
目录
在机器学习领域,选择合适的算法和训练器对于模型的性能至关重要。ML.NET 提供了多种训练器,其中 FastTreeBinaryTrainer 是一种基于梯度提升树(Gradient Boosting Trees)的二分类训练器。本文将深入探讨 FastTreeBinaryTrainer 的适用场景,并通过详细的示例来展示其使用方法。
什么是 FastTreeBinaryTrainer?
FastTreeBinaryTrainer 是 ML.NET 中用于二分类问题的训练器。它通过构建一系列决策树来逐步改进模型的预测能力。每棵树都是在前一棵树的基础上进行训练的,旨在减少模型的误差。该训练器特别适合处理大规模数据集,并且能够处理特征之间的复杂关系。
适用场景
FastTreeBinaryTrainer 适用于以下场景:
- 大规模数据集:当数据集较大时,FastTreeBinaryTrainer 能够有效地处理并训练模型。
- 特征复杂性高:对于特征之间存在非线性关系的数据,梯度提升树能够捕捉到这些复杂的模式。
- 需要高准确率的应用:在金融欺诈检测、医疗诊断等需要高准确率的场景中,FastTreeBinaryTrainer 是一个理想的选择。
- 处理缺失值:该训练器能够自动处理缺失值,减少数据预处理的工作量。
示例:使用 FastTreeBinaryTrainer 进行二分类
下面是一个使用 FastTreeBinaryTrainer 进行二分类的完整示例。我们将使用 Titanic 数据集来预测乘客是否生存。
安装 ML.NET
首先,确保在项目中安装了 ML.NET NuGet 包。可以通过 NuGet 包管理器控制台运行以下命令:
BashInstall-Package Microsoft.ML
完整代码
C#using System;
using System.IO;
using System.Linq;
using Microsoft.ML;
using Microsoft.ML.Data;
namespace TitanicSurvivalPrediction
{
public class TitanicData
{
[LoadColumn(0)] public float PassengerId { get; set; }
[LoadColumn(1)]
public bool Label { get; set; }
[LoadColumn(2)] public float Pclass { get; set; }
[LoadColumn(4)] public string Sex { get; set; }
[LoadColumn(5)] public float Age { get; set; }
[LoadColumn(6)] public float SibSp { get; set; }
[LoadColumn(7)] public float Parch { get; set; }
[LoadColumn(10)] public float Fare { get; set; }
[LoadColumn(12)] public string Embarked { get; set; }
}
public class SurvivalPrediction
{
[ColumnName("PredictedLabel")]
public bool Survived { get; set; }
public float Probability { get; set; }
}
class Program
{
static void Main(string[] args)
{
var mlContext = new MLContext(seed: 42);
// 1. 加载数据并处理
var data = mlContext.Data.LoadFromTextFile(
"Titanic-Dataset.csv",
new[]
{
new TextLoader.Column("PassengerId", DataKind.Single, 0),
new TextLoader.Column("Label", DataKind.Boolean, 1),
new TextLoader.Column("Pclass", DataKind.Single, 2),
new TextLoader.Column("Sex", DataKind.String, 4),
new TextLoader.Column("Age", DataKind.Single, 5),
new TextLoader.Column("SibSp", DataKind.Single, 6),
new TextLoader.Column("Parch", DataKind.Single, 7),
new TextLoader.Column("Fare", DataKind.Single, 10),
new TextLoader.Column("Embarked", DataKind.String, 12)
},
hasHeader: true,
separatorChar: ',',
allowQuoting:true);// 允许字段被引号包裹
// 2. 数据预处理和特征工程管道
var pipeline = mlContext.Transforms.CopyColumns("Label", "Label")
.Append(mlContext.Transforms.CustomMapping(
(TitanicData input, CustomFeatures output) =>
{
// 性别编码
output.SexEncoded = input.Sex == "male" ? 0f : 1f;
// 登船地编码
output.EmbarkedEncoded = input.Embarked switch
{
"S" => 0f,
"C" => 1f,
"Q" => 2f,
_ => -1f
};
},
"CustomFeatureEncoding")
// 处理缺失值
.Append(mlContext.Transforms.ReplaceMissingValues("Age", "Age"))
.Append(mlContext.Transforms.ReplaceMissingValues("Fare", "Fare"))
// 特征归一化
.Append(mlContext.Transforms.NormalizeMeanVariance("Age"))
.Append(mlContext.Transforms.NormalizeMeanVariance("Fare"))
// 特征组合
.Append(mlContext.Transforms.Concatenate(
"Features",
"Pclass",
"SexEncoded",
"Age",
"SibSp",
"Parch",
"Fare",
"EmbarkedEncoded")));
// 3. 分割训练集和测试集
var trainTestSplit = mlContext.Data.TrainTestSplit(data, testFraction: 0.2);
// 4. 训练设置
var trainer = mlContext.BinaryClassification.Trainers.FastTree(
labelColumnName: "Label",
featureColumnName: "Features"
);
// 5. 完整训练管道
var trainingPipeline = pipeline.Append(trainer);
// 6. 训练模型
var model = trainingPipeline.Fit(trainTestSplit.TrainSet);
// 7. 模型评估
var predictions = model.Transform(trainTestSplit.TestSet);
var metrics = mlContext.BinaryClassification.Evaluate(predictions);
// 输出评估指标
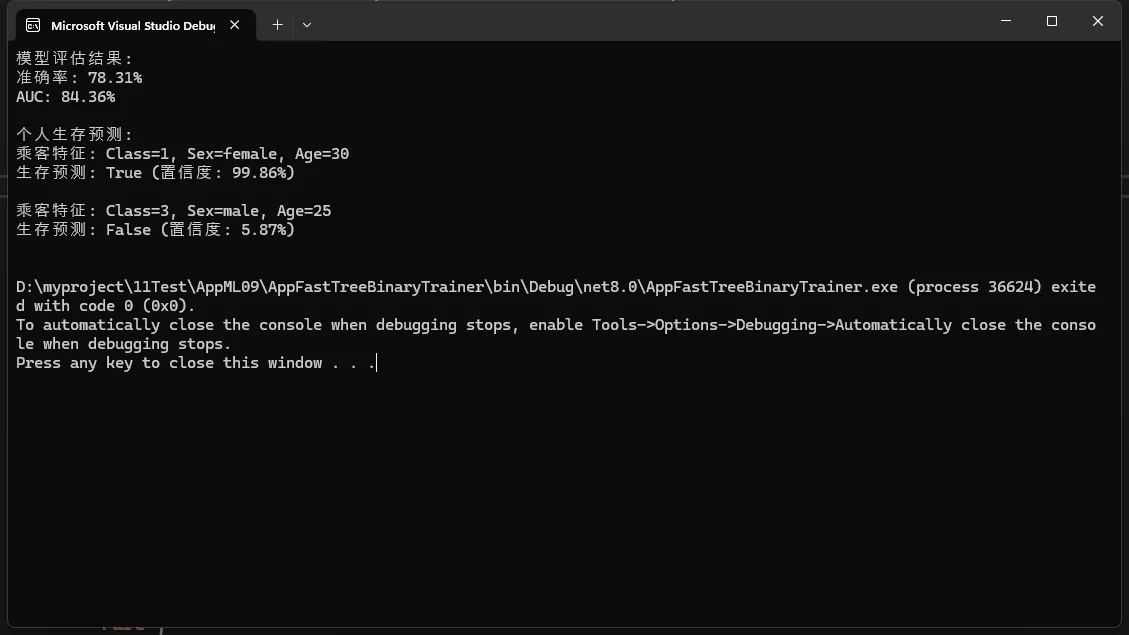
Console.WriteLine($"模型评估结果:");
Console.WriteLine($"准确率: {metrics.Accuracy:P2}");
Console.WriteLine($"AUC: {metrics.AreaUnderRocCurve:P2}");
// 8. 创建预测引擎
var predictionEngine = mlContext.Model.CreatePredictionEngine<TitanicData, SurvivalPrediction>(model);
// 9. 示例预测
var testPassengers = new[]
{
new TitanicData {
Pclass = 1,
Sex = "female",
Age = 30,
SibSp = 1,
Parch = 0,
Fare = 50,
Embarked = "C"
},
new TitanicData {
Pclass = 3,
Sex = "male",
Age = 25,
SibSp = 0,
Parch = 0,
Fare = 10,
Embarked = "S"
}
};
Console.WriteLine("\n个人生存预测:");
foreach (var passenger in testPassengers)
{
var prediction = predictionEngine.Predict(passenger);
Console.WriteLine($"乘客特征: Class={passenger.Pclass}, Sex={passenger.Sex}, Age={passenger.Age}");
Console.WriteLine($"生存预测: {prediction.Survived} (置信度: {prediction.Probability:P2})\n");
}
// 10. 保存模型
mlContext.Model.Save(model, data.Schema, "TitanicSurvivalModel.zip");
}
// 自定义特征类
public class CustomFeatures
{
public float SexEncoded { get; set; }
public float EmbarkedEncoded { get; set; }
}
}
}
处理缺失值(ReplaceMissingValues)
C#.Append(mlContext.Transforms.ReplaceMissingValues("Age", "Age"))
.Append(mlContext.Transforms.ReplaceMissingValues("Fare", "Fare"))
作用:
-
解决数据集中的空值问题
-
防止模型因缺失数据而无法训练
-
常见的处理方式包括:
a) 用平均值替换
b) 用中位数替换
c) 用固定值替换
d) 使用更复杂的插补策略
特征归一化(NormalizeMeanVariance)
C#.Append(mlContext.Transforms.NormalizeMeanVariance("Age"))
.Append(mlContext.Transforms.NormalizeMeanVariance("Fare"))
作用:
- 将不同尺度的特征转换到相似的尺度范围
- 防止某些特征因数值大小而主导模型学习
- 加速机器学习算法的收敛
- 提高模型的泛化能力
归一化的具体过程:
- 计算特征的均值和标准差
- 使用公式:(x - mean) / standarddeviation
- 转换后的特征将:
- 均值接近0
- 方差接近1
举例说明:
- 原始Age数据:[20, 30, 40]
- 归一化后:[-1, 0, 1]
好处:
- 对于FastTree等算法,归一化可以加快训练过程
- 使不同尺度的特征(如Age和Fare)在模型中具有相近的权重
- 提高模型的稳定性和泛化能力
总结:
- 处理缺失值:确保数据完整性
- 特征归一化:标准化特征尺度,改善模型学习
这两个步骤是机器学习中常见的数据预处理技术,能显著提升模型的性能和可靠性。
结论
FastTreeBinaryTrainer 是 ML.NET 中强大的二分类训练器,适用于多种复杂场景。通过本文的示例,我们展示了如何使用该训练器进行 Titanic 数据集的生存预测。无论是在处理大规模数据集还是捕捉复杂特征关系时,FastTreeBinaryTrainer 都能提供出色的性能。
希望这篇文章能帮助你更好地理解 FastTreeBinaryTrainer 的应用场景及其使用方法!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!