目录
在众多机器学习方法中,监督学习(Supervised Learning)是一种应用最为广泛、技术最为成熟的分支。它通过给定的带标签(label)数据,让模型学会从输入(feature)到输出(label)的映射关系,并在此基础上对未知数据进行预测。下面将对监督学习的基本概念、常用算法、训练过程以及评估指标等方面进行详细说明。
监督学习的基本概念
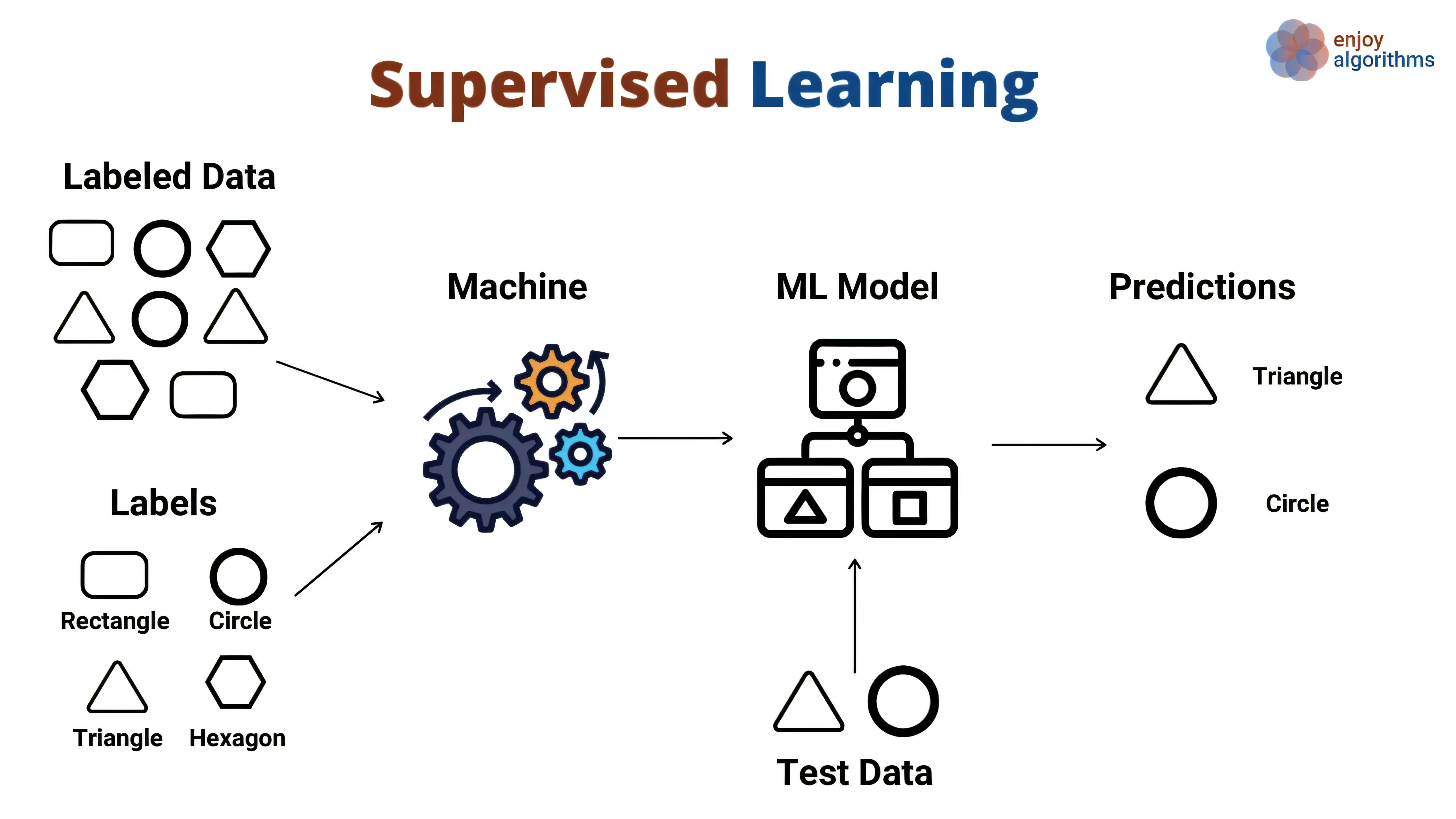
监督学习的核心在于“输入特征”与“目标输出”之间的函数映射。模型通过学习已有数据集(包含已知的输入和对应的正确输出),不断迭代更新其内部参数(如神经网络的权重,线性回归的系数等),从而使模型能够在未见过的新数据上也做出尽可能准确的预测。
中文注释:
- 输入特征(features):样本所具有的可测量属性或维度。
- 目标输出(label):在模型训练时作为“正确答案”的标签信息,用于指导模型学习。
根据预测任务的不同,监督学习一般分为以下两类:
- 回归问题(Regression):输出结果为连续值,例如房价预测、温度预测等。
- 分类问题(Classification):输出结果为离散类别,例如垃圾邮件识别、图像分类等。
常见的监督学习算法
- 线性回归(Linear Regression)
-
用于回归任务,根据最小二乘法或其他优化手段,拟合出一条或多条超平面。
-
演示公式:
-
适用于特征和目标值之间线性相关或近似线性的场景。
-
- Logistic回归(Logistic Regression)
- 常用于二分类任务,实际上是一种通过Logistic函数(Sigmoid函数)来实现分类的回归模型。
- 将线性回归的输出映射到(0,1)区间,用于表示某个类别的概率。
- 决策树(Decision Tree)
- 通过树形结构来进行决策。每个节点对应一个特征的判断条件,从根节点开始,不断细化,直到叶节点给出预测结果。
- 算法如ID3、C4.5、CART等广泛应用。
- 随机森林(Random Forest)
- 由多棵决策树组成的集成模型,通过“投票”或“平均”获得最终结果,通常比单颗决策树更稳定、更准确。
- 支持向量机(SVM, Support Vector Machine)
- 寻找一个或多个能够最大化类之间间隔的超平面,用于分类、回归等多种任务。
- 对高维数据表现尤为出色,常结合核函数(Kernel)以处理非线性问题。
- 神经网络(Neural Networks)
- 由感知器(neurons)层层堆叠形成的功能强大的模型,可以在大规模数据集上捕捉复杂的特征映射关系。
- 通过反向传播(Backpropagation)更新权重,是深度学习的基础。
监督学习的训练过程
- 数据收集与准备
- 收集足够数量且具有代表性的带标签数据。
- 对数据进行清洗、去噪、格式转换等预处理。
- 划分训练集、验证集和测试集。
- 特征工程
- 特征提取与选择:对于语音、图像等复杂数据,往往需要从原始数据中提取可用特征。
- 特征缩放与归一化:保证不同特征间量级一致,常用方法包括标准化、归一化等。
- 模型建立与训练
- 选择合适的算法(如线性回归、决策树、神经网络等)。
- 设置超参数(如学习率、最大树深度、隐藏层神经元数量等)。
- 采用批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)或其他优化方法来迭代更新模型参数。
- 模型评估与调优
- 使用验证集对模型性能进行初步评估(如准确率、均方误差等指标)。
- 根据评估结果对模型参数或超参数进行调整,例如修改网络结构、正则化系数、树的深度等。
- 在测试集上最终评估模型的泛化能力,防止在训练集或验证集上过拟合。
模型评估指标
对于不同的任务(回归或者分类),常用的评估指标也各不相同。常见的指标包括:
回归指标:
- 均方误差(MSE):反映预测值与真实值之间的平均平方误差;误差越大,对结果影响越显著。
- 平均绝对误差(MAE):将误差绝对值进行平均,也可以衡量模型对于偏差的总体水平。
- R^2 决定系数:度量模型的解释能力,值越接近1表示模型越能解释数据的变动。
分类指标:
- 准确率(Accuracy):预测正确的样本占比,为最常见的分类指标,但在类别不平衡时可能不够客观。
- 精确率(Precision)与召回率(Recall):在正负样本比例不均衡的情况下,精确率与召回率能够更好地度量模型的性能。
- F1分数(F1 Score):精确率和召回率的调和平均,综合考虑了两者平衡。
- ROC曲线和AUC值:直观展现不同阈值下模型对正负样本的区分能力,AUC越大通常表示模型区分度越好。
常见问题与实践建议
- 过拟合(Overfitting)
- 当模型在训练集上表现很好,但在新数据上效果差时,就可能存在过拟合。
- 对策包括:使用更多数据、数据增强、正则化(L1/L2)、提高Dropout率、减少模型复杂度等。
- 欠拟合(Underfitting)
- 当模型对训练数据都无法拟合时,可能特征不足或模型太简单。
- 对策包括:增加特征、使用更复杂模型、调整模型结构或参数等。
- 数据偏差
- 训练数据不具代表性或存在偏差,会导致模型泛化能力降低。
- 建议在数据收集阶段充分保证多样性与均衡性。
- 特征选择与工程
- 有意义的特征通常对模型性能帮助很大。
- 需要结合领域知识,通过相关性分析、降维等方法来优化特征。
总结
监督学习是机器学习中最基础、最成熟的领域之一,涵盖回归与分类两大类问题。通过学习带标签的数据,模型可以建模输入与输出之间的映射关系,并对新数据进行预测。无论是传统的统计学习方法(线性回归、SVM等)还是深度学习模型(神经网络),都离不开高质量的数据与有效的特征工程。在实际应用中,需要合理地设计训练流程、挑选评估指标、控制过拟合与欠拟合,以确保模型在真实场景中具备良好的泛化性能。
中文注释:
- 监督学习是机器学习中的重要分支,广泛应用在工业、医疗、金融、互联网等领域。
- 整个实践过程中,数据质量、算法选择以及评估方式都关系到最终模型的效果。
希望这篇文章能帮助你更好地理解监督学习,并在日常工作或研究中有效地利用这些算法技术。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录