目录
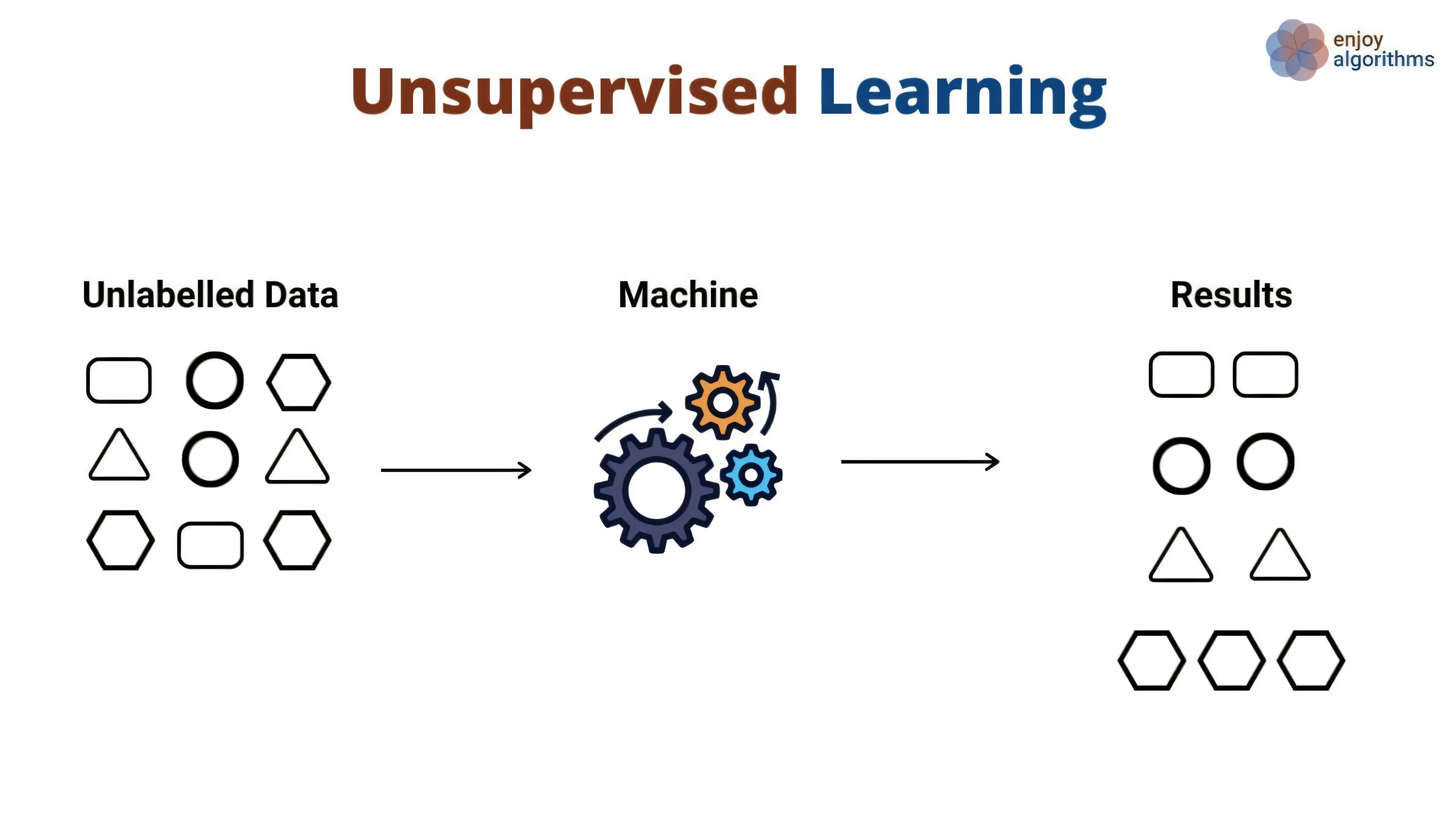
非监督学习(Unsupervised Learning)是机器学习中的一种重要范式,它的目标是从未标记(无监督)的数据集中发现数据的内在结构和规律。与监督学习不同,非监督学习不需要预先标记的训练数据,通过挖掘数据本身的分布和特征来进行模式识别、聚类、降维等任务。
主要应用场景
-
聚类分析(Clustering)
非监督学习常被用于聚类分析任务,根据数据相似性将样本自动划分到不同的聚合簇中。例如,对市场上的消费者进行细分,从而在精准营销中针对不同人群采取不同策略。
-
异常检测(Anomaly Detection)
非监督学习可用于检测出与大部分样本差异显著的“异常点”。例如,金融交易中的欺诈交易检测,网络中的入侵检测,传感器数据中的故障检测等。
-
降维和可视化(Dimensionality Reduction and Visualization)
当数据的特征特别高维且较难可视化时,非监督学习算法(如PCA)可以将高维数据投影到更低维的空间,以便进行可视化或后续分析。
-
特征学习(Feature Learning)
通过非监督学习的方法对数据进行学习,从而得到有意义的特征表示。典型的自动编码器(Autoencoder)就能学习紧凑的特征向量表示,为后续的分类或回归任务提供支持。
-
文档和文本挖掘
在自然语言处理和信息检索领域,通过主题模型(如LDA)可以从海量文本中自动挖掘主题,从而帮助理解文档的主要内容或趋势。
常见算法
聚类算法
- K-Means
- 思想:将数据划分为K个类,并通过最小化类内差异来优化聚类结果。
- 优点:简单易实现;在低维数据上效果好。
- 缺点:需要预先指定聚类数K;对离群点敏感;容易陷入局部最优。
- 层次聚类(Hierarchical Clustering)
- 思想:通过递归地对样本进行合并或拆分,形成聚类层次结构。
- 优点:无需预先指定聚类数;能得到丰富的聚类层次树状结构。
- 缺点:计算量较大,且一旦合并或拆分就难以回退。
- DBSCAN
- 思想:基于密度,自动识别稠密区域并将这些样本聚为一类,离群点则被单独判定。
- 优点:可自动识别聚类数量;对噪声和离群值更鲁棒。
- 缺点:对参数(如ε和最小点数minPts)的选择较敏感。
降维与可视化
- PCA(主成分分析)
- 思想:寻找新的正交坐标系,使得最大方差方向作为主成分。
- 优点:计算效率高;易于解释。
- 缺点:只能发现线性结构,丢失部分可解释性特征。
- t-SNE
- 思想:将高维数据嵌入到2D或3D空间,通过最小化分布差异使相似的样本在低维空间中更接近。
- 优点:优秀的可视化效果,能保留局部结构。
- 缺点:对高维度且大规模数据集计算量大;参数调节比较难。
生成式模型
- 高斯混合模型(GMM)
- 思想:对数据分布假设为多个高斯分布的混合,通过EM算法迭代估计参数完成聚类和分布拟合。
- 优点:能够建模复杂的分布;可以计算各样本所属类的概率。
- 缺点:对初始参数敏感;适用场景需要满足高斯分布假设。
- 变分自编码器(VAE)
- 思想:通过编码器-解码器框架学习数据的隐变量分布,实现样本生成或特征提取。
- 优点:能生成新的数据样本;隐空间有良好的连续性和可操作性。
- 缺点:训练过程对超参数设置敏感,样本生成质量需要进一步提升。
神经网络方法
- 自组织映射(SOM)
- 思想:将高维输入映射到低维拓扑网络格子,保留邻域关系。
- 优点:擅长可视化与聚类;对非线性数据有较好适应性。
- 缺点:结果对网络拓扑结构和学习率敏感,解释性一般。
- 自动编码器(Autoencoder)
- 思想:通过网络“压缩+还原”来学习数据更高效的表示,用于降维、去噪或特征提取。
- 优点:适用于高维数据;可用于无监督的特征学习。
- 缺点:需要大量数据;网络结构和超参数的设计比较复杂。
总结与展望
非监督学习在解决实际问题的过程中扮演着关键角色,能帮助我们从海量无标签数据中挖掘潜在模式和结构。随着大数据和高性能计算的发展,非监督学习的方法将持续演进,比如基于深度学习的生成式模型、对比学习等前沿方法,让机器能够从越来越复杂、海量的无标签数据中获取洞察。
非监督学习的挑战主要在于:
- 对算法收敛性的把控,以及超参数调优难度大;
- 缺乏外部标签的客观标准,难以评估模型好坏;
- 模型可解释性与可视化效果依旧需要不断提升。
然而,基于非监督学习的强大潜力,不断涌现的研究与创新正逐渐克服这些限制,为各行各业带来更多自动化与智能化的可能。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!