
目录
本文将结合最新的 NBA 球员多赛季数据(目前已包括 2017 至 2022 赛季),使用 ML.NET 来预测球员未来的潜力与表现趋势。通过此示例,您可以了解如何在 C# 环境中加载并预处理数据、构建模型,以及评估模型的预测准确度。
前言
- 数据简介
- 包含球员多个赛季(2017 年起至 2022 年)的人口统计信息(年龄、身高、体重、出生地等)。
- 包含球队信息(效力球队、选秀年份、轮次等)。
- 包含基础篮板、得分、助攻等盒子得分(STATS)统计。
- 数据质量已在多方面做了校验,包含对 52 行缺失值的填补,来自 Basketball Reference 等可信来源。
- 注意 2022 赛季有更新,数据相对完整,且可以把近些年的球员发展趋势纳入到模型中。
- 潜力评估方向
- 通过历史场均得分、篮板、助攻等关键指标,预测下一赛季的场均表现。
- 根据年龄、体重、身高等,结合已经获得的赛季综合表现,以回归、分类或排名方式评估球员发展潜力。
以下示例将展示如何使用 ML.NET 在 C# 项目中对球员未来场均得分(Points Per Game,简称 PPG)进行回归预测。
环境准备
安装 .NET 6.0 或更高版本
**创建控制台项目并引用 **ML.NET
textdotnet add package Microsoft.ML dotnet add package Microsoft.ML.FastTree
数据准备
假设我们有一个包含球员多赛季统计的 CSV 文件,名为 players_data.csv,其部分字段简化如下:
| PlayerName | Season | Age | Height | Weight | Team | DraftYear | Gp | Pts | Reb | Ast | ... |
|---|---|---|---|---|---|---|---|---|---|---|---|
| LeBron J. | 2022 | 36 | 206 | 113 | LAL | 2003 | 45 | 27.2 | 7.9 | 7.6 | ... |
| Stephen C. | 2022 | 34 | 188 | 84 | GSW | 2009 | 46 | 25.3 | 5.5 | 6.3 | ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
- PlayerName: 球员姓名 (string)
- Season: 赛季 (2022, 2021, …)
- Age/Height/Weight: 基本生理指标 (number)
- Team: 当前所属球队 (string)
- DraftYear: 选秀年份 (number)
- Gp: 出场次数 (number)
- Pts: 场均得分 (number)
- Reb: 场均篮板 (number)
- Ast: 场均助攻 (number)
- 其他统计列略…
目标:利用 Pts(场均得分)作为历史特征来预测下一赛季的场均得分。
当然也可以加入更多特征,例如过去三年的平均表现、球员的受伤记录、场均上场时间(MPG)等,增加模型的上下文信息。
实战步骤
定义数据模式
首先创建一个 C# 类,用于映射训练数据(特征和标签)。示例:
C#using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.ML.Data;
namespace AppNBA
{
public class PlayerData
{
[LoadColumn(0)]
public string player_name;
[LoadColumn(1)]
public string team_abbreviation;
[LoadColumn(2)]
public float age;
[LoadColumn(3)]
public float player_height;
[LoadColumn(4)]
public float player_weight;
[LoadColumn(5)]
public string college;
[LoadColumn(6)]
public string country;
[LoadColumn(7)]
public float draft_year;
[LoadColumn(8)]
public float draft_round;
[LoadColumn(9)]
public float draft_number;
[LoadColumn(10)]
public float gp;
[LoadColumn(11)]
public float pts;
[LoadColumn(12)]
public float reb;
[LoadColumn(13)]
public float ast;
[LoadColumn(14)]
public float net_rating;
[LoadColumn(15)]
public float oreb_pct;
[LoadColumn(16)]
public float dreb_pct;
[LoadColumn(17)]
public float usg_pct;
[LoadColumn(18)]
public float ts_pct;
[LoadColumn(19)]
public float ast_pct;
[LoadColumn(20)]
public string season;
}
}
LoadColumn属性指定了列在 CSV 文件中的索引,以便 ML.NET 正确地读取数据。- 若 CSV 的列顺序与示例不同,请相应调整
LoadColumn的参数。
预测结果类
C#using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.ML.Data;
namespace AppNBA
{
// 预测结果类
public class PlayerPrediction
{
[ColumnName("Score")]
public float pts;
}
}
完整代码
C#using Microsoft.ML;
using Microsoft.ML.Transforms;
namespace AppNBA
{
internal class Program
{
static void Main(string[] args)
{
// 创建 MLContext
var mlContext = new MLContext(seed: 0);
// 加载数据
IDataView dataView = mlContext.Data.LoadFromTextFile<PlayerData>("./data/players_data.csv",
hasHeader: true, separatorChar: ',');
// 在加载数据后添加这段代码来检查数据
var preview = dataView.Preview();
Console.WriteLine($"加载的行数: {preview.RowView.Length}");
foreach (var row in preview.RowView)
{
Console.WriteLine("Row:");
foreach (var col in row.Values)
{
Console.WriteLine($"\t{col.Key}: {col.Value}");
}
}
// 创建数据处理和训练管道
var pipeline = mlContext.Transforms.ReplaceMissingValues(
new[] {
"age", "player_height", "player_weight", "draft_year", "draft_round",
"draft_number", "gp", "pts", "reb", "ast", "net_rating", "oreb_pct",
"dreb_pct", "usg_pct", "ts_pct", "ast_pct"
}.Select(name => new InputOutputColumnPair(name, name)).ToArray())
.Append(mlContext.Transforms.CopyColumns(outputColumnName: "Label", inputColumnName: "pts"))
.Append(mlContext.Transforms.Concatenate("Features",
"age", "player_height", "player_weight", "draft_year", "draft_round",
"draft_number", "gp", "reb", "ast", "net_rating", "oreb_pct",
"dreb_pct", "usg_pct", "ts_pct", "ast_pct"))
.Append(mlContext.Transforms.NormalizeMinMax("Features"));
// 添加FastForest训练器
var trainer = mlContext.Regression.Trainers.FastForest(numberOfTrees: 100,
minimumExampleCountPerLeaf: 10);
var trainingPipeline = pipeline.Append(trainer);
// 分割数据为训练集和测试集
var trainTestData = mlContext.Data.TrainTestSplit(dataView, testFraction: 0.2);
// 训练模型
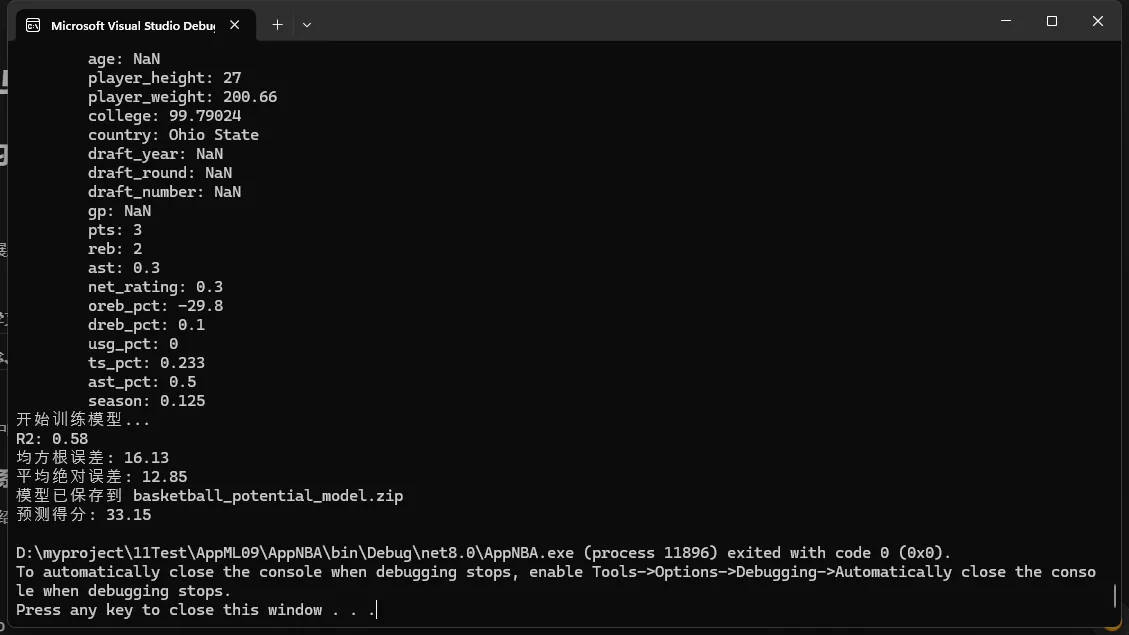
Console.WriteLine("开始训练模型...");
var model = trainingPipeline.Fit(trainTestData.TrainSet);
// 评估模型
var predictions = model.Transform(trainTestData.TestSet);
var metrics = mlContext.Regression.Evaluate(predictions);
Console.WriteLine($"R²: {metrics.RSquared:0.##}");
Console.WriteLine($"均方根误差: {metrics.RootMeanSquaredError:0.##}");
Console.WriteLine($"平均绝对误差: {metrics.MeanAbsoluteError:0.##}");
// 保存模型
mlContext.Model.Save(model, dataView.Schema, "basketball_potential_model.zip");
Console.WriteLine("模型已保存到 basketball_potential_model.zip");
// 使用模型进行预测示例
var predictionEngine = mlContext.Model.CreatePredictionEngine<PlayerData, PlayerPrediction>(model);
var samplePlayer = new PlayerData()
{
age = 22,
player_height = 201,
player_weight = 100,
draft_year = 2020,
draft_round = 1,
draft_number = 15,
gp = 70,
reb = 5,
ast = 3,
net_rating = 5,
oreb_pct = 0.1f,
dreb_pct = 0.2f,
usg_pct = 0.2f,
ts_pct = 0.55f,
ast_pct = 0.15f
};
var prediction = predictionEngine.Predict(samplePlayer);
Console.WriteLine($"预测得分: {prediction.pts:0.##}");
}
}
}
关键代码说明
数据加载和预览
C#// 创建机器学习上下文,设置随机种子确保结果可重现
var mlContext = new MLContext(seed: 0);
// 从CSV文件加载数据
IDataView dataView = mlContext.Data.LoadFromTextFile<PlayerData>("./data/players_data.csv",
hasHeader: true, separatorChar: ',');
// 预览数据,查看数据加载情况
var preview = dataView.Preview();
这部分代码负责数据的初始化加载,并通过Preview()方法查看数据是否正确加载。
数据处理管道构建
C#var pipeline = mlContext.Transforms.ReplaceMissingValues(
// 处理缺失值
new[] {
"age", "player_height", "player_weight", "draft_year", "draft_round",
"draft_number", "gp", "pts", "reb", "ast", "net_rating", "oreb_pct",
"dreb_pct", "usg_pct", "ts_pct", "ast_pct"
}.Select(name => new InputOutputColumnPair(name, name)).ToArray())
// 设置预测目标
.Append(mlContext.Transforms.CopyColumns(outputColumnName: "Label", inputColumnName: "pts"))
// 组合特征
.Append(mlContext.Transforms.Concatenate("Features",
"age", "player_height", "player_weight", "draft_year", "draft_round",
"draft_number", "gp", "reb", "ast", "net_rating", "oreb_pct",
"dreb_pct", "usg_pct", "ts_pct", "ast_pct"))
// 特征归一化
.Append(mlContext.Transforms.NormalizeMinMax("Features"));
数据处理管道包含以下步骤:
- 处理缺失值
- 设置预测目标(得分)
- 组合多个特征列
- 对特征进行归一化处理
模型训练
C#// 添加FastForest训练器
var trainer = mlContext.Regression.Trainers.FastForest(numberOfTrees: 100,
minimumExampleCountPerLeaf: 10);
var trainingPipeline = pipeline.Append(trainer);
// 分割训练集和测试集
var trainTestData = mlContext.Data.TrainTestSplit(dataView, testFraction: 0.2);
// 训练模型
var model = trainingPipeline.Fit(trainTestData.TrainSet);
这部分实现了:
- 使用FastForest(随机森林)算法作为训练器
- 将数据按8:2比例分割为训练集和测试集
- 使用训练集训练模型
模型评估
C#var predictions = model.Transform(trainTestData.TestSet);
var metrics = mlContext.Regression.Evaluate(predictions);
Console.WriteLine($"R²: {metrics.RSquared:0.##}");
Console.WriteLine($"均方根误差: {metrics.RootMeanSquaredError:0.##}");
Console.WriteLine($"平均绝对误差: {metrics.MeanAbsoluteError:0.##}");
使用测试集评估模型性能,输出:
- R²值(决定系数)
- 均方根误差(RMSE)
- 平均绝对误差(MAE)
模型预测
C#var predictionEngine = mlContext.Model.CreatePredictionEngine<PlayerData, PlayerPrediction>(model);
var samplePlayer = new PlayerData()
{
age = 22,
player_height = 201,
player_weight = 100,
// ... 其他特征
};
var prediction = predictionEngine.Predict(samplePlayer);
Console.WriteLine($"预测得分: {prediction.pts:0.##}");
这部分展示了如何:
- 创建预测引擎
- 使用训练好的模型对新球员数据进行得分预测
使用的特征说明
主要使用了以下特征进行预测:
- 基本信息:年龄、身高、体重
- 选秀信息:选秀年、轮次、顺位
- 比赛数据:出场次数、篮板、助攻
- 效率指标:净效率、篮板率、使用率、真实命中率、助攻率
模型通过这些特征的组合来预测球员的得分能力,从而评估球员的潜力。
总结
通过以上步骤,我们演示了如何在 C# 环境结合 ML.NET,基于多赛季的 NBA 球员统计数据,构建一个简单的回归模型来预测球员的未来场均得分。实际场景中,您可以进一步优化特征工程、引入更多满足业务需求的特征数据,并将训练得到的模型上线,为对球员未来表现的评估或球队管理决策提供数据支撑。
希望本文能够帮助 C# 开发者与数据分析爱好者更好地运用 ML.NET 模型探索 NBA 球员的发展潜力,相信随着更多数据的积累和特征的挖掘,预测的准确度也会不断提升。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!