目录
在这个信息爆炸的时代,程序员们经常需要从各种网页中提取有价值的内容。传统的爬虫要么暴力抓取全部内容,要么需要针对每个网站手写复杂的解析规则。如果告诉你,现在可以让AI自动分析网页结构,精准定位主要内容区域,你会不会觉得这就是你一直在寻找的解决方案?
本文将带你深入了解如何结合Semantic Kernel、HtmlAgilityPack和AI模型,构建一个智能的网页内容提取和总结工具。这不仅是一次技术实践,更是探索AI在传统爬虫领域的创新应用。
🔍 传统爬虫的三大痛点
痛点一:网页结构千变万化
每个网站的HTML结构都不同,新闻网站、技术博客、电商平台的内容区域完全不一样。传统方案需要为每种网站类型编写专门的提取规则。
痛点二:反爬虫机制越来越复杂
现代网站普遍部署了sophisticated的反爬虫策略:动态加载、验证码、频率限制、User-Agent检测等等。
痛点三:内容质量参差不齐
即使成功抓取到内容,如何从海量信息中提取真正有价值的部分,依然是个技术难题。
💡 AI驱动的智能解决方案
核心思路:三步走策略
第一步:获取网页的HTML框架结构(去除具体内容,保留标签结构)
第二步:让AI分析HTML结构,智能识别主体内容区域
第三步:根据AI推荐的选择器精准提取内容,并进行智能总结
这个方案的精妙之处在于:我们不是让AI处理完整的HTML内容,而是让它分析结构化的框架,这样既提高了准确性,又大大降低了token消耗。
🛠️ 代码实战:构建智能提取工具
🔧 项目准备
首先安装必要的NuGet包:
Bashdotnet add package HtmlAgilityPack dotnet add package Microsoft.SemanticKernel dotnet add package Microsoft.SemanticKernel.Connectors.OpenAI
🎯 核心架构设计
整个工具分为三个核心模块:
C#// 主程序流程
static async Task Main(string[] args)
{
// 1. 初始化AI服务
var kernel = InitializeSemanticKernel();
// 2. 获取HTML框架结构
var (html, htmlStructure) = await WebContentHelper.GetHtmlStructureAsync(url);
// 3. AI分析结构,推荐选择器
var recommendedSelector = await AnalyzeHtmlStructure(kernel, htmlStructure, url);
// 4. 提取内容并总结
var content = WebContentHelper.ExtractContentBySelector(url, recommendedSelector, html);
var summary = await SummarizeContent(kernel, content, url, recommendedSelector);
}
🧠 AI插件系统:让AI成为你的结构分析专家
这里是整个方案的核心创新点——AI插件系统:
C#// HTML结构分析插件
var htmlAnalysisPrompt = @"
你是专业的网页结构分析专家。请分析以下HTML框架结构,找出最可能包含主体文章内容的元素选择器。
## HTML框架结构:
{{$htmlStructure}}
请分析HTML结构,找出主体内容区域。常见的主体内容通常位于:
- article 标签
- main 标签
- 带有 id 或 class 包含 content、article、post、main、body 等关键词的div
只返回一个最佳的CSS选择器,不要其他解释文字。
";
var htmlAnalyzer = kernel.CreateFunctionFromPrompt(
promptTemplate: htmlAnalysisPrompt,
executionSettings: new OpenAIPromptExecutionSettings
{
MaxTokens = 200,
Temperature = 0.3 // 低温度保证结果稳定
},
functionName: "AnalyzeHtmlStructure"
);
关键技术点:
- 使用低温度(0.3)确保AI给出稳定、准确的选择器推荐
- 限制输出长度(200 tokens),避免AI输出冗余信息
- 明确指示AI只返回选择器,不要解释文字
🌐 反爬虫策略:模拟真实浏览器行为
C#private static void SetBrowserHeaders(HttpClient client)
{
client.DefaultRequestHeaders.Clear();
client.DefaultRequestHeaders.Add("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36");
client.DefaultRequestHeaders.Add("Accept",
"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
// 随机Referer策略
var referers = new[] {
"https://www.google.com/",
"https://www.bing.com/",
"https://www.baidu.com/"
};
client.DefaultRequestHeaders.Add("Referer",
referers[new Random().Next(referers.Length)]);
// 关键:自动解压缩
handler.AutomaticDecompression = DecompressionMethods.GZip |
DecompressionMethods.Deflate |
DecompressionMethods.Brotli;
}
📄 HTML结构清理:保留骨架,移除噪音
这是另一个技术亮点——智能HTML结构提取:
C#private static async Task<string> ProcessHtmlContent(string html)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
// 移除脚本和样式
var scriptsAndStyles = doc.DocumentNode.SelectNodes("//script | //style");
scriptsAndStyles?.ToList().ForEach(node => node.Remove());
// 清理文本节点,保留结构
CleanTextNodes(doc.DocumentNode);
string cleanHtml = doc.DocumentNode.OuterHtml;
// 压缩空白字符
cleanHtml = Regex.Replace(cleanHtml, @">\s+<", "><");
return cleanHtml;
}
private static void CleanTextNodes(HtmlNode node)
{
if (node.NodeType == HtmlNodeType.Text)
{
// 用占位符替代具体文本内容
if (!string.IsNullOrWhiteSpace(node.InnerText))
{
node.InnerHtml = "[TEXT]";
}
}
// 保留重要属性:id, class
var importantAttrs = new[] { "id", "class", "role" };
node.Attributes.Where(attr => !importantAttrs.Contains(attr.Name.ToLower()))
.ToArray()
.ToList()
.ForEach(attr => node.Attributes.Remove(attr));
}
🎯 智能内容提取:从选择器到文本
C#public static string ExtractContentBySelector(string url, string cssSelector, string html)
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
HtmlNode targetNode = null;
// 智能解析CSS选择器
cssSelector = cssSelector.Trim();
if (cssSelector.StartsWith("#"))
{
string id = cssSelector.Substring(1);
targetNode = doc.DocumentNode.SelectSingleNode($"//*[@id='{id}']");
}
else if (cssSelector.StartsWith("."))
{
string className = cssSelector.Substring(1);
targetNode = doc.DocumentNode.SelectSingleNode($"//*[contains(@class, '{className}')]");
}
else
{
targetNode = doc.DocumentNode.SelectSingleNode($"//{cssSelector}");
}
if (targetNode == null) return null;
// 清理干扰元素
var tagsToRemove = new[] { "script", "style", "nav", "header", "footer", "aside" };
foreach (var tag in tagsToRemove)
{
targetNode.SelectNodes($".//{tag}")?.ToList().ForEach(node => node.Remove());
}
return CleanTextContent(targetNode.InnerText);
}
完整例子
C#using HtmlAgilityPack;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using Microsoft.SemanticKernel;
using System.Text.RegularExpressions;
using System;
using System.Text;
using System.Net;
using System.Net.Http;
namespace AppAiWeb
{
class Program
{
static async Task Main(string[] args)
{
Console.OutputEncoding = System.Text.Encoding.UTF8;
Console.WriteLine("🌐 智能网页内容总结工具 - AI自动识别内容区域");
Console.WriteLine("请输入要总结的网页URL:");
var url = Console.ReadLine() ?? "";
if (string.IsNullOrWhiteSpace(url))
{
Console.WriteLine("❌ URL不能为空");
return;
}
// 初始化 Semantic Kernel
Console.WriteLine("🤖 正在初始化AI服务...");
var kernelBuilder = Kernel.CreateBuilder();
kernelBuilder.AddOpenAIChatCompletion(
modelId: "deepseek-chat",
apiKey: Environment.GetEnvironmentVariable("DEEPSEEK_API_KEY") ?? "sk-XXXXX",
endpoint: new Uri("https://api.deepseek.com/v1")
);
var kernel = kernelBuilder.Build();
// 注册所有插件
RegisterWebAnalysisPlugins(kernel);
try
{
// 第一步:获取HTML框架结构
Console.WriteLine("🔄 正在获取网页HTML框架...");
var (html, htmlStructure) = await WebContentHelper.GetHtmlStructureAsync(url);
if (string.IsNullOrWhiteSpace(htmlStructure))
{
Console.WriteLine("❌ 无法获取网页结构");
return;
}
Console.WriteLine($"📄 【HTML框架长度】:{htmlStructure.Length} 字符");
Console.WriteLine($"📝 【HTML结构预览(前300字)】\n{htmlStructure.Substring(0, Math.Min(300, htmlStructure.Length))}...\n");
// 第二步:AI分析HTML结构,识别主体内容区域
Console.WriteLine("🧠 AI正在分析HTML结构,识别主体内容区域...");
var structureAnalyzer = kernel.Plugins["WebAnalysisPlugin"]["AnalyzeHtmlStructure"];
var structureArgs = new KernelArguments
{
{ "htmlStructure", htmlStructure },
{ "url", url }
};
var selectorResult = await kernel.InvokeAsync(structureAnalyzer, structureArgs);
string recommendedSelector = selectorResult.GetValue<string>();
Console.WriteLine($"🎯 AI推荐的内容选择器:{recommendedSelector}");
// 第三步:根据AI推荐的选择器提取内容
Console.WriteLine("📖 正在提取主体内容...");
string mainContent = WebContentHelper.ExtractContentBySelector(url, recommendedSelector, html);
if (string.IsNullOrWhiteSpace(mainContent))
{
Console.WriteLine("❌ 无法根据推荐选择器提取内容,尝试备用方案...");
mainContent = WebContentHelper.ExtractContentBySelector(url, "body", html);
}
Console.WriteLine($"📄 【提取内容长度】:{mainContent.Length} 字符");
Console.WriteLine($"📝 【内容预览(前500字)】\n{mainContent.Substring(0, Math.Min(500, mainContent.Length))}...\n");
// 第四步:AI总结内容
Console.WriteLine("🧠 正在生成内容摘要...");
var summarizer = kernel.Plugins["WebAnalysisPlugin"]["SummarizeContent"];
var summaryArgs = new KernelArguments
{
{ "content", mainContent },
{ "url", url },
{ "selector", recommendedSelector }
};
var summarization = await kernel.InvokeAsync(summarizer, summaryArgs);
Console.WriteLine($"\n📋 【AI内容总结结果】\n");
Console.WriteLine(new string('=', 50));
Console.WriteLine(summarization.GetValue<string>());
Console.WriteLine(new string('=', 50));
}
catch (Exception ex)
{
Console.WriteLine($"❌ 处理过程中出现错误:{ex.Message}");
Console.WriteLine($"详细错误:{ex.StackTrace}");
}
Console.WriteLine("\n✅ 总结完成!按任意键退出...");
Console.ReadKey();
}
// 注册网页分析相关的所有插件
static void RegisterWebAnalysisPlugins(Kernel kernel)
{
// 插件1:分析HTML结构,识别主体内容区域
var htmlAnalysisPrompt = @"
你是专业的网页结构分析专家。请分析以下HTML框架结构,找出最可能包含主体文章内容的元素选择器。
## 网页URL: {{$url}}
## HTML框架结构:
{{$htmlStructure}}
请分析HTML结构,找出主体内容区域。常见的主体内容通常位于:
- article 标签
- main 标签
- 带有 id 或 class 包含 content、article、post、main、body 等关键词的div
- 最大的内容容器
分析步骤:
1. 查看是否有 <article> 或 <main> 标签
2. 查看是否有明显的内容相关的 id 或 class
3. 分析页面结构,找出最可能的主体内容区域
请只返回一个最佳的CSS选择器,格式如下几种之一:
- article
- main
- #post_detail
- .article-content
- #content
- .post-content
- div.main-content
只返回选择器,不要其他解释文字。
";
var htmlAnalyzer = kernel.CreateFunctionFromPrompt(
promptTemplate: htmlAnalysisPrompt,
executionSettings: new OpenAIPromptExecutionSettings
{
MaxTokens = 200,
Temperature = 0.3
},
functionName: "AnalyzeHtmlStructure",
description: "分析HTML结构,识别主体内容区域的CSS选择器"
);
// 插件2:内容总结
var contentSummaryPrompt = @"
你是专业的内容分析师,请对以下网页内容进行深度分析和总结:
## 来源网址: {{$url}}
## 使用的选择器: {{$selector}}
## 网页内容:
{{$content}}
请按以下格式提供详细的内容分析:
📖 **文章标题/主题识别**
[识别文章的核心主题]
🎯 **核心要点** (3-5个关键点)
• 要点1:[具体内容]
• 要点2:[具体内容]
• 要点3:[具体内容]
📊 **内容分类**
类型:[技术文档/新闻资讯/教程指南/产品介绍/其他]
领域:[相关行业或技术领域]
💡 **关键信息提取**
• 重要数据/时间:[提取关键数据]
• 人物/机构:[相关人物或组织]
• 技术要点:[技术相关的核心信息]
📝 **内容摘要** (200字以内)
[用简洁的语言概括整篇内容的精髓]
🔍 **价值评估**
• 信息价值:[高/中/低]
• 实用性:[评估实际应用价值]
• 时效性:[内容的时效性评估]
📌 **结论**
[一句话总结这篇文章的核心观点或价值]
";
var contentSummarizer = kernel.CreateFunctionFromPrompt(
promptTemplate: contentSummaryPrompt,
executionSettings: new OpenAIPromptExecutionSettings
{
MaxTokens = 1500,
Temperature = 0.7
},
functionName: "SummarizeContent",
description: "对提取的网页内容进行深度分析和总结"
);
// 插件3:快速摘要
var quickSummaryPrompt = @"
请用最简洁的语言(不超过100字)总结以下内容的核心要点:
内容:{{$content}}
要求:直接输出要点,不要格式化标记。
";
var quickSummarizer = kernel.CreateFunctionFromPrompt(
promptTemplate: quickSummaryPrompt,
executionSettings: new OpenAIPromptExecutionSettings
{
MaxTokens = 300,
Temperature = 0.5
},
functionName: "QuickSummary",
description: "生成简洁的内容摘要"
);
kernel.ImportPluginFromFunctions("WebAnalysisPlugin", [htmlAnalyzer, contentSummarizer, quickSummarizer]);
}
}
// 网页内容处理辅助类
public static class WebContentHelper
{
public static async Task<(string, string)> GetHtmlStructureAsync(string url)
{
try
{
// URL 格式化
if (!Regex.IsMatch(url, @"^https?://", RegexOptions.IgnoreCase))
url = "https://" + url;
Console.WriteLine($"🔗 正在访问:{url}");
using var handler = new HttpClientHandler()
{
// 自动处理cookie
UseCookies = true,
CookieContainer = new System.Net.CookieContainer(),
// SSL证书验证
ServerCertificateCustomValidationCallback = HttpClientHandler.DangerousAcceptAnyServerCertificateValidator,
// 关键:自动解压缩
AutomaticDecompression = DecompressionMethods.GZip | DecompressionMethods.Deflate | DecompressionMethods.Brotli
};
using var client = new HttpClient(handler);
SetBrowserHeaders(client);
// 设置超时时间
client.Timeout = TimeSpan.FromSeconds(60); // 增加到60秒
Console.WriteLine("🔄 尝试标准请求...");
try
{
// 尝试标准GET请求
var response = await client.GetAsync(url);
if (response.IsSuccessStatusCode)
{
var html = await response.Content.ReadAsStringAsync();
Console.WriteLine($"✅ 标准请求成功,HTML长度:{html.Length}");
return (html, await ProcessHtmlContent(html));
}
else
{
Console.WriteLine($"⚠️ 标准请求响应码:{response.StatusCode},尝试其他方法...");
}
}
catch (TaskCanceledException ex) when (ex.InnerException is TimeoutException)
{
Console.WriteLine("⚠️ 标准请求超时,尝试分段请求...");
}
catch (HttpRequestException ex)
{
Console.WriteLine($"⚠️ 标准请求失败:{ex.Message},尝试其他方法...");
}
return ("", "");
}
catch (Exception ex)
{
Console.WriteLine($"❌ 获取HTML结构失败:{ex.Message}");
return ("", "");
}
}
// 处理HTML内容的独立方法
private static async Task<string> ProcessHtmlContent(string html)
{
await Task.Delay(100); // 小延迟,模拟处理时间
Console.WriteLine($"📄 获取到原始HTML,长度:{html.Length} 字符");
// 使用 HtmlAgilityPack 解析并清理
var doc = new HtmlDocument();
doc.LoadHtml(html);
// 移除script和style标签
var scriptsAndStyles = doc.DocumentNode.SelectNodes("//script | //style");
if (scriptsAndStyles != null)
{
foreach (var node in scriptsAndStyles)
{
node.Remove();
}
}
// 移除注释
var comments = doc.DocumentNode.SelectNodes("//comment()");
if (comments != null)
{
foreach (var comment in comments)
{
comment.Remove();
}
}
// 清理所有文本节点,但保留标签结构和重要属性
CleanTextNodes(doc.DocumentNode);
// 获取清理后的HTML结构
string cleanHtml = doc.DocumentNode.OuterHtml;
// 进一步清理和格式化
cleanHtml = Regex.Replace(cleanHtml, @">\s+<", "><"); // 移除标签间空白
cleanHtml = Regex.Replace(cleanHtml, @"\s+", " "); // 合并多余空白
// 限制长度
if (cleanHtml.Length > 5000)
{
Console.WriteLine($"⚠️ HTML结构过长({cleanHtml.Length}字符),截取前5000字符");
cleanHtml = cleanHtml.Substring(0, 5000) + "...[HTML结构已截断]";
}
return cleanHtml;
}
// 内容提取方法
public static string ExtractContentBySelector(string url, string cssSelector, string html)
{
// 使用相同的反爬虫策略
try
{
var doc = new HtmlDocument();
doc.LoadHtml(html);
// 解析CSS选择器并查找对应元素
HtmlNode targetNode = null;
try
{
cssSelector = cssSelector.Trim();
if (cssSelector.StartsWith("#"))
{
string id = cssSelector.Substring(1);
targetNode = doc.DocumentNode.SelectSingleNode($"//*[@id='{id}']");
}
else if (cssSelector.StartsWith("."))
{
string className = cssSelector.Substring(1);
targetNode = doc.DocumentNode.SelectSingleNode($"//*[contains(@class, '{className}')]");
}
else
{
targetNode = doc.DocumentNode.SelectSingleNode($"//{cssSelector}");
}
}
catch
{
Console.WriteLine($"⚠️ 选择器解析失败,尝试标签选择器:{cssSelector}");
targetNode = doc.DocumentNode.SelectSingleNode($"//{cssSelector}");
}
if (targetNode == null)
{
Console.WriteLine($"❌ 未找到匹配选择器的元素:{cssSelector}");
return null;
}
Console.WriteLine($"✅ 成功找到目标元素:{cssSelector}");
// 清理不需要的标签
var tagsToRemove = new[] { "script", "style", "nav", "header", "footer", "aside", "iframe", "noscript" };
foreach (var tag in tagsToRemove)
{
var nodes = targetNode.SelectNodes($".//{tag}");
if (nodes != null)
{
foreach (var node in nodes.ToArray())
{
node.Remove();
}
}
}
// 提取文本内容
string textContent = targetNode.InnerText ?? "";
// 清理格式
textContent = System.Net.WebUtility.HtmlDecode(textContent);
textContent = Regex.Replace(textContent, @"\s+", " ");
textContent = Regex.Replace(textContent, @"^\s+|\s+$", "", RegexOptions.Multiline);
textContent = textContent.Trim();
// 限制长度
if (textContent.Length > 8000)
{
Console.WriteLine($"⚠️ 内容过长({textContent.Length}字符),截取前8000字符");
textContent = textContent.Substring(0, 8000) + "...[内容已截断]";
}
Console.WriteLine($"✅ 成功提取内容,长度:{textContent.Length} 字符");
return textContent;
}
catch (Exception ex)
{
Console.WriteLine($"❌ 内容提取失败:{ex.Message}");
return null;
}
}
// 设置浏览器请求头的辅助方法
private static void SetBrowserHeaders(HttpClient client)
{
client.DefaultRequestHeaders.Clear();
client.DefaultRequestHeaders.Add("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0");
client.DefaultRequestHeaders.Add("Accept",
"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8");
client.DefaultRequestHeaders.Add("Accept-Language", "zh-CN,zh;q=0.9,en;q=0.8");
client.DefaultRequestHeaders.Add("Accept-Encoding", "gzip, deflate, br");
client.DefaultRequestHeaders.Add("Cache-Control", "no-cache");
// 随机Referer
var referers = new[] { "https://www.google.com/", "https://www.bing.com/", "https://www.baidu.com/" };
client.DefaultRequestHeaders.Add("Referer", referers[new Random().Next(referers.Length)]);
client.DefaultRequestHeaders.Add("Sec-Fetch-Dest", "document");
client.DefaultRequestHeaders.Add("Sec-Fetch-Mode", "navigate");
client.DefaultRequestHeaders.Add("Sec-Fetch-Site", "cross-site");
client.DefaultRequestHeaders.Add("Upgrade-Insecure-Requests", "1");
}
// 递归清理文本节点,保留标签结构
private static void CleanTextNodes(HtmlNode node)
{
if (node.NodeType == HtmlNodeType.Text)
{
// 保留标签结构信息,但清空文本内容
if (!string.IsNullOrWhiteSpace(node.InnerText))
{
node.InnerHtml = "[TEXT]"; // 用占位符表示这里有文本
}
}
else
{
// 保留重要属性:id, class, 标签名
var attributesToKeep = new[] { "id", "class", "role", "data-role" };
var attributesToRemove = node.Attributes
.Where(attr => !attributesToKeep.Contains(attr.Name.ToLower()))
.ToArray();
foreach (var attr in attributesToRemove)
{
node.Attributes.Remove(attr);
}
// 递归处理子节点
foreach (var child in node.ChildNodes.ToArray())
{
CleanTextNodes(child);
}
}
}
}
}
🚀 实际应用效果

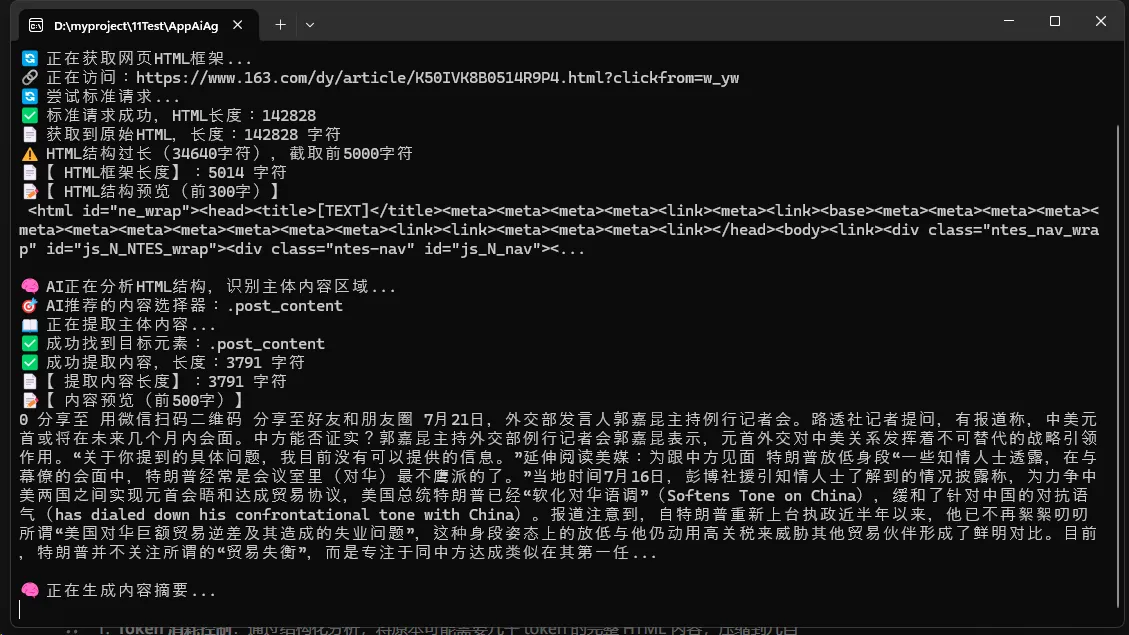
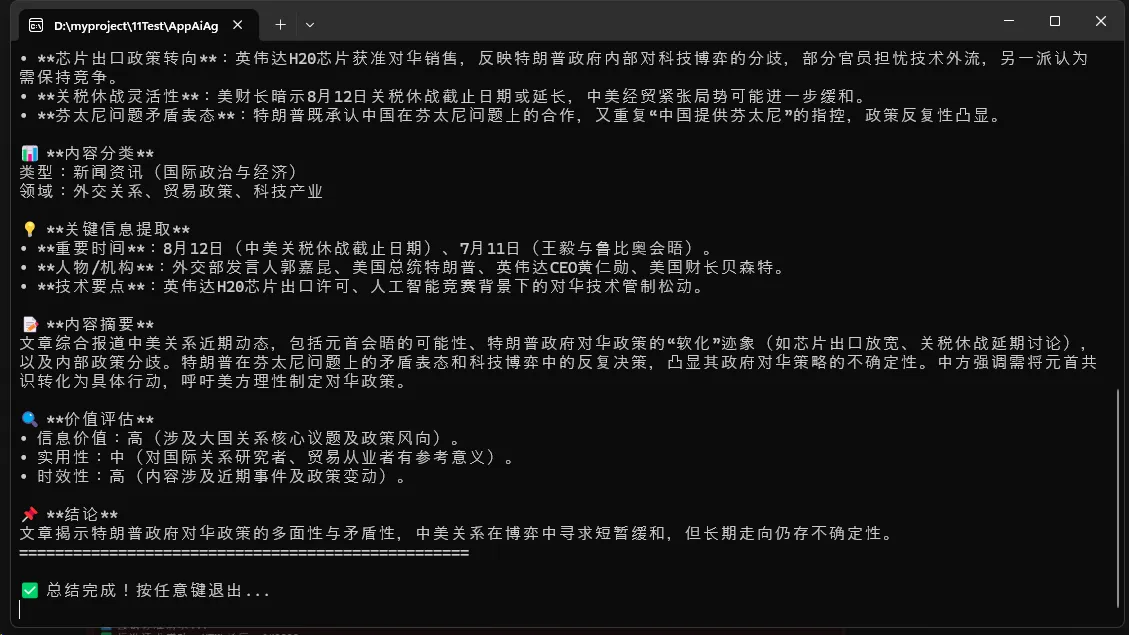
性能优化亮点
- Token消耗控制:通过结构化分析,将原本可能需要几千token的完整HTML内容,压缩到几百token的结构信息
- 准确率提升:AI专注于结构分析,而非内容理解,大大提高了选择器推荐的准确性
- 通用性强:一套代码适用于各种网站结构,无需针对性适配
⚠️ 开发避坑指南
坑点一:HttpClient配置不当
问题:很多网站返回乱码或空内容
解决方案:必须设置AutomaticDecompression处理gzip压缩
坑点二:AI提示词过于复杂
问题:AI返回冗长的分析文字而非选择器
解决方案:明确指示"只返回选择器,不要其他解释文字"
坑点三:内容长度限制
问题:超长内容导致API调用失败
解决方案:合理设置内容截断(HTML结构5000字符,正文内容8000字符)
💫 总结与思考
这个智能网页内容提取工具展现了AI + 传统技术结合的强大威力:
🎯 核心创新:让AI分析网页结构而非内容,实现了精准度和效率的完美平衡
🛠️ 技术融合:HtmlAgilityPack处理HTML解析,Semantic Kernel驱动AI能力,HttpClient处理网络请求
🚀 实用价值:一套代码适配所有网站,大幅降低了网页内容提取的开发成本
思考题:
- 如何进一步优化AI提示词,让选择器推荐更加精准?
- 面对动态加载的SPA应用,这套方案还需要哪些改进?
如果你正在开发内容聚合、信息监控或知识管理系统,这个方案绝对值得深入研究和应用。觉得有用请转发给更多同行,让AI赋能更多C#开发者!
想要完整源码或遇到技术问题?欢迎在评论区交流,我会第一时间回复大家的技术疑问!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!