
Press Ctrl+ and K to search
目录
在当今数字化时代,语音识别技术已经成为人机交互的重要组成部分。OpenAI推出的Whisper模型以其卓越的多语言语音识别能力,正在revolutionizing语音转文字领域。本文将详细介绍如何在C#项目中集成Whisper,实现高精度的语音转文字功能。
什么是Whisper?
Whisper是OpenAI开发的一个开源语音识别模型,具有以下特点:
- 支持多达99种语言的语音识别
- 提供强大的翻译功能
- 对背景噪音有很强的抵抗力
- 识别准确率高
- 支持长时间音频处理
在本地使用Whisper.net库
对于需要离线处理或者对隐私有更高要求的场景,可以使用Whisper.net库在本地运行Whisper模型。
准备工作
安装Whisper.net NuGet包:
Bashdotnet add package Whisper.net dotnet add package Whisper.net.Runtime dotnet add NAudio

模型手动下载
Markdownhttps://huggingface.co/sandrohanea/whisper.net/tree/main/classic
完整代码示例
C#using Whisper.net.Ggml;
using Whisper.net;
using NAudio.Wave;
namespace AppWhisper
{
internal class Program
{
static async Task Main(string[] args)
{
// 模型路径
string modelPath = "D:\\Models\\ggml-medium.bin";
// 检查模型文件是否存在,不存在则下载
if (!File.Exists(modelPath))
{
Console.WriteLine("下载Whisper模型中...");
// 下载medium模型,适合大多数场景
using var modelStream = await WhisperGgmlDownloader.GetGgmlModelAsync(GgmlType.Medium);
using var fileWriter = File.OpenWrite(modelPath);
await modelStream.CopyToAsync(fileWriter);
}
try
{
// 指定要转录的音频文件
string audioFilePath = "Recording.mp3";
if (Path.GetExtension(audioFilePath).ToLower() == ".mp3")
{
// 如果是MP3文件,则先转换为WAV格式
audioFilePath = ConvertMp3ToWav(audioFilePath);
}
Console.WriteLine("加载Whisper模型...");
// 初始化Whisper处理器
using var whisperFactory = WhisperFactory.FromPath(modelPath);
// 创建Whisper处理器实例,可以配置处理参数
using var processor = whisperFactory.CreateBuilder()
.WithLanguage("zh") // 设置语言为中文
//.WithTranslate
.WithSingleSegment()
.WithPrintSpecialTokens()
.WithPrintProgress()
.WithPrintResults()
.Build();
Console.WriteLine("开始处理音频文件...");
// 打开音频文件
using var audioFileStream = File.OpenRead(audioFilePath);
// 执行处理并获取分段结果
var results = processor.ProcessAsync(audioFileStream);
// 创建用于保存结果的文件
using var writer = new StreamWriter("transcription_local.txt");
// 处理并保存每个分段的结果
await foreach (var segment in results)
{
string text = segment.Text;
Console.WriteLine($"[{segment.Start}->{segment.End}]: {text}");
await writer.WriteLineAsync($"[{segment.Start:hh\\:mm\\:ss\\.fff} -> {segment.End:hh\\:mm\\:ss\\.fff}]: {text}");
}
Console.WriteLine("处理完成!结果已保存到 transcription_local.txt");
Console.ReadKey();
}
catch (Exception ex)
{
Console.WriteLine($"发生错误:{ex.Message}");
}
}
// 将MP3转换为WAV格式
public static string ConvertMp3ToWav(string mp3FilePath)
{
string wavFilePath = Path.ChangeExtension(mp3FilePath, ".wav");
using (var reader = new Mp3FileReader(mp3FilePath))
{
WaveFormat format = new WaveFormat(16000, 16, 1); // 16kHz, 16bit, 单声道
using (var converter = new MediaFoundationResampler(reader, format))
{
WaveFileWriter.CreateWaveFile(wavFilePath, converter);
}
}
return wavFilePath;
}
}
}
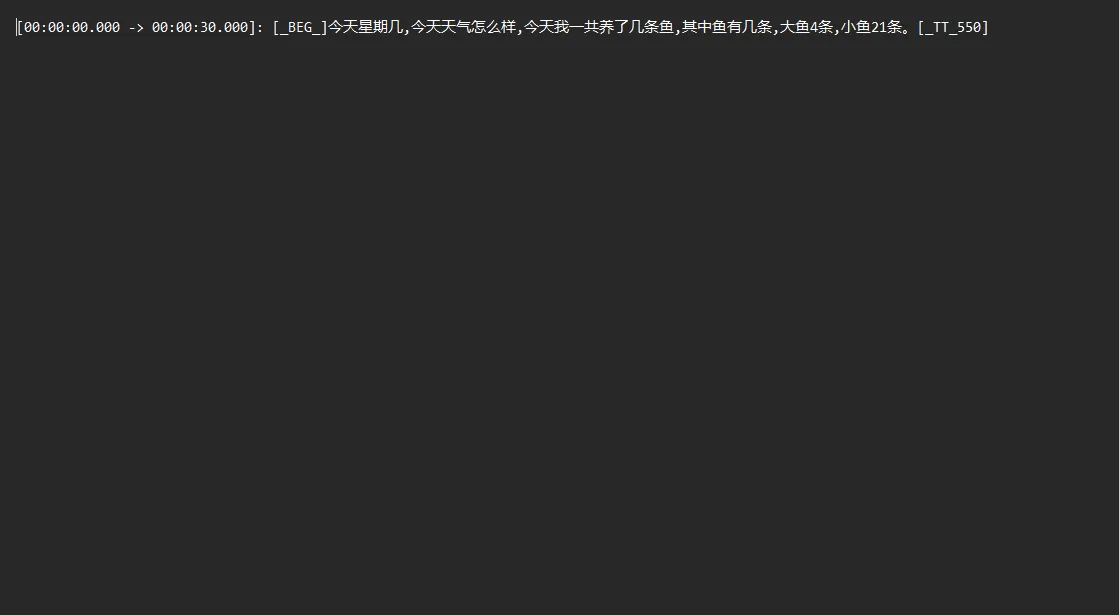
代码解析
- 模型下载:检查并下载Whisper模型文件
- 初始化处理器:创建Whisper处理器并进行参数配置
- 音频处理:读取音频文件并进行处理
- 分段处理结果:逐段处理并保存识别结果,包含时间戳信息
高级应用:实时语音识别
以下是一个使用NAudio库捕获麦克风输入并实时转写的示例:
C#using NAudio.Wave;
using Whisper.net;
using Whisper.net.Ggml;
using System;
using System.Collections.Concurrent;
using System.IO;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
namespace AppWhisperRealtime
{
internal class Program
{
static async Task Main(string[] args)
{
// 模型路径
string modelPath = "D:\\Models\\ggml-medium.bin";
// 检查并下载模型
if (!File.Exists(modelPath))
{
Console.WriteLine("下载Whisper模型中...");
using var modelStream = await WhisperGgmlDownloader.GetGgmlModelAsync(GgmlType.Medium);
using var fileWriter = File.OpenWrite(modelPath);
await modelStream.CopyToAsync(fileWriter);
}
// 初始化Whisper工厂
using var whisperFactory = WhisperFactory.FromPath(modelPath);
// 录音设置
const int sampleRate = 16000;
const int channelCount = 1;
const int bitsPerSample = 16;
const int bufferSeconds = 3;
// 音频块队列
var audioChunks = new ConcurrentQueue<byte[]>();
// 取消标记
var cts = new CancellationTokenSource();
// 同步锁对象
var processingLock = new SemaphoreSlim(1, 1);
// 初始化麦克风
var waveIn = new WaveInEvent
{
DeviceNumber = 0,
WaveFormat = new WaveFormat(sampleRate, bitsPerSample, channelCount),
BufferMilliseconds = 50
};
// 使用NAudio的WaveBuffer来累积音频样本
var audioBuffer = new List<byte>();
var waveFormat = new WaveFormat(sampleRate, bitsPerSample, channelCount);
// 处理录音数据
waveIn.DataAvailable += (sender, e) =>
{
lock (audioBuffer) // 锁定写入操作
{
// 将新的音频数据添加到累积缓冲区
audioBuffer.AddRange(e.Buffer.Take(e.BytesRecorded));
// 检查是否达到了目标缓冲长度
int targetByteCount = sampleRate * channelCount * (bitsPerSample / 8) * bufferSeconds;
if (audioBuffer.Count >= targetByteCount)
{
try
{
// 获取目标长度的音频数据
byte[] pcmData = audioBuffer.Take(targetByteCount).ToArray();
// 转换为WAV格式(添加WAV头)
byte[] wavData = CreateWaveFile(pcmData, waveFormat);
// 将音频块加入队列
audioChunks.Enqueue(wavData);
// 保留超出部分的数据以确保连续性
audioBuffer = audioBuffer.Skip(targetByteCount).ToList();
Console.WriteLine("已捕获5秒音频,加入处理队列");
}
catch (Exception ex)
{
Console.WriteLine($"处理录音数据时出错: {ex.Message}");
}
}
}
};
// 将PCM数据转换为WAV文件(添加WAV头)
byte[] CreateWaveFile(byte[] pcmData, WaveFormat format)
{
using (var ms = new MemoryStream())
{
using (var writer = new WaveFileWriter(ms, format))
{
writer.Write(pcmData, 0, pcmData.Length);
}
return ms.ToArray();
}
}
// 启动音频处理线程
Task.Run(async () =>
{
while (!cts.Token.IsCancellationRequested)
{
// 尝试从队列中获取音频块
if (audioChunks.TryDequeue(out byte[] wavData))
{
await processingLock.WaitAsync(); // 使用信号量确保一次只处理一个音频
try
{
// 为每个处理任务创建新的处理器实例,确保线程安全
using var processor = whisperFactory.CreateBuilder()
.WithLanguage("zh")
.Build();
Console.WriteLine("处理语音中...");
using (var wavStream = new MemoryStream(wavData))
{
try
{
// 识别语音
var results = processor.ProcessAsync(wavStream);
StringBuilder resultText = new StringBuilder();
await foreach (var segment in results)
{
resultText.Append(segment.Text);
}
// 只有当有实际内容时才输出
if (resultText.Length > 0)
{
Console.WriteLine($"识别结果: {resultText}");
}
else
{
Console.WriteLine("未识别到语音内容");
}
}
catch (Exception ex)
{
Console.WriteLine($"语音处理错误: {ex.Message}");
Console.WriteLine($"异常类型: {ex.GetType().Name}");
Console.WriteLine($"堆栈跟踪: {ex.StackTrace}");
}
}
}
catch (Exception ex)
{
Console.WriteLine($"创建处理器时出错: {ex.Message}");
}
finally
{
processingLock.Release(); // 释放信号量
}
}
else
{
// 如果队列为空,短暂等待
await Task.Delay(100, cts.Token);
}
}
}, cts.Token);
Console.WriteLine("开始录音,请说话...(按Enter键停止)");
waveIn.StartRecording();
// 等待用户按下Enter键停止
Console.ReadLine();
// 停止处理
cts.Cancel();
try
{
// 安全停止录音
waveIn.StopRecording();
}
catch (Exception ex)
{
Console.WriteLine($"停止录音时出错: {ex.Message}");
}
// 清理资源
waveIn.Dispose();
processingLock.Dispose();
}
}
}
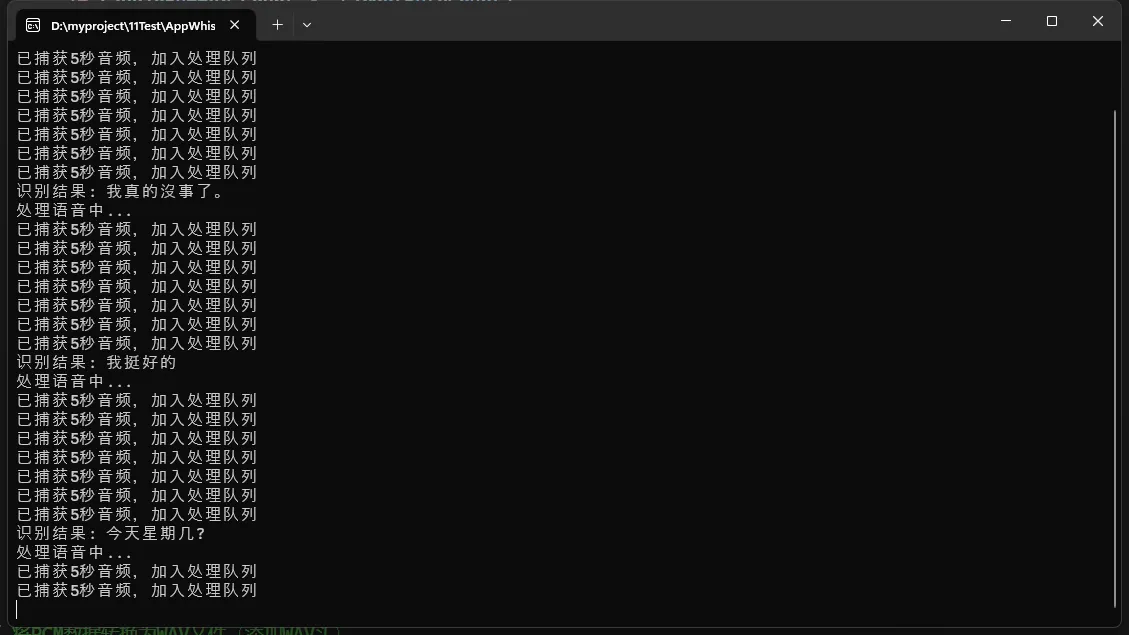
注意:有点慢,有点慢!!!
性能优化建议
- 选择合适的模型大小:根据需求选择tiny/base/small/medium/large模型
- 使用GPU加速:Whisper.net支持CUDA加速,可大幅提升处理速度
- 调整音频参数:使用16kHz采样率、单声道、16位PCM格式的音频可获得最佳效果
- 批量处理:对于大量音频文件,使用并行处理提高效率
常见问题解答
Q: 为什么中文识别效果不理想?
A: 可以通过指定语言参数language: "zh"来提高中文识别准确率。
Q: 如何处理长音频文件?
A: 可以将长音频分片处理,或使用流式处理方式逐段识别。
结语
Whisper语音转文字技术为C#开发者提供了强大的语音识别能力。无论是通过OpenAI API调用还是在本地运行模型,都能实现高质量的语音转文字功能。希望本文详细的代码示例和说明能帮助你在项目中成功实现语音识别功能。
如有任何问题或建议,欢迎在评论区留言讨论!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录