目录
👋 你是否在实际项目中遇到过这样的困扰:一次性处理大集合,内存飙升、接口超时、日志刷屏?尤其是批量写库、调用第三方API、分片发送消息时,一个「全量 for 循环」就可能把系统拖垮。今天这篇文章,我们用一个简单却强大的工具——.NET 6 引入的 Enumerable.Chunk 方法,深入讲透「如何用最少代码实现高效、稳健的分批处理」。读完你将掌握 3-5 种在生产环境可直接落地的 C#开发 实战方案与编程技巧。
🧩 问题分析:为什么你需要分批处理?
在 C#开发 的日常业务里,以下痛点非常常见:
- 数据量大:一次性处理上万条记录,占用大量内存,GC 压力大,延迟升高。
- 外部依赖脆弱:数据库/外部API通常有限流或超时限制,大批量请求易失败。
- 可观测性差:失败重试定位困难,出错要么全错要么难以复现。
- 事务成本高:一次性事务跨度太大,锁时间长,阻塞其他业务。
分批处理(Chunking)能带来的价值:
- 控制单次负载,提升吞吐与稳定性;
- 更友好的失败重试与补偿策略;
- 更清晰的监控与日志切分;
- 代码更简洁,业务语义更明确。
🛠 解决方案概览
-
基础分批:用
Chunk(size)顺序处理 -
分批 + 并发:Chunk 后对每批并行执行
-
分批 + 重试:对外部服务的脆弱调用加入重试/熔断
-
分批 + 事务控制:每批一个事务,降低锁冲突
-
分批 + 流式读取:避免一次性加载全部内存(IAsyncEnumerable)
✅ 方案一:基础分批处理(最小可用)
适用场景:批量写库、批量缓存预热、批量写日志等对实时性要求不高的任务。
C#namespace AppChunk
{
internal class Program
{
static void Main(string[] args)
{
// 创建一个1到15的数字数组
int[] numbersList = Enumerable.Range(1, 15).ToArray();
// 使用Chunk方法将数组分成每组3个元素
var chunks = numbersList.Chunk(3);
// 遍历并打印每个块
Console.WriteLine(Environment.NewLine);
foreach (var chunk in chunks)
{
Console.WriteLine($"Chunk: {string.Join(", ", chunk)}");
// 实际处理逻辑:如批量入库、批量推送
}
Console.ReadKey();
}
}
}
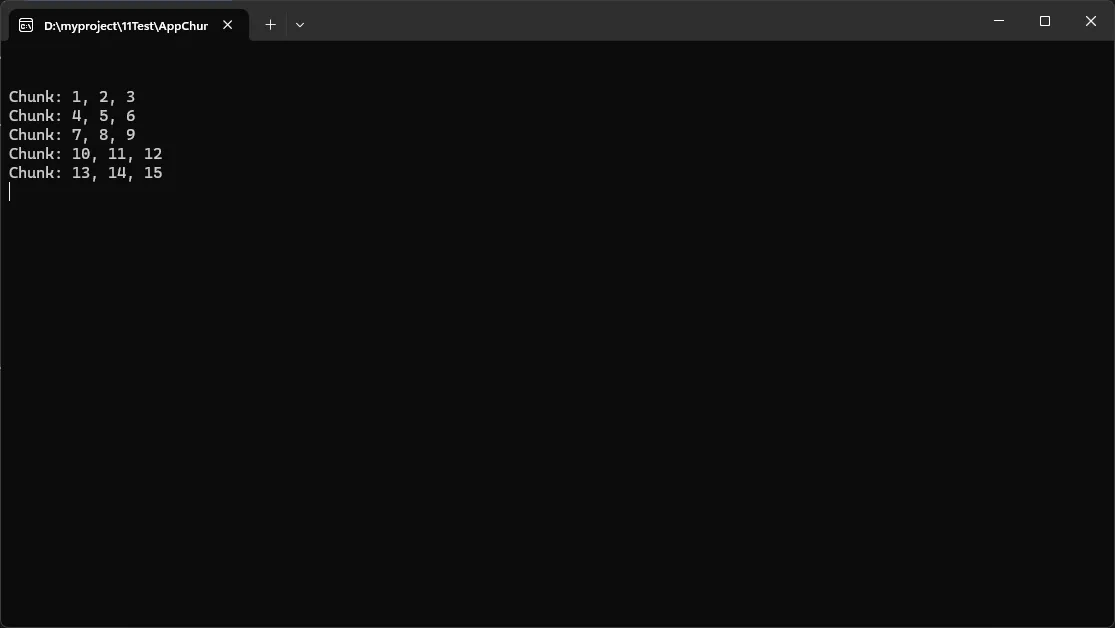
- 实际应用场景说明:定时任务将待处理数据按 100 条一批入库。
chunkSize 不宜过大,确保单批处理时间可控(建议 50~1000,按业务评估)。
Chunk会立即枚举源序列一次,源如果是昂贵迭代器,请先缓存或注意副作用。
⚡ 方案二:分批并发处理(提升吞吐)
适用场景:每批内部可独立处理,允许并发但需限流,避免压垮下游。
C#using System;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
class Program
{
static async Task Main()
{
var items = Enumerable.Range(1, 1000).ToArray();
int chunkSize = 100;
int maxDegreeOfParallelism = 4; // 并发批次上限
using var semaphore = new SemaphoreSlim(maxDegreeOfParallelism);
var tasks = items
.Chunk(chunkSize)
.Select(async chunk =>
{
await semaphore.WaitAsync();
try
{
// 模拟处理
await Task.Delay(100);
Console.WriteLine($"Processed batch: [{chunk.First()}..{chunk.Last()}] (size={chunk.Length})");
}
finally
{
semaphore.Release();
}
});
await Task.WhenAll(tasks);
}
}
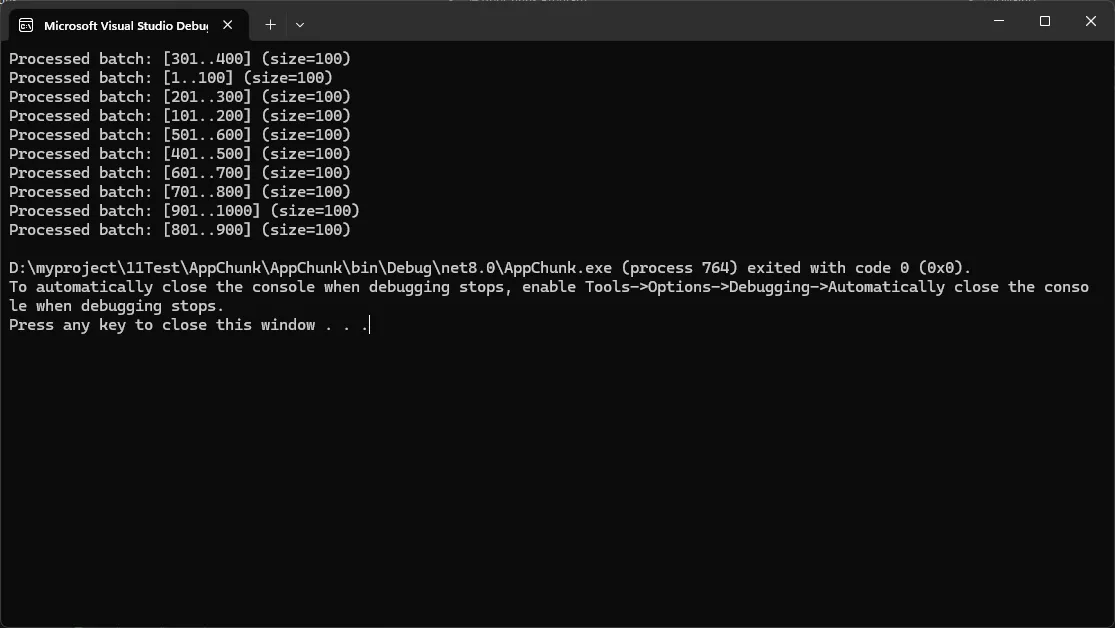
- 实际应用场景说明:将1000条消息按100条一批并发推送至消息队列,限制最多4个并发批次。
并发 ≠ 无限,务必使用信号量或通道控制并发度。 日志量控制,避免多线程下控制台/日志混乱;生产中建议结构化日志。
🛡 方案三:分批 + 重试与熔断(对抗脆弱外部依赖)
适用场景:调用第三方API或远程服务,偶发超时/限流/5xx。
C#using System;
namespace AppChunk
{
internal class Program
{
static async Task Main()
{
var client = new HttpClient { Timeout = TimeSpan.FromSeconds(5) };
var payloads = Enumerable.Range(1, 25).Select(i => $"data-{i}").ToArray();
foreach (var batch in payloads.Chunk(5))
{
// 对每批执行带重试的发送
await ExecuteWithRetry(async () =>
{
foreach (var item in batch)
{
var response = await client.PostAsync("https://httpbin.org/status/200", new StringContent(item));
response.EnsureSuccessStatusCode();
}
}, maxRetries: 3, backoffMs: 300, jitter: true);
Console.WriteLine($"Batch done: {string.Join(", ", batch)}");
}
}
static async Task ExecuteWithRetry(Func<Task> TaskAction, int maxRetries, int backoffMs, bool jitter)
{
int attempt = 0;
while (true)
{
try
{
await TaskAction();
return;
}
catch (Exception ex) when (attempt < maxRetries)
{
attempt++;
var delay = backoffMs * (int)Math.Pow(2, attempt);
if (jitter) delay += Random.Shared.Next(0, backoffMs);
Console.WriteLine($"Retry {attempt} after error: {ex.Message}, waiting {delay}ms");
await Task.Delay(delay);
}
}
}
}
}
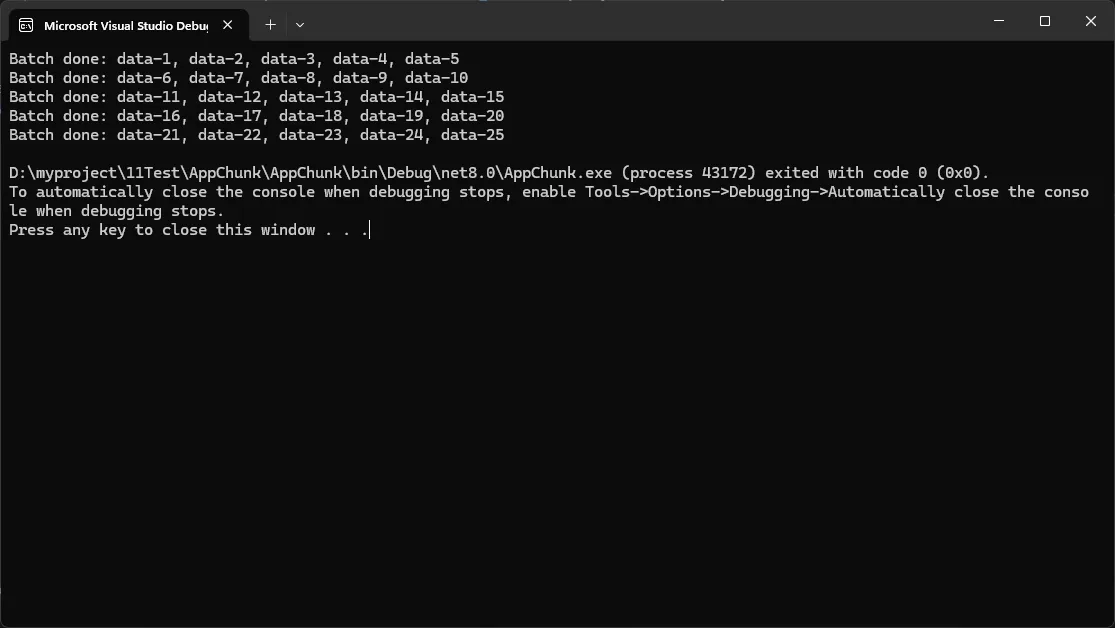
- 实际应用场景说明:批量上报埋点/订单状态到外部平台,网络抖动时自动指数回退重试。
区分可重试与不可重试错误(如 4xx 通常不应重试)。 建议引入熔断策略(如 Polly)防止雪崩:短时间内失败过多则快速失败并恢复探测。
💾 方案四:分批 + 事务控制(数据库写入更稳)
适用场景:批量写库但要控制锁范围与事务时长,降低阻塞。
C#using System;
using System.Data;
using System.Linq;
using Microsoft.Data.SqlClient;
class Program
{
static void Main()
{
var connectionString = "Server=.;Database=Demo;Trusted_Connection=True;TrustServerCertificate=True;";
var records = Enumerable.Range(1, 1000).Select(i => (Id: i, Name: $"User-{i}")).ToArray();
using var conn = new SqlConnection(connectionString);
conn.Open();
foreach (var batch in records.Chunk(200))
{
using var tx = conn.BeginTransaction(IsolationLevel.ReadCommitted);
try
{
foreach (var r in batch)
{
using var cmd = new SqlCommand("INSERT INTO Users(Id, Name) VALUES(@id, @name)", conn, tx);
cmd.Parameters.AddWithValue("@id", r.Id);
cmd.Parameters.AddWithValue("@name", r.Name);
cmd.ExecuteNonQuery();
}
tx.Commit();
Console.WriteLine($"Committed batch: [{batch.First().Id}..{batch.Last().Id}]");
}
catch (Exception ex)
{
tx.Rollback();
Console.WriteLine($"Rolled back batch due to: {ex.Message}");
// 记录并告警,必要时中止或进入重试逻辑
}
}
}
}
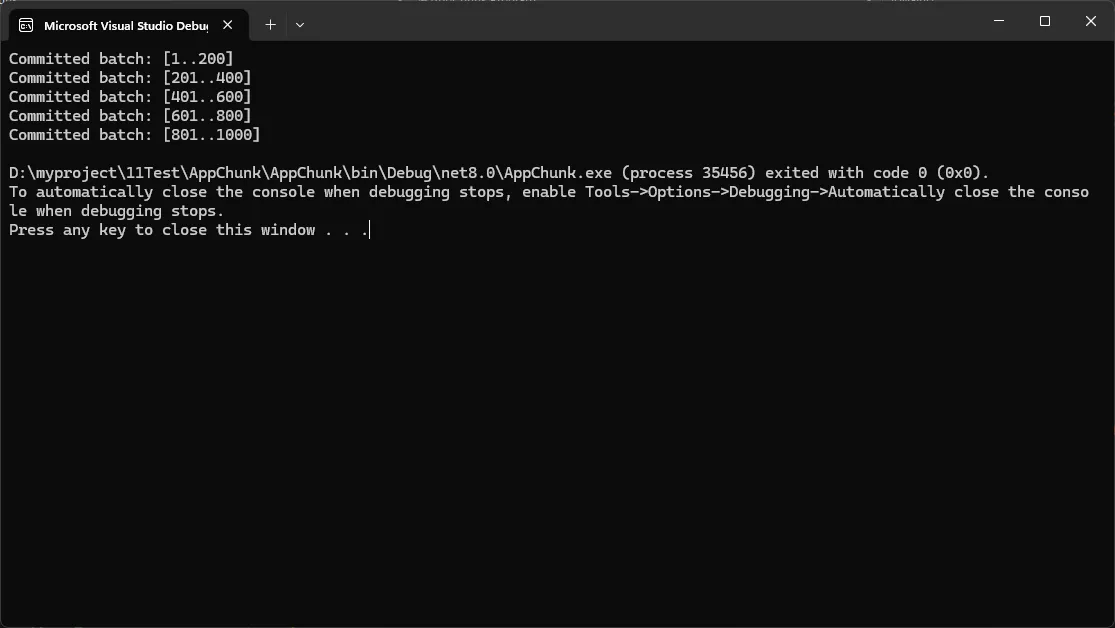
- 实际应用场景说明:迁移数据/初始化种子数据,避免单次事务过大导致锁竞争。
谨慎选择事务隔离级别,过高会放大锁竞争;过低可能脏读。 大批量写入可以考虑表级批量接口(如 SqlBulkCopy)配合分批,进一步提升性能。
🌊 方案五:分批 + 流式读取(IAsyncEnumerable 降内存)
适用场景:数据源很大(百万级),不能一次性加载内存。
C#using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
class Program
{
static async Task Main()
{
await foreach (var batch in ReadBigData().ChunkAsync(500))
{
// 对每批进行处理
Console.WriteLine($"Processing async batch size={batch.Length}");
await Task.Delay(10);
}
}
// 模拟异步流来源(数据库/消息队列)
static async IAsyncEnumerable<int> ReadBigData()
{
for (int i = 1; i <= 5000; i++)
{
await Task.Delay(1); // 模拟IO
yield return i;
}
}
}
// 扩展方法:为 IAsyncEnumerable 提供 ChunkAsync
static class AsyncEnumerableExtensions
{
public static async IAsyncEnumerable<T[]> ChunkAsync<T>(this IAsyncEnumerable<T> source, int size)
{
if (size <= 0) throw new ArgumentOutOfRangeException(nameof(size));
var buffer = new List<T>(size);
await foreach (var item in source)
{
buffer.Add(item);
if (buffer.Count == size)
{
yield return buffer.ToArray();
buffer.Clear();
}
}
if (buffer.Count > 0)
{
yield return buffer.ToArray();
}
}
}
- 实际应用场景说明:从外部存储/流式接口读取超大数据集,边读边处理,内存峰值可控。
自定义
ChunkAsync要注意异常传播与取消令牌(CancellationToken)支持。 流式场景下日志不要逐条打印,按批记录摘要。
🔗 延伸学习建议
- 了解 LINQ 的延迟执行与立即执行对性能的影响
- Polly 重试、熔断、隔离舱等韧性模式
- TPL 与通道(System.Threading.Channels)实现更先进的生产者-消费者
- SqlBulkCopy、EF Core 批量扩展库(如 EFCore.BulkExtensions)
🧠 金句总结
-
分批不是“慢”,它是用“可控的快”换“系统的稳”。
-
批量阈值可控、并发有限流、失败可重试,才是可靠的 C#开发 批处理三件套。
-
先把批次边界划清,再谈优化;边界清晰,问题就会简单。
🧰 收藏级代码模板
- 模板一:分批并发 + 限流 + 重试(通用壳)
C#public static async Task ProcessInBatchesAsync<T>(
IEnumerable<T> source,
int batchSize,
int maxParallelBatches,
Func<T[], Task> handleBatchAsync,
int retry = 3,
int backoffMs = 200)
{
using var semaphore = new SemaphoreSlim(maxParallelBatches);
var tasks = source
.Chunk(batchSize)
.Select(async batch =>
{
await semaphore.WaitAsync();
try
{
await ExecuteWithRetry(async () => await handleBatchAsync(batch), retry, backoffMs, jitter: true);
}
finally { semaphore.Release(); }
});
await Task.WhenAll(tasks);
static async Task ExecuteWithRetry(Func<Task> TaskAction, int maxRetries, int backoff, bool jitter)
{
int attempt = 0;
while (true)
{
try { await TaskAction(); return; }
catch when (attempt < maxRetries)
{
attempt++;
int delay = backoff * (int)Math.Pow(2, attempt) + (jitter ? Random.Shared.Next(0, backoff) : 0);
await Task.Delay(delay);
}
}
}
}
- 模板二:IAsyncEnumerable 分批处理
C#public static async IAsyncEnumerable<T[]> ChunkAsync<T>(this IAsyncEnumerable<T> source, int size)
{
if (size <= 0) throw new ArgumentOutOfRangeException(nameof(size));
var buffer = new List<T>(size);
await foreach (var item in source)
{
buffer.Add(item);
if (buffer.Count == size)
{
yield return buffer.ToArray();
buffer.Clear();
}
}
if (buffer.Count > 0) yield return buffer.ToArray();
}
🙋 互动
- 你在实际项目中通常把批大小设为多少?依据是什么?
- 在并发分批中,你更倾向使用信号量、数据通道,还是任务调度器?为什么?
欢迎在评论区分享你的使用经验或遇到的坑,我们一起打磨更稳的生产方案。觉得有用请转发给更多同行!
🔚 结尾
本文围绕 C#开发 中的分批处理展开,核心有三点:
- 用
Enumerable.Chunk明确批次边界,降低单次处理成本,实现可控的稳定性。 - 将分批与并发控制、重试熔断、事务管理、流式读取组合,形成可落地的实战方案。
- 通过模板化封装与合理监控,把分批从“技巧”升级为“工程能力”,在大数据量、脆弱外部依赖场景下显著提升系统韧性。
实践出真知,把今天的示例粘到你的项目里跑一遍,看看性能曲线和失败率的变化。若本文对你有帮助,别忘了点个在看并分享给需要的同事与朋友!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!