
Press Ctrl+ and K to search
目录
🔥 本文将带您深入了解C#中的雪花漂移算法,从原理到实现,从基础到高级应用,全方位解析这一高效的唯一ID生成方案。无论您是初学者还是有经验的开发者,都能从中获得实用价值。
什么是雪花漂移算法?
雪花漂移算法(Snowflake Drift)是Twitter雪花算法(Snowflake)的优化版本,专为解决分布式系统中唯一ID生成的复杂需求而设计。在微服务架构、分布式数据库和高并发系统中,它已成为首选的ID生成方案之一。
相比传统雪花算法的优势
- 📏 生成ID更短:占用空间更小,利于存储和传输
- 🚀 性能更高:比传统算法快2-5倍
- 🔄 支持容器环境自动扩容:适应云原生架构
- 💻 跨语言兼容:不仅限于C#,还支持Java、Go等多种语言
- 🔌 灵活部署:可在单机和分布式环境中无缝使用
算法核心解析
ID结构设计
雪花漂移算法的精妙之处在于其ID组成结构。每个生成的ID由三个关键部分构成:
Markdown|------ 时间戳部分 ------|-- 工作机器ID --|-- 序列号 --|
- 时间差值:相对于设定基础时间的毫秒差值
- WorkerId:机器或应用的唯一标识符
- 序列号:同一毫秒内的自增序列,确保同一时间点的唯一性
关键配置参数
- WorkerIdBitLength:默认6位,决定了WorkerId的最大值
- 6位可支持最多64个工作节点(2^6=64)
- 可根据系统规模调整
- SeqBitLength:默认6位,决定每毫秒可生成的ID数量
- 6位可每毫秒生成64个ID(2^6=64)
- 高并发场景可适当增加
- BaseTime:基准时间,默认为2020年1月1日
- 可自定义设置,影响ID的使用寿命
C#实现详解
基础实现示例
首先,我们需要安装Yitter.IdGenerator包:
C#using Yitter.IdGenerator;
namespace AppYitter
{
internal class Program
{
static void Main(string[] args)
{
// 配置ID生成器选项
var options = new IdGeneratorOptions(1) // 1是WorkerId
{
WorkerIdBitLength = 6, // WorkerId位长度
SeqBitLength = 10, // 序列号位长度
BaseTime = new DateTime(2020, 1, 1) // 设置一个较早的基准时间
};
// 初始化ID生成器
YitIdHelper.SetIdGenerator(options);
// 生成唯一ID
long id1 = YitIdHelper.NextId();
long id2 = YitIdHelper.NextId();
Console.WriteLine($"ID1: {id1}");
Console.WriteLine($"ID2: {id2}");
Console.ReadKey();
}
}
}
进阶:单例模式实现
在实际项目中,推荐使用单例模式来管理ID生成器:
C#using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Yitter.IdGenerator;
namespace AppYitter
{
public class IdGeneratorSingleton
{
private static readonly Lazy<IdGeneratorSingleton> _instance =
new Lazy<IdGeneratorSingleton>(() => new IdGeneratorSingleton());
private readonly IIdGenerator _generator;
public static IdGeneratorSingleton Instance => _instance.Value;
private IdGeneratorSingleton()
{
// 配置并初始化生成器
var options = new IdGeneratorOptions(GetWorkerId())
{
WorkerIdBitLength = 6,
SeqBitLength = 10
};
_generator = new DefaultIdGenerator(options);
}
public long NextId() => _generator.NewLong();
// 获取WorkerId的方法,可以从配置、环境变量或其他中心化服务获取
private ushort GetWorkerId()
{
// 示例:从环境变量获取
string workerIdStr = Environment.GetEnvironmentVariable("WORKER_ID");
if (ushort.TryParse(workerIdStr, out ushort workerId))
{
return workerId;
}
// 默认值或其他获取逻辑
return 1;
}
}
}
性能与容量分析
性能指标
雪花漂移算法的性能表现相当惊人:
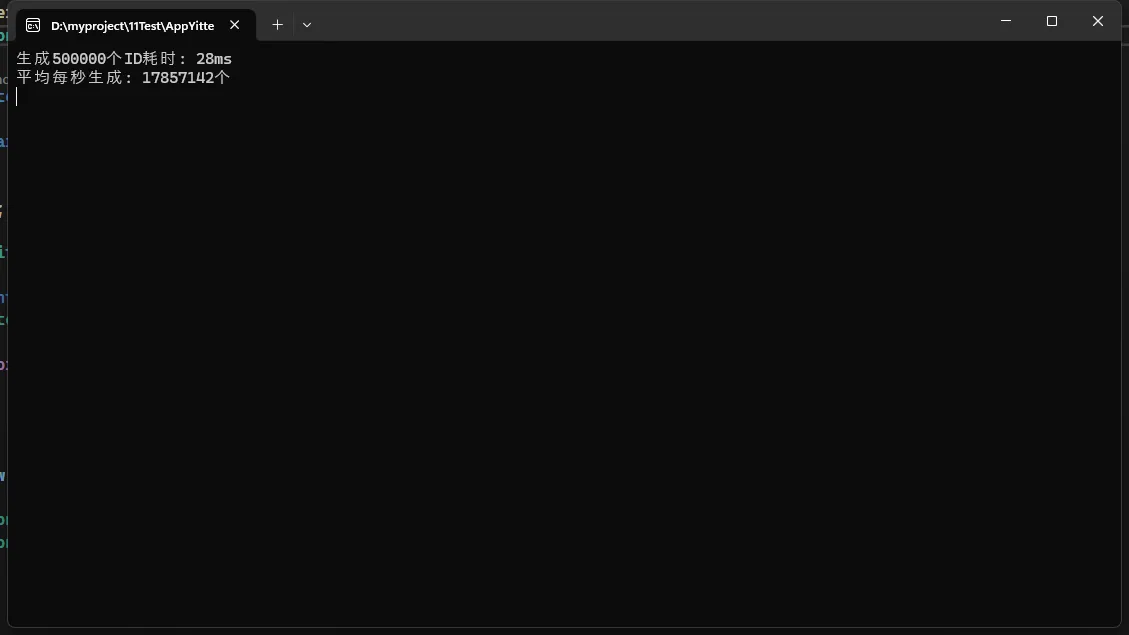
- ⚡ 0.1秒可生成50万个ID
- 🔥 支持5W-500W/秒的ID生成速度
- 📊 运行70年不会超过JavaScript Number最大值
实际测试代码:
C#using System.Diagnostics;
using Yitter.IdGenerator;
namespace AppYitter
{
internal class Program
{
static void Main(string[] args)
{
PerformanceTest();
Console.ReadKey();
}
private static void PerformanceTest()
{
var options = new IdGeneratorOptions(1)
{
SeqBitLength = 10 // 提高序列号位长度以支持高并发
};
YitIdHelper.SetIdGenerator(options);
int count = 500000; // 50万个ID
Stopwatch sw = Stopwatch.StartNew();
for (int i = 0; i < count; i++)
{
YitIdHelper.NextId();
}
sw.Stop();
Console.WriteLine($"生成{count}个ID耗时: {sw.ElapsedMilliseconds}ms");
Console.WriteLine($"平均每秒生成: {count * 1000 / sw.ElapsedMilliseconds}个");
}
}
}
使用寿命估算
在不同配置下,算法的使用寿命非常可观:
- 📆 默认配置:可用71,000年不重复
- 📆 1024个工作节点:可用4,480年
- 📆 4096个工作节点:可用1,120年
这意味着,即使是最苛刻的应用场景,也不必担心ID耗尽问题。
总结
雪花漂移算法是一种高效、可靠的分布式ID生成方案,特别适合C#开发的大规模系统。它的主要优势包括:
✅ 高性能:每秒可生成数百万个ID
✅ 全局唯一:确保跨节点、跨时间的ID唯一性
✅ 趋势递增:生成的ID大致按时间递增,有利于索引性能
✅ 可配置性:灵活调整以满足不同场景需求
✅ 无外部依赖:不依赖数据库等外部系统
随着微服务和分布式系统的普及,雪花漂移算法的应用前景将更加广阔。未来可能会出现更多针对特定场景的优化版本,例如适用于边缘计算、IoT设备等场景的轻量级实现。
📌 关键词:C#、雪花漂移算法、分布式ID、高性能、唯一ID生成器、分布式系统、微服务、Snowflake Drift、WorkerId、序列号
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录