
Press Ctrl+ and K to search
目录
背景介绍
在现代软件开发中,高效处理大数据量是一个常见且具有挑战性的任务。SQLite作为一个轻量级、无服务器的关系型数据库,在C#中提供了强大的数据处理能力。本文将深入探讨如何使用SQLite优化大数据量的存储和检索。
准备工作
首先,我们需要引入必要的NuGet包:
C#// 使用System.Data.SQLite进行SQLite数据库操作
using System.Data.SQLite;

大数据量处理的关键技术
数据实体类
C#// 数据实体类
public class DataItem
{
public long Id { get; set; }
public string Name { get; set; }
public decimal Value { get; set; }
public DateTime Timestamp { get; set; }
}
批量插入优化
C#using System;
using System.Collections.Generic;
using System.Data.SQLite;
using System.Diagnostics;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace AppBigData
{
public class DataProcessor
{
private readonly string _connectionString;
public DataProcessor(string connectionString = "Data Source=large_database.db")
{
_connectionString = connectionString;
}
// 创建表结构
public void CreateTableIfNotExists()
{
using (var connection = new SQLiteConnection(_connectionString))
{
connection.Open();
using (var command = new SQLiteCommand(connection))
{
command.CommandText = @"
CREATE TABLE IF NOT EXISTS DataTable (
Id INTEGER PRIMARY KEY,
Name TEXT NOT NULL,
Value REAL NOT NULL,
Timestamp TEXT NOT NULL
)";
command.ExecuteNonQuery();
}
}
}
// 批量插入数据的高效方法
public void BulkInsert(List<DataItem> items)
{
if (items == null || !items.Any())
return;
try
{
// 使用事务大幅提升插入性能
using (var connection = new SQLiteConnection(_connectionString))
{
connection.Open();
using (var transaction = connection.BeginTransaction())
{
try
{
using (var command = new SQLiteCommand(connection))
{
// 预编译SQL语句
command.CommandText = @"
INSERT INTO DataTable
(Id, Name, Value, Timestamp)
VALUES
(@Id, @Name, @Value, @Timestamp)";
// 准备参数
command.Parameters.Add("@Id", System.Data.DbType.Int64);
command.Parameters.Add("@Name", System.Data.DbType.String);
command.Parameters.Add("@Value", System.Data.DbType.Decimal);
command.Parameters.Add("@Timestamp", System.Data.DbType.DateTime);
// 批量插入
foreach (var item in items)
{
command.Parameters["@Id"].Value = item.Id;
command.Parameters["@Name"].Value = item.Name;
command.Parameters["@Value"].Value = item.Value;
command.Parameters["@Timestamp"].Value = item.Timestamp;
command.ExecuteNonQuery();
}
}
// 提交事务
transaction.Commit();
}
catch (Exception)
{
// 出错时回滚事务
transaction.Rollback();
throw;
}
}
}
}
catch (Exception ex)
{
Console.WriteLine($"批量插入数据时发生错误: {ex.Message}");
throw;
}
}
/// <summary>
/// 改进的批量插入方法 - 使用SQLite的批处理特性和事务
/// 这里batchSize很重要,太大了不行,太小了也不行
/// </summary>
/// <param name="items"></param>
/// <param name="batchSize"></param>
public void ImprovedBulkInsert(List<DataItem> items, int batchSize = 100)
{
if (items == null || !items.Any())
return;
try
{
using (var connection = new SQLiteConnection(_connectionString))
{
connection.Open();
// 保留性能优化的pragmas
using (var pragmaCommand = new SQLiteCommand(connection))
{
pragmaCommand.CommandText = "PRAGMA synchronous = OFF; PRAGMA journal_mode = MEMORY;";
pragmaCommand.ExecuteNonQuery();
}
// 不使用using语句来管理事务,这样我们可以重新创建它
SQLiteTransaction transaction = connection.BeginTransaction();
try
{
using (var command = new SQLiteCommand(connection))
{
command.CommandText = @"INSERT INTO DataTable (Id, Name, Value, Timestamp)
VALUES (@Id, @Name, @Value, @Timestamp)";
// 一次性准备参数
command.Parameters.Add("@Id", System.Data.DbType.Int64);
command.Parameters.Add("@Name", System.Data.DbType.String);
command.Parameters.Add("@Value", System.Data.DbType.Decimal);
command.Parameters.Add("@Timestamp", System.Data.DbType.DateTime);
// 以较小的批次处理
int count = 0;
foreach (var item in items)
{
command.Parameters["@Id"].Value = item.Id;
command.Parameters["@Name"].Value = item.Name;
command.Parameters["@Value"].Value = item.Value;
command.Parameters["@Timestamp"].Value = item.Timestamp;
command.ExecuteNonQuery();
count++;
// 分批提交,平衡内存使用和事务开销
if (count % batchSize == 0)
{
transaction.Commit();
// 创建新的事务
transaction = connection.BeginTransaction();
}
}
// 提交剩余的记录
transaction.Commit();
}
}
catch
{
transaction.Rollback();
throw;
}
}
}
catch (Exception ex)
{
Console.WriteLine($"改进型批量插入数据时发生错误: {ex.Message}");
throw;
}
}
// 基准测试方法
public void PerformanceBenchmark(int itemCount = 10000)
{
// 清空表
ClearTable();
// 生成测试数据
var testData = GenerateTestData(itemCount);
// 测试标准批量插入
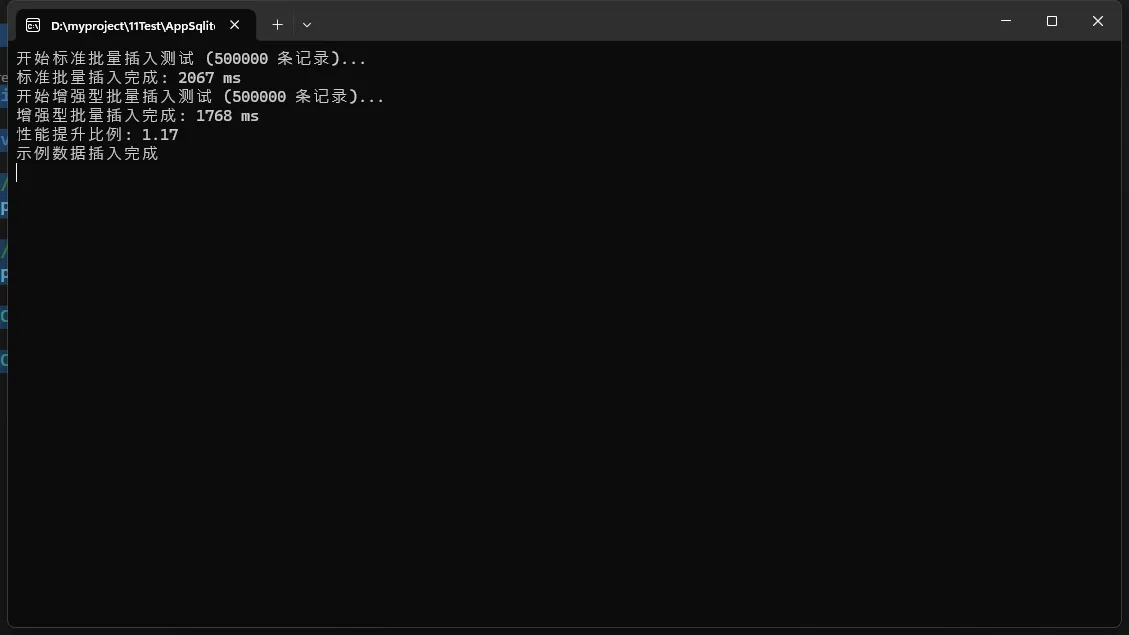
Console.WriteLine($"开始标准批量插入测试 ({itemCount} 条记录)...");
var standardTimer = Stopwatch.StartNew();
BulkInsert(testData);
standardTimer.Stop();
Console.WriteLine($"标准批量插入完成: {standardTimer.ElapsedMilliseconds} ms");
// 清空表
ClearTable();
// 测试增强型批量插入
Console.WriteLine($"开始增强型批量插入测试 ({itemCount} 条记录)...");
var enhancedTimer = Stopwatch.StartNew();
ImprovedBulkInsert(testData);
enhancedTimer.Stop();
Console.WriteLine($"增强型批量插入完成: {enhancedTimer.ElapsedMilliseconds} ms");
// 比较结果
double improvement = (double)standardTimer.ElapsedMilliseconds / enhancedTimer.ElapsedMilliseconds;
Console.WriteLine($"性能提升比例: {improvement:F2}");
}
// 生成测试数据
private List<DataItem> GenerateTestData(int count)
{
var random = new Random();
var result = new List<DataItem>(count);
for (int i = 0; i < count; i++)
{
result.Add(new DataItem
{
Id = i + 1,
Name = $"Item-{i}",
Value = (decimal)(random.NextDouble() * 1000),
Timestamp = DateTime.Now.AddSeconds(-random.Next(0, 86400))
});
}
return result;
}
// 清空表
private void ClearTable()
{
using (var connection = new SQLiteConnection(_connectionString))
{
connection.Open();
using (var command = new SQLiteCommand("DELETE FROM DataTable", connection))
{
command.ExecuteNonQuery();
}
}
}
}
}
调用
C#namespace AppBigData
{
internal class Program
{
static void Main(string[] args)
{
var processor = new DataProcessor();
// 确保表存在
processor.CreateTableIfNotExists();
// 执行性能测试
processor.PerformanceBenchmark(500000);
Console.WriteLine("示例数据插入完成");
Console.ReadKey();
}
}
}
分页查询与索引优化
C#public class DataRetriever
{
// 分页查询大数据集
public List<DataItem> GetPaginatedData(int pageNumber, int pageSize)
{
var results = new List<DataItem>();
using (var connection = new SQLiteConnection("Data Source=large_database.db"))
{
connection.Open();
// 使用参数化查询提高安全性和性能
using (var command = new SQLiteCommand(connection))
{
command.CommandText = @"
SELECT Id, Name, Value, Timestamp
FROM DataTable
ORDER BY Id
LIMIT @PageSize OFFSET @Offset";
command.Parameters.AddWithValue("@PageSize", pageSize);
command.Parameters.AddWithValue("@Offset", (pageNumber - 1) * pageSize);
using (var reader = command.ExecuteReader())
{
while (reader.Read())
{
results.Add(new DataItem
{
Id = Convert.ToInt64(reader["Id"]),
Name = reader["Name"].ToString(),
Value = Convert.ToDecimal(reader["Value"]),
Timestamp = Convert.ToDateTime(reader["Timestamp"])
});
}
}
}
}
return results;
}
// 创建性能索引
public void CreatePerformanceIndex()
{
using (var connection = new SQLiteConnection("Data Source=large_database.db"))
{
connection.Open();
using (var command = new SQLiteCommand(connection))
{
// 创建复合索引
command.CommandText = @"
CREATE INDEX IF NOT EXISTS idx_data_performance
ON DataTable (Timestamp, Value)";
command.ExecuteNonQuery();
}
}
}
}
异步数据处理
C#using System;
using System.Collections.Concurrent;
using System.Collections.Generic;
using System.Data.SQLite;
using System.Threading;
using System.Threading.Tasks;
namespace AppBigData
{
public class AsyncDataProcessor
{
private readonly string _connectionString;
public AsyncDataProcessor(string connectionString = "Data Source=large_database.db")
{
_connectionString = connectionString;
}
// 异步批量处理数据 - 修改为线程安全方式
public async Task ProcessLargeDataSetAsync(List<DataItem> items)
{
if (items == null || items.Count == 0)
return;
// 分区处理数据以提高性能
var partitionSize = Math.Max(1, items.Count / Environment.ProcessorCount);
var partitions = new List<List<DataItem>>();
for (int i = 0; i < items.Count; i += partitionSize)
{
var partition = items.GetRange(
i,
Math.Min(partitionSize, items.Count - i));
partitions.Add(partition);
}
// 记录处理错误
var exceptions = new ConcurrentBag<Exception>();
await Task.Run(() =>
{
// 每个分区用单独的连接处理
Parallel.ForEach(partitions, new ParallelOptions { MaxDegreeOfParallelism = 4 }, partition =>
{
try
{
// 每个线程创建自己的连接
using (var connection = new SQLiteConnection(_connectionString))
{
connection.Open();
// 使用事务提高性能
using (var transaction = connection.BeginTransaction())
{
try
{
foreach (var item in partition)
{
ProcessSingleItem(connection, item);
}
// 提交此分区的所有更改
transaction.Commit();
}
catch (Exception ex)
{
// 如果处理过程中出错,回滚事务
transaction.Rollback();
exceptions.Add(ex);
}
}
}
}
catch (Exception ex)
{
exceptions.Add(ex);
}
});
});
// 如果有错误,抛出聚合异常
if (exceptions.Count > 0)
{
throw new AggregateException("处理数据时发生一个或多个错误", exceptions);
}
}
private void ProcessSingleItem(SQLiteConnection connection, DataItem item)
{
// 处理单个数据项的逻辑
using (var command = new SQLiteCommand(connection))
{
// 首先检查记录是否存在
command.CommandText = "SELECT COUNT(*) FROM DataTable WHERE Id = @Id";
command.Parameters.AddWithValue("@Id", item.Id);
int exists = Convert.ToInt32(command.ExecuteScalar());
if (exists > 0)
{
// 更新现有记录
command.CommandText = @"
UPDATE DataTable
SET Name = @Name, Value = @Value, Timestamp = @Timestamp
WHERE Id = @Id";
}
else
{
// 插入新记录
command.CommandText = @"
INSERT INTO DataTable (Id, Name, Value, Timestamp)
VALUES (@Id, @Name, @Value, @Timestamp)";
}
// 设置参数
command.Parameters.Clear();
command.Parameters.AddWithValue("@Id", item.Id);
command.Parameters.AddWithValue("@Name", item.Name);
command.Parameters.AddWithValue("@Value", item.Value);
command.Parameters.AddWithValue("@Timestamp", item.Timestamp);
// 执行命令
command.ExecuteNonQuery();
}
}
}
}
调用
C#using System.Data.SQLite;
namespace AppBigData
{
internal class Program
{
static async Task Main(string[] args)
{
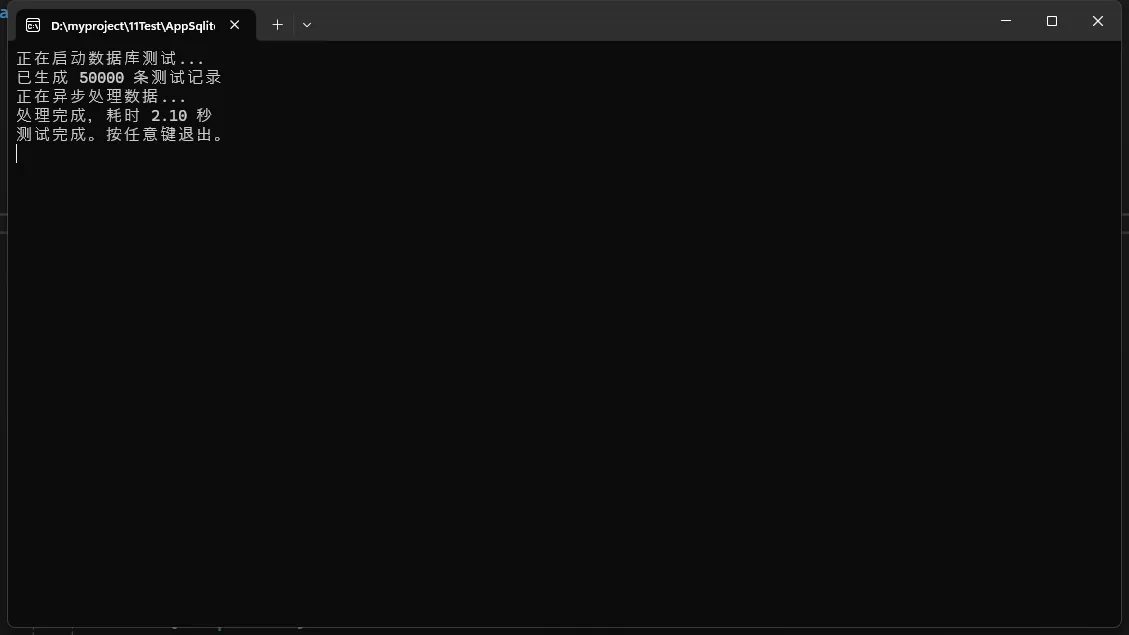
Console.WriteLine("正在启动数据库测试...");
var processor = new AsyncDataProcessor("Data Source=large_database.db");
var testData = GenerateTestData(50000);
Console.WriteLine($"已生成 {testData.Count} 条测试记录");
try
{
Console.WriteLine("正在异步处理数据...");
var startTime = DateTime.Now;
await processor.ProcessLargeDataSetAsync(testData);
var endTime = DateTime.Now;
Console.WriteLine($"处理完成,耗时 {(endTime - startTime).TotalSeconds:F2} 秒");
}
catch (AggregateException ex)
{
Console.WriteLine("处理过程中发生错误:");
foreach (var innerEx in ex.InnerExceptions)
{
Console.WriteLine($"- {innerEx.Message}");
}
}
catch (Exception ex)
{
Console.WriteLine($"错误: {ex.Message}");
}
Console.WriteLine("测试完成。按任意键退出。");
Console.ReadKey();
}
private static List<DataItem> GenerateTestData(int count)
{
var random = new Random();
var items = new List<DataItem>();
for (int i = 1; i <= count; i++)
{
items.Add(new DataItem
{
Id = i,
Name = $"测试项目 {i}",
Value = (decimal)Math.Round(random.NextDouble() * 1000, 2),
Timestamp = DateTime.Now.AddMinutes(-random.Next(0, 1000))
});
}
return items;
}
}
}
性能优化建议
- 使用事务批量处理数据
- 为常用查询创建适当的索引
- 使用参数化查询
- 分页获取大数据集
- 考虑使用异步和并行处理
注意事项
- SQLite对并发写入支持有限
- 大数据量时考虑分库分表
- 定期进行数据库维护和vacuum操作
结论
通过合理运用SQLite的特性和C#的高级特性,我们可以高效地处理大数据量,保证系统的性能和稳定性。
这篇文章全面展示了在C#中使用SQLite处理大数据量的关键技术和最佳实践。文章涵盖了批量插入、分页查询、索引优化和异步处理等重要技术点。
希望这篇文章对您有帮助!如果您需要更详细的解释或有任何问题,请随时告诉我。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录