
Press Ctrl+ and K to search
目录
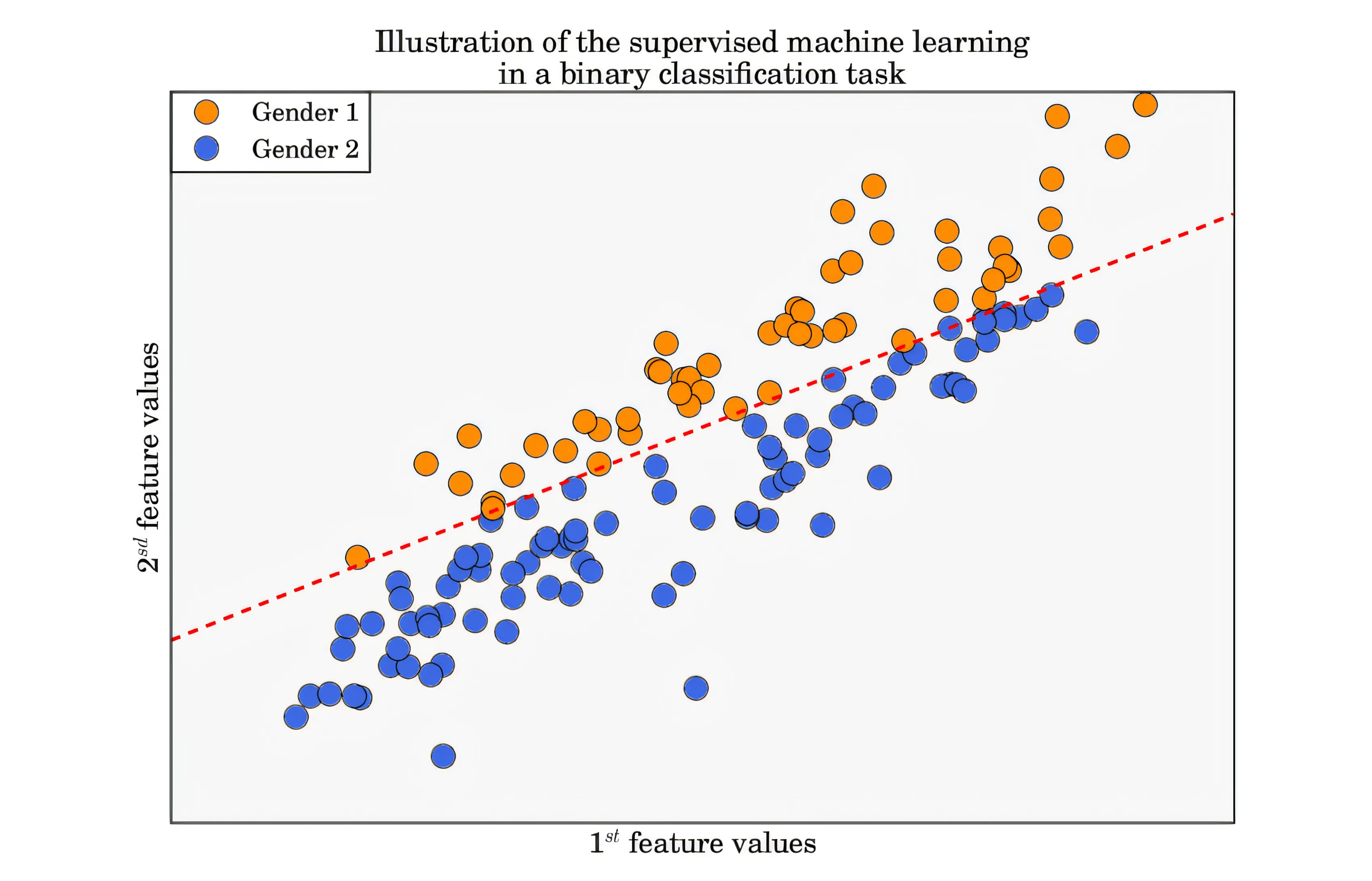
二元分类(Binary Classification)是机器学习领域中最基础也最常见的一种监督学习任务。顾名思义,它旨在将数据实例划分为两个互斥的类别,通常用"0"或"1"、"是"或"否"、"正"或"负"等标签表示。
常见应用场景
在实践中,二元分类有着广泛而重要的应用,以下是一些典型示例:
- 情感分析:判定社交媒体评论的情绪倾向(积极或消极)。
- 医学诊断:依据各项检查指标,预测患者是否患有特定疾病。
- 垃圾邮件过滤:识别并标记电子邮件为垃圾邮件或非垃圾邮件。
- 图像识别:判断某张图片中是否包含指定对象(如狗、水果等)。
拓展的应用领域
随着技术的发展,二元分类的应用范围不断拓展,以下是一些潜在的应用领域:
- 网络安全:识别网络流量中的潜在异常或恶意行为(如欺诈交易、木马攻击)。
- 金融风险评估:根据用户信用历史,判断信用卡欺诈或贷款违约的可能性。
- 社交网络分析:检测虚假账号或垃圾信息。
- 生产与运维:监测工业设备状态,预测潜在故障。
二元分类的工作原理
二元分类的基本流程包括以下几个关键步骤:
- 数据准备:收集带有明确标签(0或1)的数据样本
- 特征提取:从原始数据中提取有意义的特征向量
- 模型训练:使用标记数据训练分类器
- 预测:利用训练好的模型对新实例进行分类预测
二元分类是指在恰好两个类别(如是/否、正/负)之间做出预测决策的监督式机器学习任务。例如:
- 将评论区分为正面或负面
- 判断病人是否患有某种疾病
- 判定邮件是否为垃圾邮件
ML.NET 中的二元分类模型,要求:
- 标签列(Label) 为布尔型(Boolean)
- 特征列(Features) 为 Single(float)类型的固定大小向量
这些训练器在训练后通常会输出:
- Score (Single):模型计算出的原始分数
- PredictedLabel (Boolean):基于分数得出的最终布尔预测结果
ML.Net常见的二元分类训练器
以下列出可用于二元分类的训练器,并简要说明其核心特点:
- AveragedPerceptronTrainer
- 使用线性感知器的平均更新策略
- 适合高维度特征及中等规模以上的数据
- 训练速度快,对噪声有一定鲁棒性
- SdcaLogisticRegressionBinaryTrainer
- 基于随机坐标下降 (SDCA) 的逻辑回归
- 对大规模数据有较好表现,支持稀疏特征更新
- 支持概率输出,便于阈值调整
- SdcaNonCalibratedBinaryTrainer
- 同样基于 SDCA,但无概率校准
- 效率与特性与 SdcaLogisticRegressionBinaryTrainer 类似
- 如果仅需要 0/1 决策结果,而不关心概率分布,可选择此方法
- SymbolicSgdLogisticRegressionBinaryTrainer
- 采用符号式随机梯度下降 (Symbolic SGD) 的逻辑回归
- 在分布式或流式数据环境中表现良好
- 在内存占用方面有一定优化
- LbfgsLogisticRegressionBinaryTrainer
- 利用 L-BFGS(准牛顿法)优化逻辑回归
- 对中型规模数据收敛速度较快
- 精度表现通常优于简单的随机梯度下降
- LightGbmBinaryTrainer
- 基于 LightGBM 框架的梯度提升树 (GBDT)
- 对大规模、高维稀疏特征有出色的训练速度和内存占用优势
- 工业应用及比赛常用,综合性能强大
- FastTreeBinaryTrainer
- 使用梯度 boosting 决策树 (FastTree)
- 多线程加速,能捕捉特征间的非线性关系
- 适合中等规模或更大规模数据
- FastForestBinaryTrainer
- 随机森林 (Random Forest) 的快速实现
- 通过训练多棵决策树进行投票,有较强的防过拟合能力
- 对缺省值及噪声数据较为鲁棒
- GamBinaryTrainer
- 通用加性模型 (Generalized Additive Model)
- 能捕捉非线性关系且更具可解释性
- 对可解释性要求较高的业务可优先考虑
- FieldAwareFactorizationMachineTrainer
- 场感知因子分解机 (Field-aware Factorization Machine)
- 擅长处理多个字段 (field) 的特征交互,常用于广告点击率、推荐等场景
- 对稀疏和高维度数据有良好建模能力
- PriorTrainer
- 基于先验(Prior)信息的训练器
- 只依据数据的正负样本占比来进行预测
- 可作为简单的基准模型或快速对比方法
- LinearSvmTrainer
- 线性支持向量机 (SVM)
- 对高维度特征有良好适应性,训练速度较快
- 需合理调整超参数(如正则化强度)
使用建议
- 数据平衡:建议正负样本数量大致相当,否则需要做采样或调整等操作,
- 处理缺失值:训练前应仔细处理数据中的缺失值
- 模型选择:可根据数据规模、特征类型、对可解释性或预测性能的要求,选择不同的训练器
总结
二元分类作为机器学习的基础任务,在实际应用中具有广泛价值。通过选择合适的算法、处理好数据平衡问题、选择正确的评估指标,可以构建出高效可靠的二元分类模型,为各行各业的智能决策提供有力支持。
无论您是希望过滤垃圾邮件、预测客户流失风险,还是开发医疗辅助诊断系统,掌握二元分类技术都将为您的应用赋能。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录