
目录
在离散制造车间的上位机与 MES 对接项目中,采集频率的选择往往被低估——直到数据库撑不住、网络打满、或者业务数据对不上,才开始反思这个决定。
一、问题引入
在一个离散制造车间的数字化项目中,我们需要采集 PLC 上的设备状态、计数器、报警信号,并同步到 MES 系统。
项目初期,技术团队的第一反应几乎都是:"采快一点,数据更准。" 于是默认设成了 100ms 轮询一次。
上线两周后,问题来了:
- SQL Server 的写入 TPS 持续飙高,I/O 告警频繁
- 网络带宽在班次高峰期出现拥塞
- MES 侧的报工数据和实际节拍对不上,差了几秒到几十秒不等
排查下来,根本原因不是代码写错了,而是采集频率从一开始就没有根据业务需求来定。
这个问题在离散制造场景中非常普遍。设备信号的变化节奏、业务对数据的实时性要求、系统的存储与传输能力——三者之间的匹配关系,才是决定采集频率的核心依据。
二、经验分析
2.1 为什么"采快一点"是个陷阱
很多开发者在设计采集方案时,会把"采集频率"等同于"数据精度"。这个认知在某些场景下是对的,但在工厂现场,它会带来三个典型问题:
第一,信号变化频率 ≠ 业务关注频率。
一个计件计数器,每隔 8 秒出一个产品。你用 100ms 采一次,得到的大多数数据都是重复值。这些冗余数据不仅浪费存储,还会干扰后续分析。
第二,写入压力被严重低估。
假设车间有 50 台设备,每台设备采集 20 个点位,100ms 一次:
50 台 × 20 点 × 10 次/秒 = 10,000 条/秒
一天 8 小时班次下来,光原始数据就是 2.88 亿条。这还只是一个班次,还没算多班制。
第三,事件型信号用轮询天然有延迟。
报警信号、门禁触发、工序完成——这类信号的特征是"变化时刻"才有意义。用固定频率轮询,最坏情况下会漏掉一个完整的脉冲,或者响应延迟接近一个采集周期。
2.2 三种常见方案对比
| 方案 | 典型频率 | 适用信号类型 | 优点 | 缺点 |
|---|---|---|---|---|
| 高频轮询 | 10ms–100ms | 模拟量、连续变化量 | 实现简单,覆盖全 | 写入压力大,冗余数据多 |
| 低频轮询 | 1s–10s | 状态量、统计量 | 资源占用低,易维护 | 对快变信号响应慢 |
| 事件触发 | 变化即推送 | 报警、离散开关量 | 精准、低延迟、无冗余 | 依赖设备/协议支持,实现复杂 |
在实际项目里,这三种方案不是互斥的,最终方案往往是混合策略:对不同信号分级,分别设定采集方式。
2.3 我最终选择的路径
在这个项目中,约束条件是:
- PLC 使用 Modbus TCP,不支持主动推送
- 数据库是 SQL Server,部署在本地工控机,磁盘 I/O 有限
- MES 对设备状态的刷新要求是"5 秒内可见",对报工数量要求是"班次级准确"
基于这些约束,我把信号分成三类,分别对待:
- 模拟量(温度、压力、电流):1 秒采一次,变化超阈值才写库(死区过滤)
- 状态量(运行/停机/故障):500ms 轮询,状态变化时写库 + 推送 MES
- 计数器(产量计件):1 秒采一次,值变化时记录时间戳和增量
这个策略让写入 TPS 从峰值 10,000 降到了约 200–400,数据库压力直接解决。
三、技术方案
3.1 整体架构
[ PLC / 设备 ] ↓ Modbus TCP / OPC-UA [ 采集服务(C# Worker Service)] ↓ 分级策略 + 死区过滤 [ 本地缓冲队列(内存 / SQLite)] ↓ 批量写入 [ SQL Server 原始数据库 ] ↓ 聚合计算 [ MES 接口层(ASP.NET Web API)]
关键设计原则:采集与写入解耦。 采集线程只负责读数据,写入由独立线程消费队列完成。这样即使写入出现短暂延迟,采集不会被阻塞。
3.2 信号分级配置表
建议把采集策略做成配置,而不是硬编码。以下是一个典型的配置表设计:
| 字段名 | 类型 | 说明 |
|---|---|---|
signal_id | VARCHAR(50) | 信号唯一标识 |
signal_type | TINYINT | 1=模拟量 2=状态量 3=计数器 |
poll_interval_ms | INT | 轮询间隔(毫秒) |
deadband_value | DECIMAL(10,4) | 死区阈值(模拟量用) |
write_on_change | BIT | 是否仅变化时写库 |
mq_push_enabled | BIT | 是否推送到 MES 队列 |
sqlCREATE TABLE signal_config (
signal_id VARCHAR(50) NOT NULL PRIMARY KEY,
signal_type TINYINT NOT NULL,
poll_interval_ms INT NOT NULL DEFAULT 1000,
deadband_value DECIMAL(10,4) NULL,
write_on_change BIT NOT NULL DEFAULT 1,
mq_push_enabled BIT NOT NULL DEFAULT 0,
updated_at DATETIME NOT NULL DEFAULT GETDATE()
);
3.3 原始数据表设计
采集到的数据统一落到一张原始数据表,保留完整时间戳:
sqlCREATE TABLE device_signal_raw (
id BIGINT IDENTITY(1,1) PRIMARY KEY,
signal_id VARCHAR(50) NOT NULL,
signal_value NVARCHAR(100) NOT NULL, -- 统一存字符串,业务层转换
quality TINYINT NOT NULL DEFAULT 1, -- 0=Bad 1=Good
collected_at DATETIME2(3) NOT NULL, -- 毫秒级精度
written_at DATETIME2(3) NOT NULL DEFAULT SYSUTCDATETIME()
);
CREATE INDEX ix_signal_raw_signal_time
ON device_signal_raw (signal_id, collected_at DESC);
这里
signal_value故意用NVARCHAR统一存储,避免因为类型变更频繁改表结构。类型转换交给查询层或业务层处理,代价是可接受的。
3.4 死区过滤 + 变化检测逻辑
这是降低写入压力的核心。以下是 C# 实现的简化版:
csharpusing AppWpf202603.Models;
using AppWpf202603.Services;
using System;
using System.Collections.Generic;
using System.Threading.Tasks;
namespace AppWpf202603.Services
{
/// <summary>
/// 单信号采集器:死区过滤 + 变化检测
/// </summary>
public class SignalCollector
{
private readonly Dictionary<string, string> _lastValues = new();
private readonly ISignalWriter _writer;
private readonly SignalConfig _config;
public int FilteredCount { get; private set; }
public int WrittenCount { get; private set; }
public SignalCollector(SignalConfig config, ISignalWriter writer)
{
_config = config;
_writer = writer;
}
public async Task ProcessSignalAsync(string signalId, string rawValue, DateTime collectedAt)
{
// ① 状态量 / 计数器:值变化才写库
if (_config.WriteOnChange)
{
if (_lastValues.TryGetValue(signalId, out var last) && last == rawValue)
{
FilteredCount++;
return;
}
}
// ② 模拟量:死区过滤
if (_config.SignalType == SignalType.Analog && _config.DeadbandValue.HasValue)
{
if (_lastValues.TryGetValue(signalId, out var lastStr)
&& double.TryParse(lastStr, out var lastVal)
&& double.TryParse(rawValue, out var curVal))
{
if (Math.Abs(curVal - lastVal) < (double)_config.DeadbandValue.Value)
{
FilteredCount++;
return;
}
}
}
// ③ 计数器:计算增量
double? delta = null;
if (_config.SignalType == SignalType.Counter)
{
if (_lastValues.TryGetValue(signalId, out var lastStr)
&& double.TryParse(lastStr, out var lastVal)
&& double.TryParse(rawValue, out var curVal))
{
// 处理复位跳变:增量为负时视为复位,增量取当前值
delta = curVal - lastVal >= 0 ? curVal - lastVal : curVal;
}
}
_lastValues[signalId] = rawValue;
WrittenCount++;
await _writer.WriteAsync(new SignalRecord
{
SignalId = signalId,
SignalValue = rawValue,
Quality = 1,
CollectedAt = collectedAt, // 坑1:在读取瞬间打时间戳
Delta = delta
});
}
}
}
csharpusing AppWpf202603.Models;
using AppWpf202603.Services;
using SqlSugar;
using System;
using System.Collections.Concurrent;
using System.Collections.Generic;
using System.Threading;
using System.Threading.Tasks;
namespace AppWpf202603.Services
{
/// <summary>
/// 批量写入器:采集与写入解耦,队列缓冲 + 定时批量刷写
/// </summary>
public class BatchSignalWriter : ISignalWriter, IDisposable
{
private readonly ConcurrentQueue<SignalRecord> _queue = new();
private readonly List<SignalRecord> _archive = new();
private readonly object _archiveLock = new();
private readonly ISqlSugarClient _db;
private readonly Timer _flushTimer;
private long _totalWritten;
private int _isFlushing;
private bool _disposed;
// 外部可订阅:每次批量写入完成后通知 UI
public event Action<IReadOnlyList<SignalRecord>>? BatchFlushed;
public int QueueDepth => _queue.Count;
public long TotalWritten => Interlocked.Read(ref _totalWritten);
public BatchSignalWriter(ISqlSugarClient db)
{
_db = db;
// 每 500ms 批量刷一次
_flushTimer = new Timer(_ => _ = FlushAsync(), null,
TimeSpan.FromMilliseconds(500),
TimeSpan.FromMilliseconds(500));
}
public Task WriteAsync(SignalRecord record)
{
record.WrittenAt = DateTime.Now;
_queue.Enqueue(record);
return Task.CompletedTask;
}
private async Task FlushAsync()
{
if (Interlocked.Exchange(ref _isFlushing, 1) == 1)
{
return;
}
var batch = new List<SignalRecord>();
try
{
while (_queue.TryDequeue(out var item) && batch.Count < 500)
{
batch.Add(item);
}
if (batch.Count == 0)
{
return;
}
var dbRows = new List<DeviceSignalRawRow>(batch.Count);
foreach (var item in batch)
{
dbRows.Add(new DeviceSignalRawRow
{
SignalId = item.SignalId,
SignalValue = item.SignalValue,
Quality = (byte)item.Quality,
CollectedAt = item.CollectedAt,
WrittenAt = item.WrittenAt
});
}
await _db.Insertable(dbRows).ExecuteCommandAsync();
lock (_archiveLock)
{
_archive.AddRange(batch);
// 保留最近 2000 条,防止内存无限增长
if (_archive.Count > 2000)
_archive.RemoveRange(0, _archive.Count - 2000);
}
Interlocked.Add(ref _totalWritten, batch.Count);
BatchFlushed?.Invoke(batch.AsReadOnly());
}
catch
{
foreach (var item in batch)
{
_queue.Enqueue(item);
}
}
finally
{
Interlocked.Exchange(ref _isFlushing, 0);
}
}
public IReadOnlyList<SignalRecord> GetArchive()
{
lock (_archiveLock)
return _archive.ToArray();
}
public void Dispose()
{
if (_disposed) return;
_disposed = true;
_flushTimer.Dispose();
}
}
}
在高并发场景下,建议所有关键接口都设计为幂等,采集写入也不例外——
collected_at+signal_id可以作为业务唯一键,防止重复写入。
c#using AppWpf202603.Models;
using SqlSugar;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
namespace AppWpf202603.Services
{
public class SignalConfigStore
{
private readonly ISqlSugarClient _db;
public SignalConfigStore(ISqlSugarClient db)
{
_db = db;
}
public async Task<IReadOnlyList<SignalConfig>> MergeWithDatabaseAsync(IEnumerable<SignalConfig> defaults)
{
var defaultList = defaults.ToList();
foreach (var cfg in defaultList)
{
var row = new SignalConfigRow
{
SignalId = cfg.SignalId,
SignalType = (byte)cfg.SignalType,
PollIntervalMs = cfg.PollIntervalMs,
DeadbandValue = cfg.DeadbandValue,
WriteOnChange = cfg.WriteOnChange,
MqPushEnabled = cfg.MqPushEnabled,
UpdatedAt = DateTime.Now
};
var existing = await _db.Queryable<SignalConfigRow>().InSingleAsync(cfg.SignalId);
if (existing == null)
{
await _db.Insertable(row).ExecuteCommandAsync();
}
else
{
await _db.Updateable(row)
.UpdateColumns(x => new
{
x.SignalType,
x.PollIntervalMs,
x.DeadbandValue,
x.WriteOnChange,
x.MqPushEnabled,
x.UpdatedAt
})
.WhereColumns(x => x.SignalId)
.ExecuteCommandAsync();
}
}
var dbRows = await _db.Queryable<SignalConfigRow>().ToListAsync();
var map = dbRows.ToDictionary(x => x.SignalId, StringComparer.OrdinalIgnoreCase);
foreach (var cfg in defaultList)
{
if (!map.TryGetValue(cfg.SignalId, out var row))
{
continue;
}
cfg.SignalType = (SignalType)row.SignalType;
cfg.PollIntervalMs = row.PollIntervalMs;
cfg.DeadbandValue = row.DeadbandValue;
cfg.WriteOnChange = row.WriteOnChange;
cfg.MqPushEnabled = row.MqPushEnabled;
}
return defaultList;
}
}
}
数据库操作使用sqlsugar 5.x版本。
四、运行效果
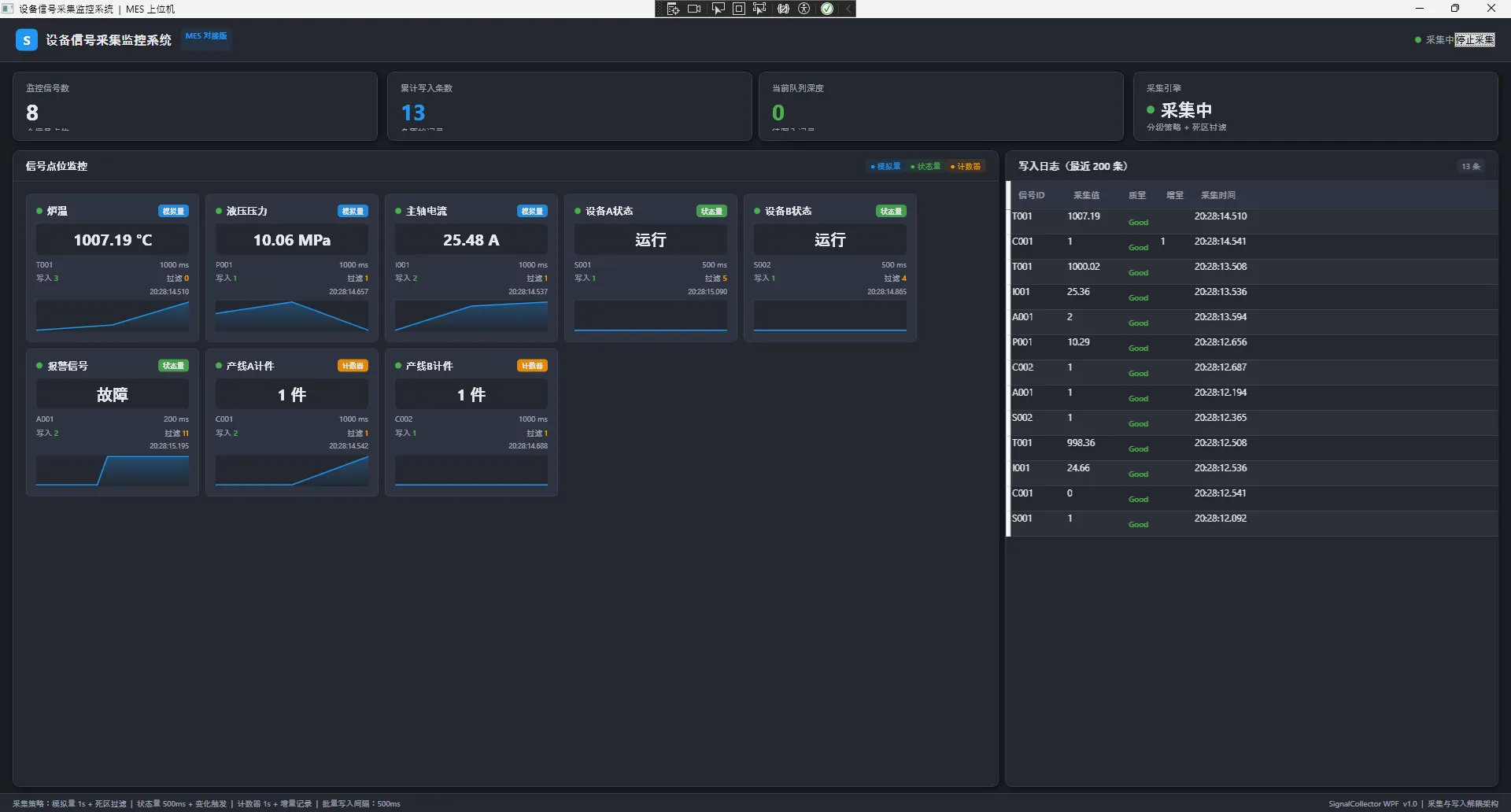
五、经验总结
可以直接拿去用的几条原则
-
先问业务,再定频率。 5 秒刷新的需求,不需要 100ms 采集。业务 SLA 是定频率的第一依据。
-
分级策略优于统一频率。 模拟量、状态量、计数器的特征不同,混在一起用同一频率是资源浪费。
-
死区过滤是模拟量采集的标配。 温度、压力这类信号有自然抖动,不加死区,写入量会膨胀 3–10 倍。
-
采集与写入必须解耦。 写入阻塞不能影响采集节奏,队列缓冲是基本架构。
-
把策略做成配置,不要硬编码。 现场调整频率是常态,改配置比改代码上线安全得多。
常见坑,提前规避
-
坑 1:用系统时间做
collected_at,忽略采集线程调度抖动。 建议在读取 PLC 数据的瞬间打时间戳,而不是入队或写库时。 -
坑 2:计数器只存当前值,不存增量。 断线重连后,计数器可能复位或跳变,只有增量才能还原真实产量。
-
坑 3:报警信号用轮询,漏掉短脉冲。 如果 PLC 报警持续时间短于轮询周期,必须改用锁存信号或中断机制。
-
坑 4:原始数据表无限增长,没有归档策略。 原始数据保留 7–30 天即可,超期数据应归档或删除,否则查询性能会持续劣化。
-
坑 5:频率调整没有灰度机制。 上线后如果需要调整采集频率,建议支持按设备分组热更新,避免全量重启影响生产。
下一步可以做什么
如果你的项目已经有基础的采集链路,下一步值得考虑的是:在原始数据层之上建一层聚合计算服务,把秒级原始数据聚合成分钟级、班次级的统计数据,让 MES 和报表系统直接消费聚合结果,而不是每次都去扫原始表。
这个话题涉及滑动窗口聚合、班次边界处理、断线补数等细节,可以作为下一篇的主题展开。
你在项目里遇到过类似的采集频率决策问题吗?欢迎在评论区分享你的实际做法,或者补充你在不同设备协议下的处理经验。
相关信息
通过网盘分享的文件:AppWpf202603.zip 链接: https://pan.baidu.com/s/14qXXoHg2f5gvM-D138KjKA?pwd=mz6k 提取码: mz6k --来自百度网盘超级会员v9的分享

本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!