
目录
在现代工业环境中,安全事故不仅威胁员工健康,还会导致生产损失和声誉受损。人工智能技术的发展为预防工业事故提供了新思路。本文将详细介绍如何使用Microsoft的机器学习框架ML.NET构建工厂事故预测模型,帮助企业提前识别潜在风险,采取预防措施。
ML.NET简介
ML.NET是微软开发的开源、跨平台机器学习框架,专为.NET开发者设计。它允许在.NET应用程序中集成机器学习功能,无需依赖外部服务。ML.NET支持多种机器学习算法,包括分类、回归、聚类和异常检测等,适用于各种预测场景。
工厂事故预测案例实战
接下来,我们将使用实际工厂事故数据,构建一个能够预测事故严重级别的模型。
数据准备
数据集下载
Markdownhttps://www.kaggle.com/datasets/ihmstefanini/industrial-safety-and-health-analytics-database/data
首先,我们需要准备数据集。以下是我们将使用的事故数据结构:
C#using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.ML.Data;
namespace AppFactoryAccidentPrediction
{
public class AccidentData
{
[LoadColumn(0)]
public float SeqNo { get; set; }
[LoadColumn(1)]
public string Date { get; set; }
[LoadColumn(2)]
public string Country { get; set; }
[LoadColumn(3)]
public string Local { get; set; }
[LoadColumn(4)]
public string IndustrySector { get; set; }
[LoadColumn(5)]
public string AccidentLevel { get; set; }
[LoadColumn(6)]
public string PotentialAccidentLevel { get; set; }
[LoadColumn(7)]
public string Genre { get; set; }
[LoadColumn(8)]
public string EmployeeOrThirdParty { get; set; }
[LoadColumn(9)]
public string CriticalRisk { get; set; }
[LoadColumn(10)]
public string Description { get; set; }
}
public class AccidentPrediction
{
[ColumnName("PredictedLabel")]
public string PredictedAccidentLevel { get; set; }
public float[] Score { get; set; }
}
}
完整实现代码
以下是一个完整的ML.NET事故预测模型实现:
C#using Microsoft.ML;
namespace AppFactoryAccidentPrediction
{
internal class Program
{
// 定义文件路径
private static string _dataPath = "accident_data.csv";
private static string _modelPath = "AccidentPredictionModel.zip";
static void Main(string[] args)
{
Console.OutputEncoding = System.Text.Encoding.UTF8;
Console.WriteLine("工厂事故预测系统启动...");
// 创建ML.NET上下文
MLContext mlContext = new MLContext(seed: 0);
// 加载数据
Console.WriteLine("正在加载数据...");
IDataView dataView = mlContext.Data.LoadFromTextFile<AccidentData>(
path: _dataPath,
hasHeader: true,
separatorChar: ',',
allowQuoting: true
);
// 分割训练集和测试集
var dataSplit = mlContext.Data.TrainTestSplit(dataView, testFraction: 0.2);
var trainingData = dataSplit.TrainSet;
var testData = dataSplit.TestSet;
// 数据处理和特征工程
Console.WriteLine("正在处理数据和提取特征...");
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey(
outputColumnName: "Label", // 这将创建一个新列作为Key类型标签
inputColumnName: "AccidentLevel" // 原始字符串标签
)
.Append(mlContext.Transforms.Categorical.OneHotEncoding(
new[] {
new InputOutputColumnPair("CountryEncoded", "Country"),
new InputOutputColumnPair("IndustrySectorEncoded", "IndustrySector"),
new InputOutputColumnPair("CriticalRiskEncoded", "CriticalRisk"),
new InputOutputColumnPair("GenreEncoded", "Genre"),
new InputOutputColumnPair("EmployeeTypeEncoded", "EmployeeOrThirdParty")
}))
// 文本特征提取(从描述中提取特征)
.Append(mlContext.Transforms.Text.FeaturizeText("DescriptionFeaturized", "Description"))
// 合并所有特征到一个向量
.Append(mlContext.Transforms.Concatenate("Features",
"CountryEncoded", "IndustrySectorEncoded", "CriticalRiskEncoded",
"GenreEncoded", "EmployeeTypeEncoded", "DescriptionFeaturized"));
// 选择训练算法 - 使用多类分类器
Console.WriteLine("构建和训练模型...");
var trainer = mlContext.MulticlassClassification.Trainers.SdcaMaximumEntropy();
// 构建完整训练管道
var trainingPipeline = dataProcessPipeline.Append(trainer)
// 将预测结果映射回原始标签值
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
// 训练模型
var trainedModel = trainingPipeline.Fit(trainingData);
Console.WriteLine("模型训练完成!");
// 保存模型
mlContext.Model.Save(trainedModel, trainingData.Schema, _modelPath);
Console.WriteLine($"模型已保存到: {_modelPath}");
// 评估模型
Console.WriteLine("评估模型性能...");
var predictions = trainedModel.Transform(testData);
var metrics = mlContext.MulticlassClassification.Evaluate(predictions);
// 输出评估指标
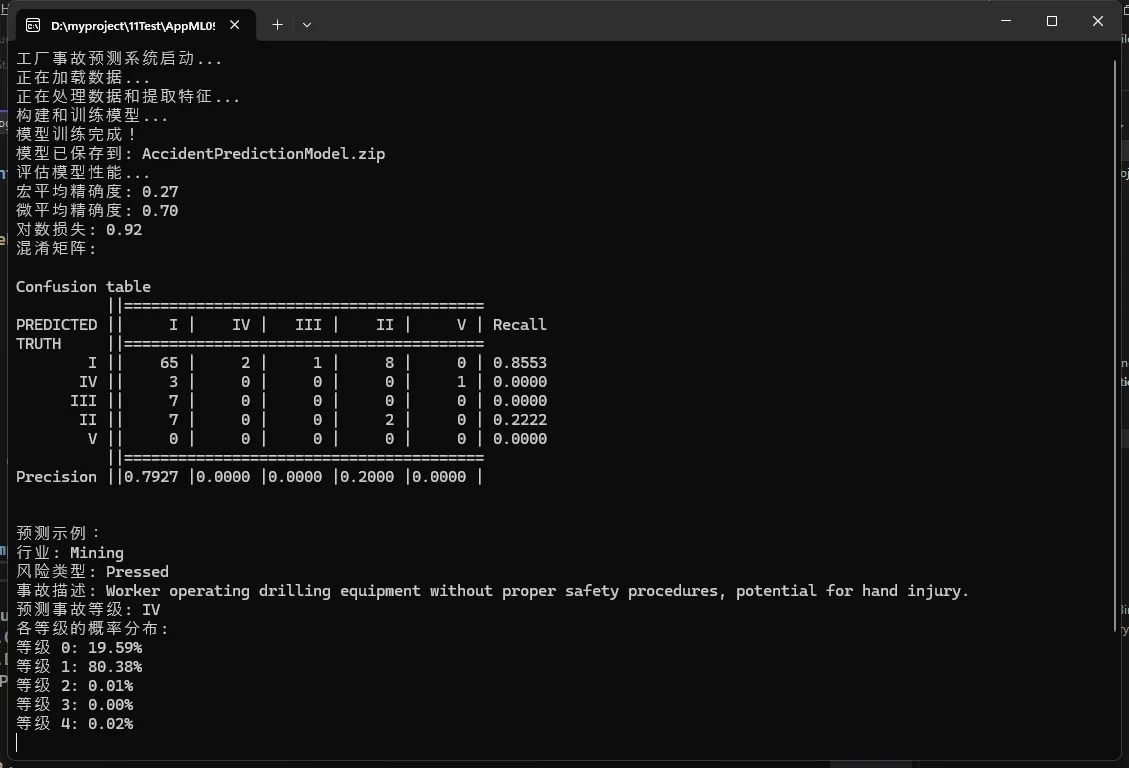
Console.WriteLine($"宏平均精确度: {metrics.MacroAccuracy:F2}");
Console.WriteLine($"微平均精确度: {metrics.MicroAccuracy:F2}");
Console.WriteLine($"对数损失: {metrics.LogLoss:F2}");
Console.WriteLine($"混淆矩阵: \n{metrics.ConfusionMatrix.GetFormattedConfusionTable()}");
// 使用模型进行预测示例
PredictSample(mlContext, trainedModel);
}
private static void PredictSample(MLContext mlContext, ITransformer model)
{
// 创建预测引擎
var predictionEngine = mlContext.Model.CreatePredictionEngine<AccidentData, AccidentPrediction>(model);
// 创建测试样本
var sampleAccident = new AccidentData
{
Country = "Country_01",
IndustrySector = "Mining",
Genre = "Male",
EmployeeOrThirdParty = "Third Party",
CriticalRisk = "Pressed",
Description = "Worker operating drilling equipment without proper safety procedures, potential for hand injury."
};
// 进行预测
var prediction = predictionEngine.Predict(sampleAccident);
Console.WriteLine("\n预测示例:");
Console.WriteLine($"行业: {sampleAccident.IndustrySector}");
Console.WriteLine($"风险类型: {sampleAccident.CriticalRisk}");
Console.WriteLine($"事故描述: {sampleAccident.Description}");
Console.WriteLine($"预测事故等级: {prediction.PredictedAccidentLevel}");
// 输出各类别的概率
Console.WriteLine("各等级的概率分布:");
var labels = new[] { "I", "II", "III", "IV" };
for (int i = 0; i < prediction.Score.Length; i++)
{
if (i < prediction.Score.Length)
Console.WriteLine($"等级 {i}: {prediction.Score[i]:P2}");
}
Console.ReadKey();
}
}
}
代码解析
让我们详细解析上述代码中的关键部分:
1. 数据加载与分割
C#// 加载CSV数据
IDataView dataView = mlContext.Data.LoadFromTextFile<AccidentData>(
path: _dataPath,
hasHeader: true,
separatorChar: ',',
allowQuoting: true
);
// 分割训练集和测试集(80/20分割)
var dataSplit = mlContext.Data.TrainTestSplit(dataView, testFraction: 0.2);
这部分代码从CSV文件加载事故数据,并将数据分成训练集(80%)和测试集(20%)。
2. 数据处理与特征工程
C#var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey(
outputColumnName: "Label", // 这将创建一个新列作为Key类型标签
inputColumnName: "AccidentLevel" // 原始字符串标签
)
.Append(mlContext.Transforms.Categorical.OneHotEncoding(
new[] {
new InputOutputColumnPair("CountryEncoded", "Country"),
new InputOutputColumnPair("IndustrySectorEncoded", "IndustrySector"),
new InputOutputColumnPair("CriticalRiskEncoded", "CriticalRisk"),
new InputOutputColumnPair("GenreEncoded", "Genre"),
new InputOutputColumnPair("EmployeeTypeEncoded", "EmployeeOrThirdParty")
}))
// 文本特征提取(从描述中提取特征)
.Append(mlContext.Transforms.Text.FeaturizeText("DescriptionFeaturized", "Description"))
// 合并所有特征到一个向量
.Append(mlContext.Transforms.Concatenate("Features",
"CountryEncoded", "IndustrySectorEncoded", "CriticalRiskEncoded",
"GenreEncoded", "EmployeeTypeEncoded", "DescriptionFeaturized"));
这部分代码进行了以下处理:
- 将字符串类型的事故等级(如"I"、"II"、"III"、"IV")转换为ML.NET内部可识别的数值编码(Key类型)
- 对分类特征(如国家、行业)进行一热编码转换
- 对事故描述文本进行特征化处理
- 将所有特征合并为一个特征向量
3. 模型训练
C#// 选择多类分类器
var trainer = mlContext.MulticlassClassification.Trainers.SdcaMaximumEntropy()
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
// 构建和训练完整模型
var trainingPipeline = dataProcessPipeline.Append(trainer);
var trainedModel = trainingPipeline.Fit(trainingData);
这里使用了SDCA最大熵分类器来训练模型,适用于多类别分类问题(预测事故等级)。
4. 模型评估
C#var predictions = trainedModel.Transform(testData);
var metrics = mlContext.MulticlassClassification.Evaluate(predictions);
// 输出评估指标
Console.WriteLine($"宏平均精确度: {metrics.MacroAccuracy:F2}");
// 其他评估指标...
这部分代码使用测试集评估模型性能,计算宏平均精确度、微平均精确度等指标。
5. 模型预测
C#// 创建预测引擎
var predictionEngine = mlContext.Model.CreatePredictionEngine<AccidentData, AccidentPrediction>(model);
// 创建测试样本并进行预测
var sampleAccident = new AccidentData { /*...样本数据...*/ };
var prediction = predictionEngine.Predict(sampleAccident);
这部分代码演示了如何使用训练好的模型对新的事故数据进行预测。
实际应用场景
这个工厂事故预测模型可应用于多个实际场景:
- 安全风险评估:在工作开始前,基于工作类型、环境和人员等因素评估潜在风险。
- 预防性安全措施:针对预测为高风险的活动,自动推荐额外的安全措施。
- 工作人员培训:识别特定类型工作或特定员工群体的高风险模式,定制安全培训计划。
- 资源优化配置:根据预测的风险级别,合理分配安全监督人员和设备。
结论
ML.NET为工厂安全管理提供了强大的预测工具。通过分析历史事故数据,我们可以构建智能模型,预测潜在事故的严重程度,从而采取针对性预防措施。随着数据量增加和模型迭代改进,这类预测系统将成为工业安全管理的重要组成部分,有效减少事故发生,保障员工安全和企业生产。
希望本文详细介绍的ML.NET工厂事故预测实现方案能为您的安全管理工作提供新的思路和技术支持。通过人工智能与传统安全管理的结合,我们能够构建更加智能、高效的工业安全体系。
关键词:ML.NET, 机器学习, 工厂安全, 事故预测, C#开发, 工业安全管理, 人工智能应用, 预测建模, 安全风险评估
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!