类变量转换为数值特征
- 原理:
- 创建二进制特征向量
- 每个类别对应一个唯一的二进制编码
- 避免引入不合理的数值大小关系
- 示例:
- "Compressor" -> [1, 0, 0]
- "Pump" -> [0, 1, 0]
- "Turbine" -> [0, 0, 1]
- **特征归一化 **
NormalizeMinMax- 目的:统一特征尺度,消除量纲差异
- 转换公式:
X_normalized = (X - X_min) / (X_max - X_min) - 优点:
- 将所有特征缩放到 [0, 1] 区间
- 防止某些特征因数值大小主导学习过程
- 提高模型收敛速度和准确性
- **特征合并 **
Concatenate("Features")- 目的:创建统一的特征向量
- 原因:
- 大多数机器学习算法需要单一的特征列
- 将所有预处理后的特征组合成一个向量
- 结果:生成一个包含所有特征的一维数组
SdcaLogisticRegression参数详解
- labelColumnName: "Faulty"
- 指定标签列
- 告诉算法哪一列是分类的目标
- 必须是二值(0/1, true/false)
- maximumNumberOfIterations: 100
- 控制模型训练的最大迭代轮数
- 影响模型收敛和训练时间
- 值越大,模型可能越精确,但计算成本也越高
总结
这个示例展示了如何使用ML.NET构建一个简单的预测性维护模型。你可以根据实际数据集的特征和需求,调整模型和参数以提高预测性能。如果你有任何问题或需要进一步的帮助,请随时问我!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录