
目录
🚀 开篇:数据分布的艺术
做了这么多年Python数据分析,我发现一个有趣的现象——90%的开发者在做数据分布可视化时,就知道画个直方图完事儿。但真正的数据洞察,往往藏在那些看似复杂的图表里。
就拿我上个月处理的一个用户行为数据来说吧,客户反馈"转化率不稳定",我用常规的均值分析,一切看起来都正常。直到我画出了箱线图——卧槽!数据里竟然有30%的异常值在捣鬼。这时候你就明白了:有时候,选对了图表类型,比写一万行代码还管用。
今天咱们就聊聊Matplotlib里两个被严重低估的可视化神器:箱线图(Box Plot)和小提琴图(Violin Plot)。掌握了这俩,你对数据分布的理解会上升一个档次。
📊 箱线图:五数概括的视觉化呈现
🎯 什么是箱线图?
箱线图,英文叫Box Plot,也有人叫它"盒须图"。这玩意儿的核心思想特别朴素:用五个数字概括整个数据集的分布特征。
这五个数字分别是:
- 最小值(Q0):非离群点的最小值
- 第一四分位数(Q1):25%的数据点
- 中位数(Q2):50%的数据点
- 第三四分位数(Q3):75%的数据点
- 最大值(Q4):非离群点的最大值
听起来很数学化?其实不然。想象一下,这就像是把一堆学生按身高排队,然后告诉你:"最矮的多高,最高的多高,中间那个多高,左边1/4和右边1/4的分界点分别多高。"
💻 基础箱线图绘制
咱们先来看看最基础的用法:
pythonimport matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use('TkAgg')
# 设置中文字体,避免乱码问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # Windows下显示中文
plt.rcParams['axes.unicode_minus'] = False
# 生成测试数据 - 模拟三个产品的用户评分
np.random.seed(42)
product_a = np.random.normal(4.2, 0.8, 200) # 均值4.2,标准差0.8
product_b = np.random.normal(3.8, 1.2, 180) # 均值3.8,标准差1.2
product_c = np.random.normal(4.0, 0.6, 220) # 均值4.0,标准差0.6
# 创建图表
fig, ax = plt.subplots(figsize=(10, 6))
# 绘制箱线图
box_data = [product_a, product_b, product_c]
boxes = ax.boxplot(box_data, labels=['产品A', '产品B', '产品C'],
patch_artist=True, notch=True)
# 美化样式
colors = ['lightblue', 'lightgreen', 'lightcoral']
for patch, color in zip(boxes['boxes'], colors):
patch.set_facecolor(color)
patch.set_alpha(0.7)
ax.set_ylabel('用户评分')
ax.set_title('三款产品用户评分分布对比', fontsize=14, fontweight='bold')
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
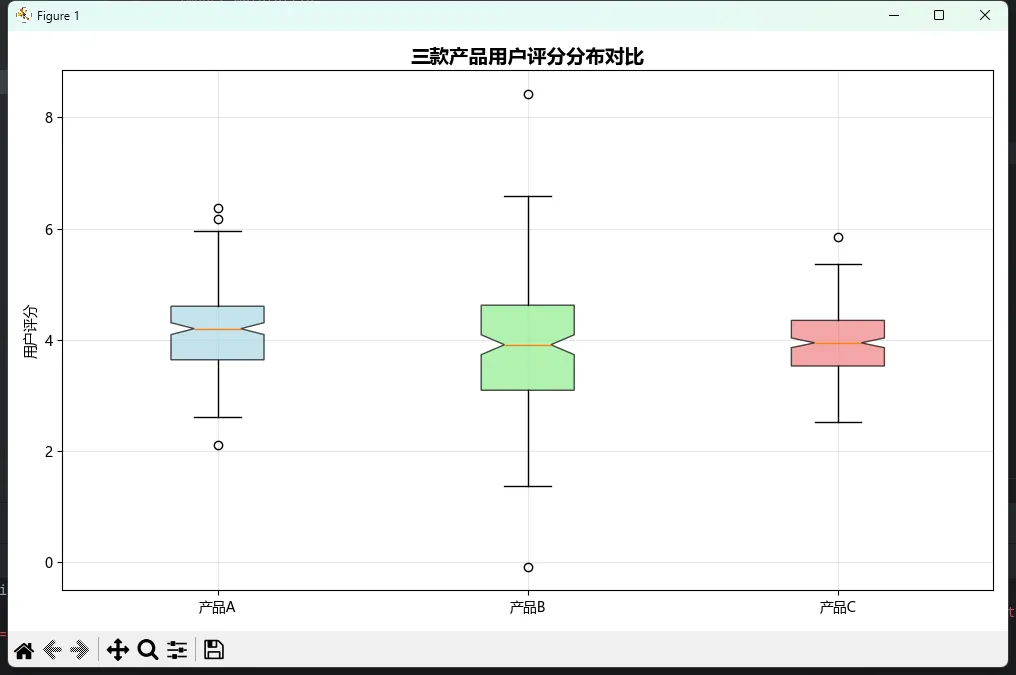
这段代码有几个细节值得注意:
notch=True参数:这会在中位数处画个缺口,让你更容易比较不同组的中位数差异patch_artist=True:允许我们自定义箱体颜色- 网格设置:
alpha=0.3让网格线更淡,不会抢夺主要信息的视觉焦点
🔍 进阶技巧:自定义箱线图样式
标准的箱线图有时候看起来有点死板。在实际项目中,我喜欢这样定制:
pythonimport matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use('TkAgg')
# 设置中文字体,避免乱码问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # Windows下显示中文
plt.rcParams['axes.unicode_minus'] = False
# 生成测试数据 - 模拟三个产品的用户评分
np.random.seed(42)
product_a = np.random.normal(4.2, 0.8, 200) # 均值4.2,标准差0.8
product_b = np.random.normal(3.8, 1.2, 180) # 均值3.8,标准差1.2
product_c = np.random.normal(4.0, 0.6, 220) # 均值4.0,标准差0.6
# 绘制箱线图
box_data = [product_a, product_b, product_c]
# 更精细的样式控制
fig, ax = plt.subplots(figsize=(12, 8))
# 自定义箱线图参数
boxprops = dict(linewidth=2, facecolor='lightblue', alpha=0.7)
whiskerprops = dict(linewidth=2, color='darkblue')
capprops = dict(linewidth=2, color='darkblue')
medianprops = dict(linewidth=3, color='red')
flierprops = dict(marker='o', markerfacecolor='red', markersize=8, alpha=0.5)
boxes = ax.boxplot(
box_data,
tick_labels=['产品A\n(n=200)', '产品B\n(n=180)', '产品C\n(n=220)'],
boxprops=dict(linewidth=2, color='darkblue'),
whiskerprops=whiskerprops,
capprops=capprops,
medianprops=medianprops,
flierprops=flierprops,
showmeans=True,
patch_artist=True # Enables filling the boxes
)
for box in boxes['boxes']:
box.set_facecolor('lightblue')
# 添加均值标记
meanprops = dict(marker='D', markeredgecolor='black', markerfacecolor='yellow', markersize=8)
ax.boxplot(box_data, labels=['', '', ''], showmeans=True, meanprops=meanprops)
ax.set_ylabel('用户评分', fontsize=12)
ax.set_title('产品评分分布详细对比\n(红线=中位数,黄菱形=均值,红点=离群值)',
fontsize=14, fontweight='bold')
# 添加统计信息文本
for i, data in enumerate(box_data):
stats_text = f'均值: {np.mean(data):.2f}\n标准差: {np.std(data):.2f}'
ax.text(i+1, np.max(data)+0.2, stats_text, ha='center', va='bottom',
bbox=dict(boxstyle='round,pad=0.3', facecolor='white', alpha=0.8))
plt.tight_layout()
plt.show()
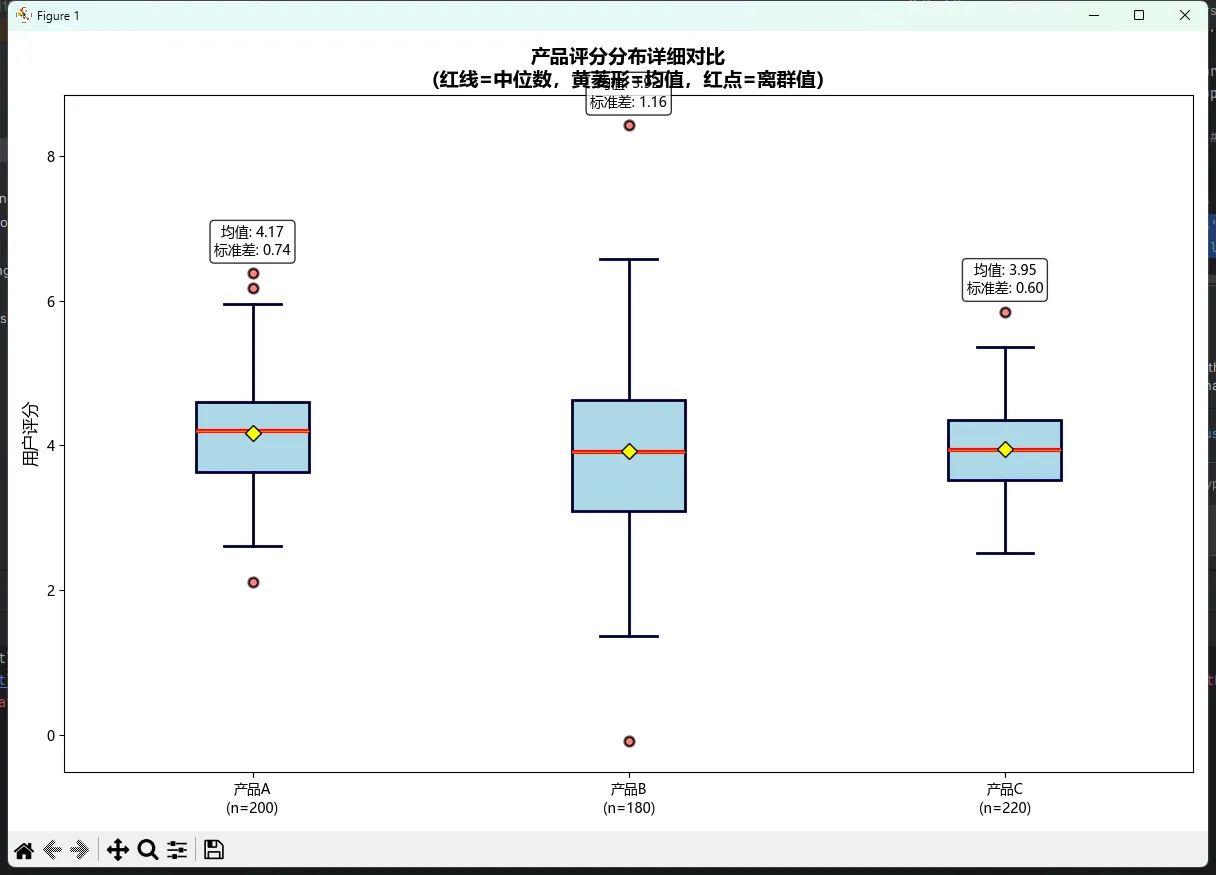
这个版本的亮点在于:
- 多层信息展示:中位数、均值、离群值都有不同的视觉标记
- 样本量标注:在标签中直接显示样本数量,这在实际汇报中很重要
- 统计摘要:直接在图上显示关键统计量,减少读者的认知负担
🎪 实战案例:网站性能监控数据分析
前段时间我们公司做网站性能优化,需要分析页面加载时间的分布。这种场景用箱线图就特别合适:
python# 模拟网站性能数据:不同时段的页面加载时间
np.random.seed(123)
morning_rush = np.random.exponential(2.5, 300) + 1.0 # 早高峰,基础1秒+指数分布
noon_time = np.random.normal(1.8, 0.4, 200) # 中午,正常分布
evening_rush = np.random.exponential(3.0, 350) + 1.2 # 晚高峰,更严重
midnight = np.random.normal(1.2, 0.3, 100) # 深夜,最快
# 创建水平箱线图 - 有时候这样更直观
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10))
# 垂直箱线图
time_periods = ['早高峰\n(8-10点)', '中午\n(12-14点)', '晚高峰\n(18-20点)', '深夜\n(0-2点)']
load_times = [morning_rush, noon_time, evening_rush, midnight]
boxes1 = ax1.boxplot(load_times, labels=time_periods, patch_artist=True)
colors = ['#ff9999', '#66b3ff', '#99ff99', '#ffcc99']
for patch, color in zip(boxes1['boxes'], colors):
patch.set_facecolor(color)
ax1.set_ylabel('页面加载时间(秒)')
ax1.set_title('网站性能:不同时段页面加载时间分布', fontsize=14, fontweight='bold')
ax1.grid(True, alpha=0.3)
# 水平箱线图 - 方便标注具体数值
boxes2 = ax2.boxplot(load_times, labels=time_periods, vert=False, patch_artist=True)
for patch, color in zip(boxes2['boxes'], colors):
patch.set_facecolor(color)
ax2.set_xlabel('页面加载时间(秒)')
ax2.set_title('水平视角:更容易读取具体数值', fontsize=14, fontweight='bold')
ax2.grid(True, alpha=0.3)
# 添加性能基准线
for ax in [ax1, ax2]:
if ax == ax1:
ax.axhline(y=3.0, color='red', linestyle='--', alpha=0.7, label='性能警戒线(3秒)')
ax.legend()
else:
ax.axvline(x=3.0, color='red', linestyle='--', alpha=0.7, label='性能警戒线(3秒)')
ax.legend()
plt.tight_layout()
plt.show()
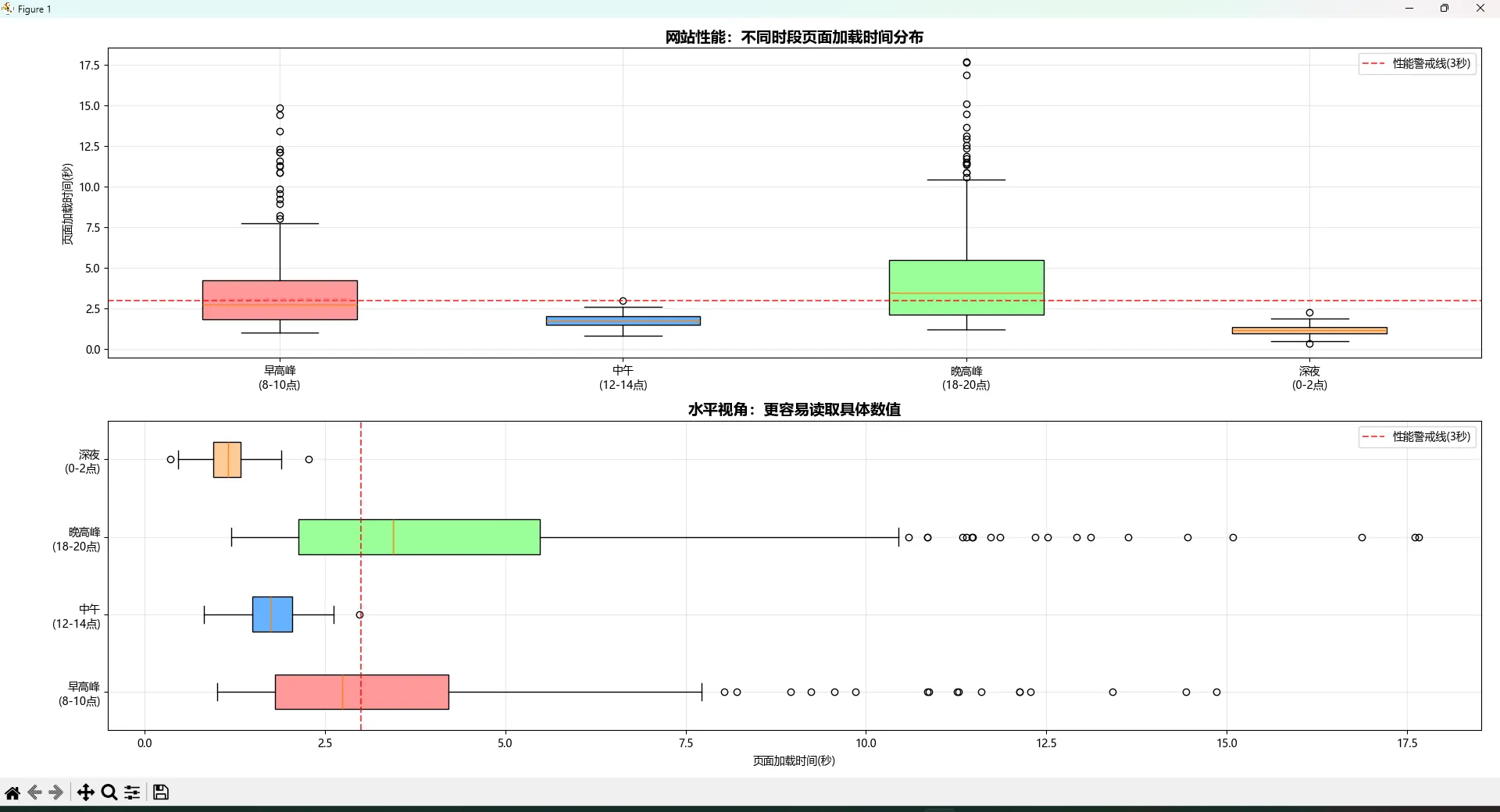
这个例子展示了箱线图在实际业务分析中的威力:
- 异常值检测:一眼就能看出哪些时段有极端的加载时间
- 分布比较:不同时段的性能差异一目了然
- 业务决策支持:结合业务基准线,立即知道哪个时段需要重点优化
🎻 小提琴图:分布密度的优雅展示
🎨 从箱线图到小提琴图的进化
如果说箱线图是数据分布的"素描",那小提琴图就是"油画"。箱线图只告诉你五个关键点,而小提琴图能展示整个分布的形状。
想象一下,你有两组数据,均值和四分位数都差不多,但一个是正态分布,另一个是双峰分布。箱线图看起来几乎一样,但小提琴图会立刻暴露这个差异。
💻 基础小提琴图实现
python# 生成更有趣的测试数据
np.random.seed(42)
# 单峰分布
normal_data = np.random.normal(50, 15, 1000)
# 双峰分布
bimodal_data = np.concatenate([
np.random.normal(30, 8, 500),
np.random.normal(70, 8, 500)
])
# 偏态分布
skewed_data = np.random.exponential(10, 1000) + 20
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 箱线图对比
box_data = [normal_data, bimodal_data, skewed_data]
ax1.boxplot(box_data, labels=['正态分布', '双峰分布', '偏态分布'])
ax1.set_title('箱线图:分布差异不明显', fontsize=12, fontweight='bold')
ax1.set_ylabel('数值')
# 小提琴图对比
parts = ax2.violinplot(box_data, positions=[1, 2, 3], showmeans=True, showextrema=True)
ax2.set_xticks([1, 2, 3])
ax2.set_xticklabels(['正态分布', '双峰分布', '偏态分布'])
ax2.set_title('小提琴图:分布形状一目了然', fontsize=12, fontweight='bold')
ax2.set_ylabel('数值')
# 美化小提琴图
for pc in parts['bodies']:
pc.set_facecolor('lightblue')
pc.set_alpha(0.7)
plt.tight_layout()
plt.show()
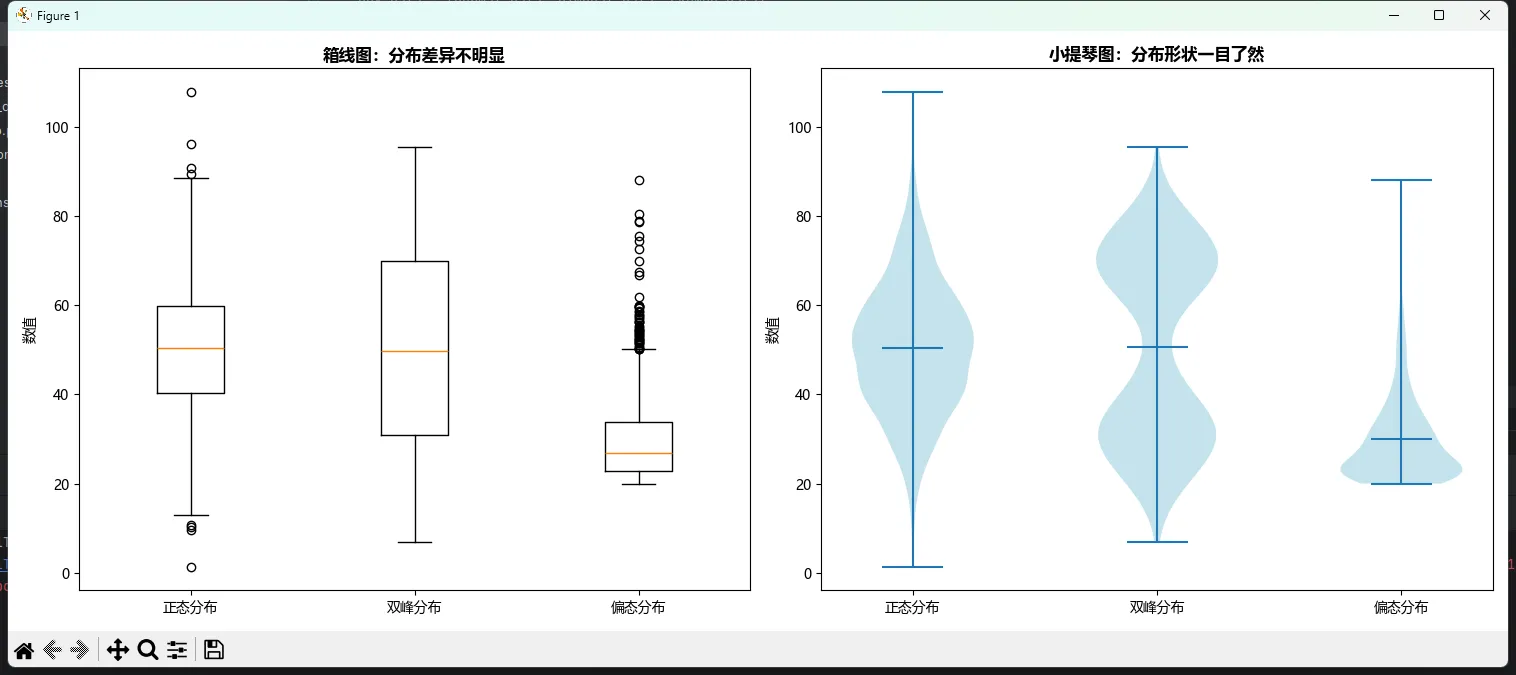 看到差别了吗?小提琴图立刻就能看出:
看到差别了吗?小提琴图立刻就能看出:
- 第一个是经典的正态分布(中间宽、两边窄)
- 第二个明显是双峰(中间窄、两边各有一个凸起)
- 第三个是典型的右偏分布(左边窄、右边拖着长尾巴)
🎪 高级技巧:组合图表的威力
在实际项目中,我经常把箱线图和小提琴图结合起来用:
python# 创建组合可视化
fig, ax = plt.subplots(figsize=(12, 8))
# 先画小提琴图(作为背景)
violin_parts = ax.violinplot(box_data, positions=[1, 2, 3],
showmeans=False, showextrema=False, showmedians=False)
# 设置小提琴图样式
colors = ['#ff9999', '#66b3ff', '#99ff99']
for pc, color in zip(violin_parts['bodies'], colors):
pc.set_facecolor(color)
pc.set_alpha(0.3)
# 在小提琴图上叠加箱线图
box_parts = ax.boxplot(box_data, positions=[1, 2, 3],
widths=0.3, patch_artist=True,
boxprops=dict(facecolor='white', alpha=0.8, linewidth=2),
medianprops=dict(color='red', linewidth=3))
ax.set_xticks([1, 2, 3])
ax.set_xticklabels(['正态分布', '双峰分布', '偏态分布'])
ax.set_title('组合图表:小提琴图展示分布形状 + 箱线图显示关键统计量',
fontsize=14, fontweight='bold')
ax.set_ylabel('数值')
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
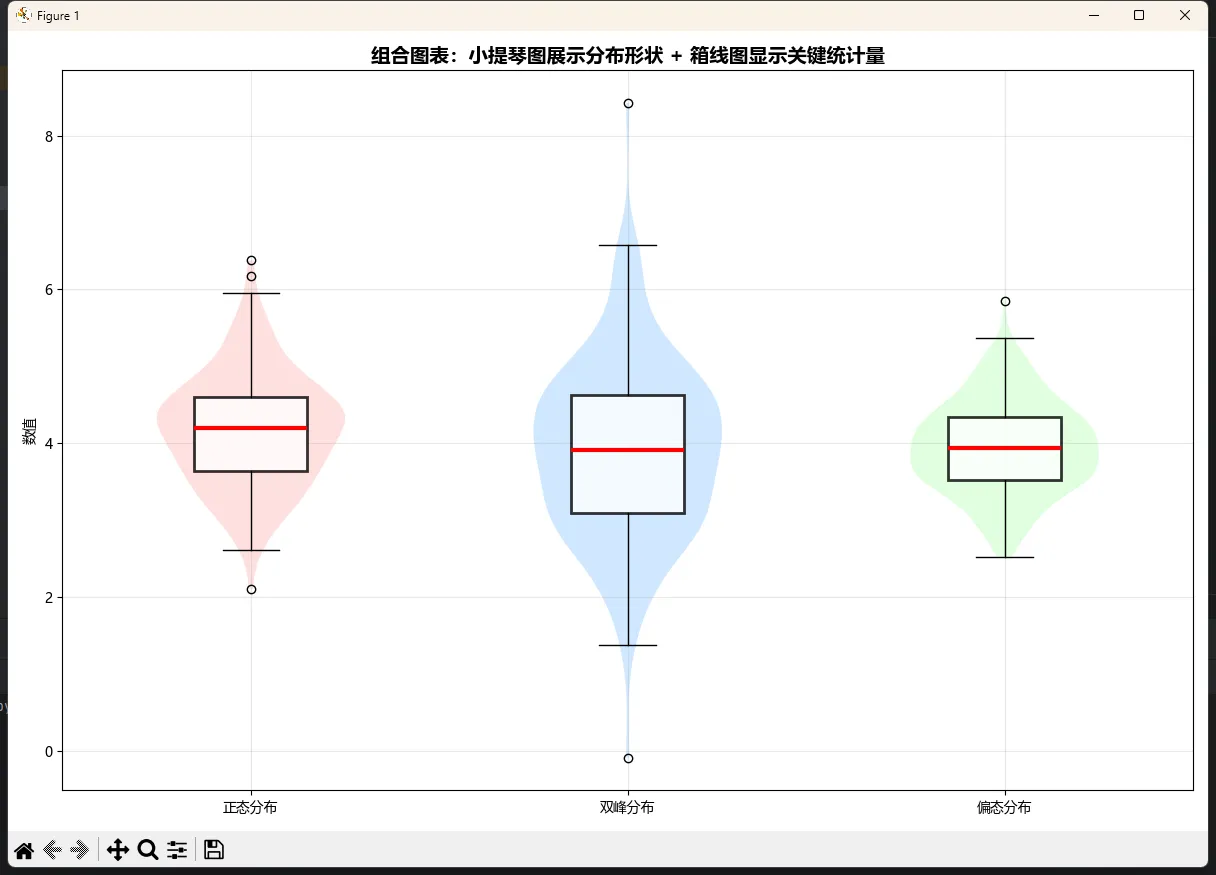
这种组合有个巨大的优势:既能看到分布的完整形状,又不丢失关键的统计信息。在项目汇报时,这种图表往往最受欢迎。
🚀 实战案例:用户留存率分析
最近我用这个组合图分析了一个APP的用户留存问题,效果特别好:
python# 模拟用户留存率数据:不同获客渠道的7日留存率
np.random.seed(456)
# 有机增长用户:留存率相对稳定
organic_retention = np.random.beta(8, 3, 500) * 100 # Beta分布模拟留存率
# 广告投放用户:留存率两极分化严重
ads_retention = np.concatenate([
np.random.beta(2, 8, 300) * 100, # 低留存群体
np.random.beta(9, 2, 200) * 100 # 高留存群体
])
# 推荐用户:留存率普遍较高但有一定波动
referral_retention = np.random.beta(7, 2, 400) * 100
retention_data = [organic_retention, ads_retention, referral_retention]
channel_names = ['有机增长', '广告投放', '好友推荐']
# 创建专业的分析图表
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10))
# 上图:小提琴图显示分布密度
violin_parts = ax1.violinplot(retention_data, positions=[1, 2, 3])
colors = ['#2E8B57', '#FF6347', '#4169E1']
for pc, color in zip(violin_parts['bodies'], colors):
pc.set_facecolor(color)
pc.set_alpha(0.6)
ax1.set_xticks([1, 2, 3])
ax1.set_xticklabels(channel_names)
ax1.set_ylabel('7日留存率 (%)')
ax1.set_title('不同获客渠道用户留存率分布密度分析', fontsize=14, fontweight='bold')
ax1.grid(True, alpha=0.3)
# 下图:组合图表提供完整信息
violin_parts2 = ax2.violinplot(retention_data, positions=[1, 2, 3],
showmeans=False, showextrema=False, showmedians=False)
for pc, color in zip(violin_parts2['bodies'], colors):
pc.set_facecolor(color)
pc.set_alpha(0.3)
# 叠加箱线图
box_parts = ax2.boxplot(retention_data, positions=[1, 2, 3], widths=0.2,
patch_artist=True,
boxprops=dict(facecolor='white', alpha=0.9, linewidth=2))
# 添加业务基准线
ax2.axhline(y=30, color='red', linestyle='--', alpha=0.7, label='行业平均水平(30%)')
ax2.axhline(y=50, color='green', linestyle='--', alpha=0.7, label='优秀水平(50%)')
ax2.set_xticks([1, 2, 3])
ax2.set_xticklabels(channel_names)
ax2.set_ylabel('7日留存率 (%)')
ax2.set_title('获客渠道留存率对比:分布形状 + 关键统计量', fontsize=14, fontweight='bold')
ax2.legend()
ax2.grid(True, alpha=0.3)
# 添加数据洞察文本
insights = [
f"有机用户:稳定的单峰分布\n中位数: {np.median(organic_retention):.1f}%",
f"广告用户:明显双峰分布\n需要精准定向优化\n中位数: {np.median(ads_retention):.1f}%",
f"推荐用户:高留存偏态分布\n表现最优\n中位数: {np.median(referral_retention):.1f}%"
]
for i, insight in enumerate(insights):
ax2.text(i+1, 85, insight, ha='center', va='top',
bbox=dict(boxstyle='round,pad=0.5', facecolor='white', alpha=0.8),
fontsize=9)
plt.tight_layout()
plt.show()
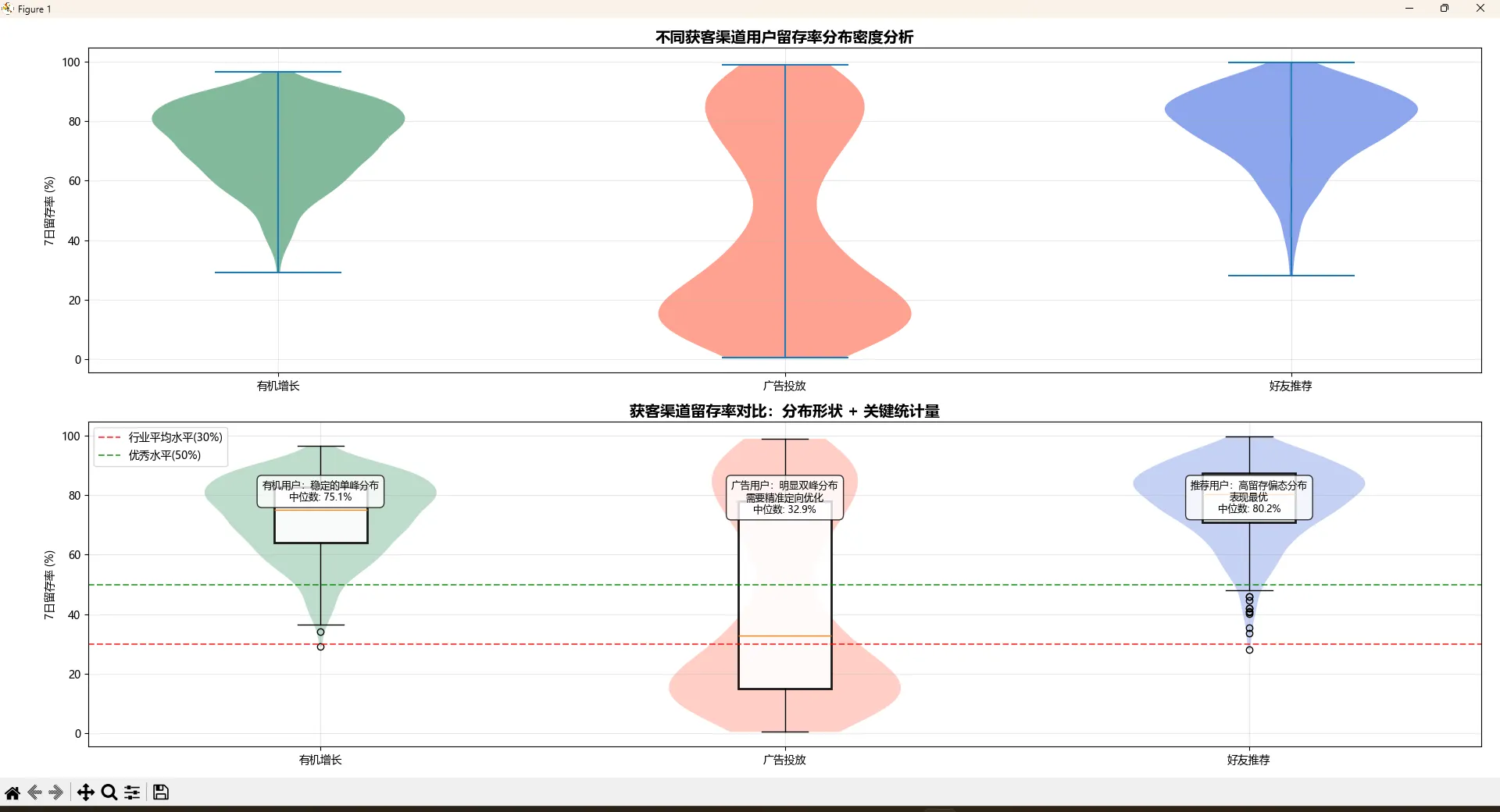
这个分析一出来,产品经理立马就明白问题所在了:
- 有机用户:留存率分布很稳定,说明产品本身有一定吸引力
- 广告用户:双峰分布暴露了精准投放的问题,需要优化投放策略
- 推荐用户:高留存的偏态分布证明了口碑传播的价值
🎯 性能优化与最佳实践
⚡ 大数据量场景的优化技巧
当数据量很大时(比如百万级),直接画小提琴图会很慢。这时候有几个优化技巧:
pythonimport numpy as np
# 处理大数据量的优化策略
def optimize_large_dataset(data, sample_size=10000):
"""
对大数据集进行智能采样
""" if len(data) <= sample_size:
return data
# 分层采样:保留异常值 + 随机采样
q1, q3 = np.percentile(data, [25, 75])
iqr = q3 - q1
outliers = data[(data < q1 - 1.5 * iqr) | (data > q3 + 1.5 * iqr)]
normal_data = data[(data >= q1 - 1.5 * iqr) & (data <= q3 + 1.5 * iqr)]
# 保留所有异常值,对正常数据随机采样
normal_sample_size = max(0, sample_size - len(outliers)) # Ensure non-negative size
normal_sample = np.random.choice(normal_data, normal_sample_size, replace=False)
return np.concatenate([outliers, normal_sample])
# 模拟大数据集
large_dataset = np.random.exponential(2, 1000000)
optimized_data = optimize_large_dataset(large_dataset)
print(f"原始数据量: {len(large_dataset):,}")
print(f"优化后数据量: {len(optimized_data):,}")
print(f"异常值保留: {len(optimized_data[optimized_data > np.percentile(large_dataset, 95)])}")
🚨 常见陷阱与规避策略
在实际使用中,我踩过不少坑,总结几个常见的:
陷阱1:数据量差异巨大时的误导
python# 错误示例:样本量差异巨大
small_sample = np.random.normal(5, 1, 20) # 20个样本
large_sample = np.random.normal(5, 1, 2000) # 2000个样本
# 小样本的置信区间会很宽,容易误导
# 解决方案:在标签中标注样本量
labels = [f'小样本组\n(n={len(small_sample)})', f'大样本组\n(n={len(large_sample)})']
陷阱2:离群值处理不当
python# 正确的离群值处理
def handle_outliers(data, method='iqr', threshold=1.5):
"""
智能处理离群值
"""
if method == 'iqr':
q1, q3 = np.percentile(data, [25, 75])
iqr = q3 - q1
lower_bound = q1 - threshold * iqr
upper_bound = q3 + threshold * iqr
# 不是直接删除,而是标记
outlier_mask = (data < lower_bound) | (data > upper_bound)
return data, outlier_mask
return data, np.zeros(len(data), dtype=bool)
🎪 综合实战:电商数据分析项目
最后,让咱们来个综合案例,把今天学的技巧都用上:
pythonimport matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from matplotlib.patches import Rectangle
import seaborn as sns
import matplotlib
matplotlib.use('TkAgg')
# 设置全局样式
plt.style.use('seaborn-v0_8-darkgrid')
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # Windows下显示中文
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.facecolor'] = 'white'
# 生成电商模拟数据
np.random.seed(888)
# 商品类别销售数据
electronics_sales = np.random.lognormal(8, 1.2, 500) # 电子产品:高价值,长尾分布
clothing_sales = np.random.normal(300, 150, 800) # 服装:正态分布
books_sales = np.random.exponential(80, 600) + 20 # 图书:低价值,指数分布
# 用户购买频次数据(明显的双峰:偶尔购买 vs 忠实用户)
casual_buyers = np.random.poisson(2, 1000) # 偶尔买家
loyal_buyers = np.random.poisson(15, 300) + 10 # 忠实用户
purchase_frequency = np.concatenate([casual_buyers, loyal_buyers])
# 营销渠道转化率数据
social_media = np.random.beta(3, 7, 400) * 100 # 社交媒体:转化率偏低
search_engine = np.random.normal(12, 4, 450) # 搜索引擎:稳定转化
email_marketing = np.random.gamma(3, 3, 350) # 邮件营销:右偏分布
# 创建综合分析仪表板
fig = plt.figure(figsize=(18, 12))
gs = fig.add_gridspec(3, 3, height_ratios=[1, 1, 1], width_ratios=[1, 1, 1])
# 图表1:商品类别销售额分布箱线图
ax1 = fig.add_subplot(gs[0, :2])
sales_data = [electronics_sales, clothing_sales, books_sales]
categories = ['电子产品', '服装配饰', '图书文具']
box1 = ax1.boxplot(sales_data, labels=categories, patch_artist=True, notch=True)
colors1 = ['#FF6B6B', '#4ECDC4', '#45B7D1']
for patch, color in zip(box1['boxes'], colors1):
patch.set_facecolor(color)
patch.set_alpha(0.7)
ax1.set_ylabel('销售额 (元)', fontsize=12)
ax1.set_title('🛒 商品类别销售额分布对比', fontsize=14, fontweight='bold', pad=15)
ax1.grid(True, alpha=0.3)
# 添加销售额统计
for i, data in enumerate(sales_data):
median_val = np.median(data)
ax1.annotate(f'中位数: ¥{median_val:.0f}',
xy=(i + 1, median_val), xytext=(i + 1, median_val + 500),
ha='center', fontsize=10,
bbox=dict(boxstyle='round,pad=0.3', facecolor='white', alpha=0.8),
arrowprops=dict(arrowstyle='->', color='red', alpha=0.7))
# 图表2:用户购买频次分布小提琴图
ax2 = fig.add_subplot(gs[0, 2])
violin2 = ax2.violinplot([purchase_frequency], positions=[1], showmeans=True, showextrema=True)
violin2['bodies'][0].set_facecolor('#9B59B6')
violin2['bodies'][0].set_alpha(0.7)
ax2.set_xticks([1])
ax2.set_xticklabels(['用户购买频次'])
ax2.set_ylabel('月购买次数', fontsize=12)
ax2.set_title('📊 用户购买行为分布密度', fontsize=14, fontweight='bold', pad=15)
ax2.grid(True, alpha=0.3)
# 标注双峰特征
ax2.annotate('偶尔购买用户\n(低频峰)', xy=(1.15, 5), xytext=(1.3, 8),
arrowprops=dict(arrowstyle='->', color='blue'),
fontsize=10, ha='center')
ax2.annotate('忠实用户\n(高频峰)', xy=(0.85, 20), xytext=(0.7, 25),
arrowprops=dict(arrowstyle='->', color='red'),
fontsize=10, ha='center')
# 图表3:营销渠道转化率组合图
ax3 = fig.add_subplot(gs[1, :2])
conversion_data = [social_media, search_engine, email_marketing]
channel_names = ['社交媒体', '搜索引擎', '邮件营销']
# 先画小提琴图
violin3 = ax3.violinplot(conversion_data, positions=[1, 2, 3],
showmeans=False, showextrema=False, showmedians=False)
colors3 = ['#E74C3C', '#2ECC71', '#F39C12']
for pc, color in zip(violin3['bodies'], colors3):
pc.set_facecolor(color)
pc.set_alpha(0.3)
# 叠加箱线图
box3 = ax3.boxplot(conversion_data, positions=[1, 2, 3], widths=0.3,
patch_artist=True,
boxprops=dict(facecolor='white', alpha=0.8, linewidth=2))
ax3.set_xticks([1, 2, 3])
ax3.set_xticklabels(channel_names)
ax3.set_ylabel('转化率 (%)', fontsize=12)
ax3.set_title('📈 营销渠道转化率分布分析', fontsize=14, fontweight='bold', pad=15)
ax3.grid(True, alpha=0.3)
# 添加行业基准线
ax3.axhline(y=10, color='red', linestyle='--', alpha=0.7, label='行业平均(10%)')
ax3.legend()
# 图表4:综合性能指标雷达风格展示
ax4 = fig.add_subplot(gs[1, 2])
metrics = ['销售额', '用户活跃度', '转化率', '客户满意度', '复购率']
values = [85, 72, 68, 91, 76] # 模拟综合评分
bars = ax4.barh(metrics, values, color=['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4', '#FFEAA7'])
ax4.set_xlim(0, 100)
ax4.set_xlabel('综合评分', fontsize=12)
ax4.set_title('📋 关键业务指标概览', fontsize=14, fontweight='bold', pad=15)
# 添加数值标签
for i, v in enumerate(values):
ax4.text(v + 2, i, f'{v}分', va='center', fontweight='bold')
# 添加评分区间背景
ax4.axvspan(0, 60, alpha=0.1, color='red', label='待改进')
ax4.axvspan(60, 80, alpha=0.1, color='yellow', label='良好')
ax4.axvspan(80, 100, alpha=0.1, color='green', label='优秀')
# 图表5:时间序列性能监控
ax5 = fig.add_subplot(gs[2, :])
days = np.arange(1, 31)
page_load_times = []
for day in days:
# 模拟不同时期的性能表现
if day < 10: # 初期性能较差
daily_loads = np.random.normal(2.5, 0.8, 100)
elif day < 20: # 中期优化后改善
daily_loads = np.random.normal(1.8, 0.5, 100)
else: # 后期进一步优化
daily_loads = np.random.normal(1.2, 0.3, 100)
page_load_times.append(daily_loads)
# 水平箱线图显示每日性能分布
box5 = ax5.boxplot(page_load_times, vert=False, patch_artist=True)
for i, patch in enumerate(box5['boxes']):
if i < 10:
patch.set_facecolor('#FF6B6B') # 红色表示性能差
elif i < 20:
patch.set_facecolor('#F39C12') # 橙色表示改善中
else:
patch.set_facecolor('#2ECC71') # 绿色表示性能好
ax5.set_xlabel('页面加载时间 (秒)', fontsize=12)
ax5.set_ylabel('日期 (天)', fontsize=12)
ax5.set_title('⚡ 30天页面性能优化追踪', fontsize=14, fontweight='bold', pad=15)
ax5.axvline(x=3.0, color='red', linestyle='--', alpha=0.7, label='性能警戒线(3秒)')
ax5.legend()
ax5.grid(True, alpha=0.3)
# 添加优化阶段标注
ax5.annotate('性能优化前', xy=(2.5, 5), xytext=(4, 8),
arrowprops=dict(arrowstyle='->', color='red'),
fontsize=10, bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))
ax5.annotate('第一轮优化', xy=(1.8, 15), xytext=(3.5, 18),
arrowprops=dict(arrowstyle='->', color='orange'),
fontsize=10, bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))
ax5.annotate('深度优化后', xy=(1.2, 25), xytext=(3, 28),
arrowprops=dict(arrowstyle='->', color='green'),
fontsize=10, bbox=dict(boxstyle='round', facecolor='white', alpha=0.8))
plt.tight_layout(pad=2.0)
plt.suptitle('🚀 电商平台数据分析综合仪表板', fontsize=18, fontweight='bold', y=0.98)
plt.show()
# 生成数据洞察报告
print("=" * 60)
print("📊 数据分析洞察报告")
print("=" * 60)
print(f"\n🛒 商品销售分析:")
print(f"• 电子产品: 高价值长尾分布,中位数¥{np.median(electronics_sales):.0f}")
print(f"• 服装配饰: 稳定正态分布,中位数¥{np.median(clothing_sales):.0f}")
print(f"• 图书文具: 低价高频,中位数¥{np.median(books_sales):.0f}")
print(f"\n👥 用户行为洞察:")
print(f"• 双峰分布明显:偶尔购买用户 vs 忠实用户")
print(f"• 忠实用户占比: {len(loyal_buyers) / (len(loyal_buyers) + len(casual_buyers)) * 100:.1f}%")
print(f"• 平均购买频次: {np.mean(purchase_frequency):.1f}次/月")
print(f"\n📈 营销效果评估:")
for i, (channel, data) in enumerate(zip(channel_names, conversion_data)):
print(f"• {channel}: 平均转化率{np.mean(data):.1f}%,标准差{np.std(data):.1f}%")
print(f"\n⚡ 性能优化成果:")
initial_performance = np.mean([np.mean(loads) for loads in page_load_times[:10]])
final_performance = np.mean([np.mean(loads) for loads in page_load_times[-10:]])
improvement = (initial_performance - final_performance) / initial_performance * 100
print(f"• 页面加载时间优化: {improvement:.1f}% 提升")
print(f"• 从 {initial_performance:.2f}秒 降至 {final_performance:.2f}秒")
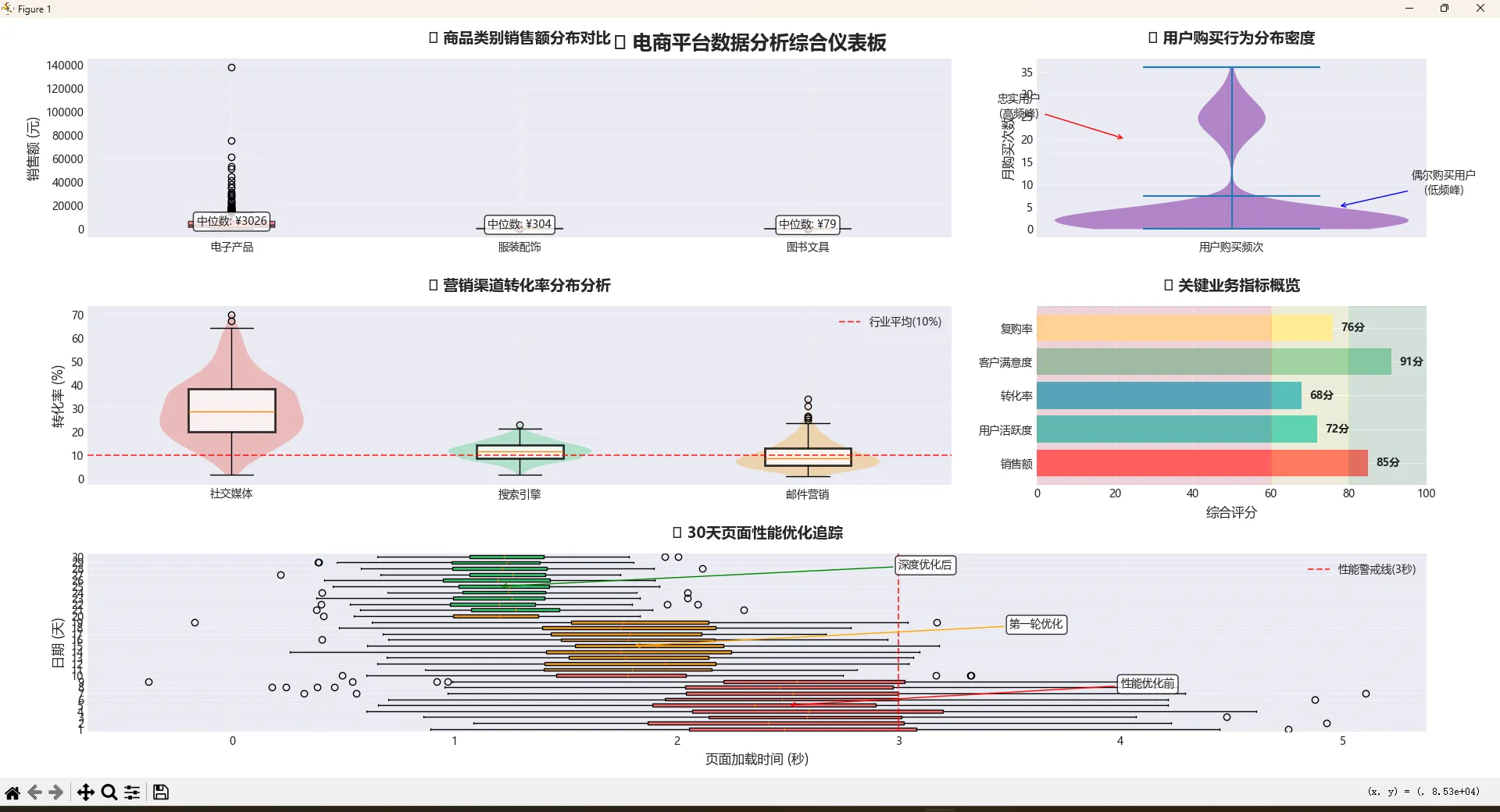
这个综合案例展示了箱线图和小提琴图在实际业务分析中的强大威力:
🎯 业务价值体现:
- 销售策略优化:通过分布分析发现电子产品的长尾特征,指导定价策略
- 用户分层运营:识别出双峰分布的用户购买行为,制定差异化营销策略
- 渠道资源配置:基于转化率分布调整营销预算分配
- 性能监控预警:通过时间序列箱线图及时发现性能异常
🚀 技术亮点总结:
- 多维度对比:同时展示分布形状、关键统计量、异常值检测
- 交互式洞察:结合业务基准线,快速识别问题和机会点
- 可视化叙事:通过颜色、标注、分区域展示完整的数据故事
🎉 写在最后:数据可视化的艺术与科学
经过这么长篇幅的探讨,相信你已经对箱线图和小提琴图有了全新的认识。让我用三句话总结今天的核心收获:
第一,选对图表类型比写一万行代码更重要。 当你需要比较分布差异时,别再傻傻地只用均值了——箱线图能告诉你分布的骨架,小提琴图能展示分布的血肉。
第二,组合使用威力更大。 单独的箱线图或小提琴图都有局限性,但当你把它们组合起来时,就能既看到分布的完整形状,又不丢失关键的统计信息。这在项目汇报时特别受用。
第三,可视化不是为了炫技,而是为了洞察。 最好的图表不是最复杂的,而是最能帮助你发现数据背后故事的。记住,我们的目标是让数据说话,而不是让图表说话。
🚀 进阶学习路线图
如果你想在数据可视化这条路上走得更远,建议按这个顺序深入:
- 掌握基础统计概念:理解分位数、置信区间、假设检验
- 学习更多Matplotlib技巧:自定义主题、动画制作、交互功能
- 探索其他可视化库:Plotly(交互图表)、Bokeh(Web可视化)
- 业务领域深耕:结合具体行业需求,形成专业的分析框架
💡 最后的一点建议
在实际项目中使用这些技术时,记住几个原则:
- 先理解业务问题,再选择可视化方案
- 让图表为决策服务,而不是为了展示技术
- 保持学习心态,数据可视化的技术在不断演进
希望这篇文章能成为你数据可视化工具箱里的一件趁手兵器。下次再遇到分布分析的需求时,试试今天学到的技巧——相信我,你的同事会对你刮目相看的!
关键技术标签: #Python #Matplotlib #数据可视化 #统计分析 #业务智能
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!