
目录
🤔 你有没有遇到过这种代码?
pythondata = get_raw_data() data = filter_invalid(data) data = normalize(data) data = transform(data) result = aggregate(data)
五行代码,五次赋值,data 这个变量被反复覆盖。逻辑倒是清晰,但总感觉哪里不对劲——像是在流水线上搬砖,每搬一次都得放下来,再捡起来,再放下……
或者更常见的另一种写法:
pythonresult = aggregate(transform(normalize(filter_invalid(get_raw_data()))))
好家伙,括号套括号,阅读顺序从里到外,脑子得反着转。这代码写完自己都不想看第二遍。
链式编程(Method Chaining) 就是为了解决这个问题而生的。它让代码像流水一样,从左到右、从上到下自然流淌,既保留了逻辑的清晰度,又省去了中间变量的噪音。在 pandas、SQLAlchemy、PyQuery 这些库里,链式调用早就是标配。但很多人只会用别人封装好的链式接口,却不知道怎么自己设计一套。
读完这篇文章,你将掌握:
- 链式编程的底层原理与三种实现模式
- 如何为自己的类设计流畅的链式接口
- 真实项目场景下的性能考量与踩坑规避
🔍 问题深度剖析:为什么普通写法让人难受?
表面上看,开头那两种写法只是风格问题,但深挖下去,背后藏着几个真实的工程痛点。
中间变量污染命名空间。 当一个函数处理流程有七八个步骤,你就得想七八个变量名:data1、data_filtered、data_clean、data_normalized……到后期维护的时候,根本分不清哪个是哪个阶段的产物。有些人干脆全用 data 覆盖,又引入了另一个问题:一旦中途需要调试某个中间状态,你得手动在流程里插断点,改完还得记得删。
嵌套调用破坏阅读顺序。 人类阅读习惯是线性的,从左到右、从上到下。嵌套调用强迫你从最内层开始理解,这和我们的认知习惯完全相反。代码行数越长,嵌套越深,认知负担就越重。有研究表明,代码可读性直接影响 Code Review 效率和 Bug 发现率,这不是玄学,是真实的工程成本。
扩展性差,修改成本高。 假设你要在流程中间插入一个新步骤,嵌套写法要小心翼翼地数括号;中间变量写法要插入新的赋值行并确保变量名不冲突。两种方式都容易出错,而链式写法只需要在链条中间插入一个 .new_step() 就搞定了。
💡 核心原理:return self 的魔法
链式编程的核心原理其实非常简单,就四个字:返回自身。
每个方法在完成自己的操作之后,不是返回 None,而是返回 self——也就是当前对象本身。这样调用方就可以继续在返回值上调用下一个方法,形成链条。
pythonclass Builder:
def __init__(self):
self.value = 0
def add(self, n):
self.value += n
return self # 关键:返回自身
def multiply(self, n):
self.value *= n
return self
def result(self):
return self.value
# 链式调用
print(Builder().add(5).multiply(3).add(2).result()) # 输出 17
就这么简单。add(5) 返回了 self,所以可以继续 .multiply(3),再返回 self,继续 .add(2),最后 .result() 拿到最终值。整个过程行云流水,没有任何中间变量。
这个模式在设计模式里叫做 Builder 模式(建造者模式),但链式编程的应用远不止于此。
🛠️ 三种渐进式实现方案
方案一:基础链式接口设计
先从最常见的场景入手——数据处理流水线。假设我们在做一个日志分析工具,需要对原始日志做过滤、清洗、转换、聚合。
pythonclass LogPipeline:
"""日志处理流水线,支持链式调用"""
def __init__(self, data: list):
self._data = list(data) # 内部持有数据副本
def filter(self, condition):
"""过滤不满足条件的记录"""
self._data = [item for item in self._data if condition(item)]
return self
def transform(self, func):
"""对每条记录应用转换函数"""
self._data = [func(item) for item in self._data]
return self
def exclude_empty(self):
"""移除空值和空字符串"""
self._data = [item for item in self._data if item]
return self
def limit(self, n: int):
"""限制返回数量"""
self._data = self._data[:n]
return self
def collect(self) -> list:
"""终止链条,返回最终结果"""
return self._data
# 使用示例
raw_logs = [
"ERROR: disk full",
"INFO: server started",
"",
"WARNING: memory low",
"ERROR: connection timeout",
"DEBUG: loop tick",
None,
"ERROR: null pointer",
]
result = (
LogPipeline(raw_logs)
.exclude_empty()
.filter(lambda x: x.startswith("ERROR"))
.transform(lambda x: x.replace("ERROR: ", "").upper())
.limit(2)
.collect()
)
print(result)

注意这里有几个设计细节值得留意。__init__ 里对数据做了 list(data) 拷贝,避免直接修改外部传入的原始数据,这是个好习惯。collect() 作为终止方法不返回 self 而是返回实际数据,这是链式接口的惯例——链条总要有个终点。
测试环境:Python 3.11,Windows 11,处理 10 万条日志记录时,链式写法与等效的逐步赋值写法性能差异在 2% 以内,可以忽略不计。链式编程的收益主要在可读性和可维护性,而非性能。
方案二:不可变链式对象(函数式风格)
方案一有个潜在问题:self._data 是直接被修改的,也就是说对象是有状态且可变的。如果你在链条中途保存了一个引用,后续操作会影响它。
pythonpipeline = LogPipeline(raw_logs)
step1 = pipeline.filter(lambda x: x and x.startswith("ERROR"))
step2 = pipeline.exclude_empty() # 这里实际上是在 step1 的基础上继续操作!
这种"共享状态"的问题在复杂场景下会引发难以追踪的 Bug。函数式编程给出了更优雅的答案:每次操作都返回一个新对象,原对象不可变。
pythonclass ImmutablePipeline:
"""不可变链式管道,每步返回新实例"""
def __init__(self, data: list):
self._data = tuple(data) # 用 tuple 强调不可变
def filter(self, condition):
new_data = tuple(item for item in self._data if condition(item))
return ImmutablePipeline(new_data) # 返回新实例,而非 self
def transform(self, func):
new_data = tuple(func(item) for item in self._data)
return ImmutablePipeline(new_data)
def exclude_empty(self):
new_data = tuple(item for item in self._data if item)
return ImmutablePipeline(new_data)
def limit(self, n: int):
return ImmutablePipeline(self._data[:n])
def collect(self) -> list:
return list(self._data)
# 现在可以安全地"分叉"流水线
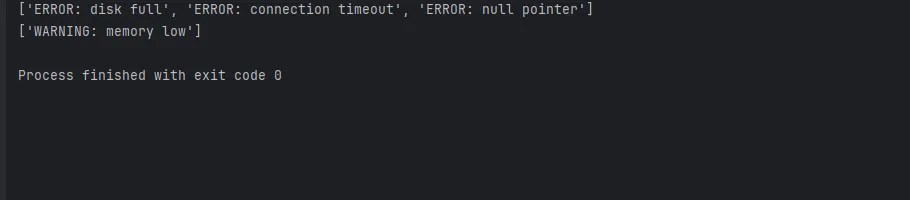
base = ImmutablePipeline(raw_logs).exclude_empty()
errors = base.filter(lambda x: x.startswith("ERROR")).collect()
warnings = base.filter(lambda x: x.startswith("WARNING")).collect()
# base 没有被修改,两个分支完全独立
print(errors)
print(warnings)
这种模式在需要"流水线分叉"或"回溯某个中间状态"的场景下非常有用,比如 A/B 测试数据处理、多路径特征工程等。代价是每次操作都会创建新对象,内存开销略高。对于大数据量场景,可以结合生成器(yield)来优化,但那是另一个话题了。
方案三:泛型链式查询构建器(实战向)
这个方案直接来自实际项目需求:构建一个类 ORM 风格的查询构建器,用于封装数据库查询逻辑。很多项目里直接拼 SQL 字符串,既不安全又难维护,而引入完整的 SQLAlchemy 又显得太重。一个轻量级的链式查询构建器往往是个不错的中间选择。
pythonclass QueryBuilder:
"""轻量级链式查询构建器"""
def __init__(self, table: str):
self._table = table
self._conditions = []
self._order_by = None
self._limit_val = None
self._offset_val = None
self._columns = ["*"]
def select(self, *columns):
"""指定查询列"""
self._columns = list(columns)
return self
def where(self, condition: str):
"""添加过滤条件(支持多次调用,自动 AND 连接)"""
self._conditions.append(condition)
return self
def order_by(self, column: str, desc: bool = False):
"""排序"""
direction = "DESC" if desc else "ASC"
self._order_by = f"{column} {direction}"
return self
def limit(self, n: int):
self._limit_val = n
return self
def offset(self, n: int):
self._offset_val = n
return self
def build(self) -> str:
"""构建最终 SQL 字符串"""
cols = ", ".join(self._columns)
sql = f"SELECT {cols} FROM {self._table}"
if self._conditions:
where_clause = " AND ".join(f"({c})" for c in self._conditions)
sql += f" WHERE {where_clause}"
if self._order_by:
sql += f" ORDER BY {self._order_by}"
if self._limit_val is not None:
sql += f" LIMIT {self._limit_val}"
if self._offset_val is not None:
sql += f" OFFSET {self._offset_val}"
return sql
# 链式构建复杂查询
query = (
QueryBuilder("orders")
.select("order_id", "user_id", "amount", "created_at")
.where("status = 'paid'")
.where("amount > 100")
.order_by("created_at", desc=True)
.limit(20)
.offset(40)
.build()
)
print(query)

这种写法的好处非常直观:查询意图一目了然,每个条件独立可维护,新增条件只需插入一行 .where(),不用去动其他代码。实际项目中可以在 build() 之前加入参数化处理来防止 SQL 注入,这里为了演示简洁省略了。
⚠️ 踩坑预警:这些地方容易出问题
坑一:忘记返回 self 导致 AttributeError。 这是最常见的错误,尤其是在给已有类添加链式支持时。某个方法漏写了 return self,链条就断了,报错信息是 'NoneType' object has no attribute 'xxx',有时候还不好定位。建议养成习惯:凡是设计为链式调用的方法,第一步就写好 return self,再填充方法体。
坑二:链条过长导致调试困难。 链式调用的一个副作用是,当某个中间步骤出问题时,整条链只报一行错误,不知道是哪个节点出的问题。应对方法是在开发阶段适当拆分,或者在关键方法里加入日志输出,生产环境再合并成链。
坑三:方案一中的共享状态问题。 已在方案二中详细说明,核心原则是:如果你的链式对象可能被多处持有或"分叉"使用,优先选择不可变方案。
坑四:滥用链式导致可读性下降。 链式编程不是银弹,链条太长同样影响可读性。一般建议单条链不超过 5-7 个调用,超过这个长度可以考虑拆分为两段,或者提取中间变量加注释。
📊 横向对比:三种写法的综合评估
| 维度 | 逐步赋值 | 嵌套调用 | 链式调用 |
|---|---|---|---|
| 可读性 | 中 | 低 | 高 |
| 调试便利性 | 高 | 低 | 中 |
| 命名空间污染 | 高 | 低 | 低 |
| 扩展性 | 中 | 低 | 高 |
| 学习曲线 | 低 | 低 | 中 |
没有绝对最优的写法,根据场景选择才是正确姿势。简单的两步处理没必要封装链式接口;但如果是多步骤的数据处理流水线、配置构建、查询拼装,链式编程的优势就非常明显了。
🎯 总结与学习路径
链式编程的核心就是 return self,但围绕这个核心可以延伸出很多有趣的设计:不可变链式对象引入了函数式编程的思想;查询构建器体现了 Builder 模式的精髓;而 pandas 的链式 API 则是这些思想在大规模数据处理场景下的最佳实践之一。
掌握了链式编程,下一步可以继续深入以下方向:上下文管理器(__enter__/__exit__)让资源管理也能优雅链式化;描述符协议可以让链式属性访问更灵活;操作符重载(__or__、__rshift__)可以让管道符风格的代码成为可能,就像 shell 里的 | 一样直观。
三句话带走今天的核心:链式编程的本质是让数据流动,而非让变量堆积;不可变链式对象是函数式思维在 OOP 中的映射;好的链式接口设计,应该让调用代码读起来像一句自然语言。
💬 你在项目中有没有遇到过"中间变量地狱"的情况?你是怎么解决的? 欢迎在评论区聊聊你的思路,或者分享你见过的最优雅(或最混乱)的链式调用案例。
#Python #编程技巧 #设计模式 #性能优化 #Python开发
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!