目录
你是否曾经为了维护一个没有注释、代码风格混乱的Python项目而头疼不已?或者在团队协作中,因为每个人的编码习惯不同而导致代码难以理解和维护?良好的注释规范和统一的代码风格,不仅能让你的代码更加专业和易读,还能显著提升开发效率和团队协作质量。
本文将从实际Windows开发环境出发,详细解析Python注释规范与PEP8代码风格标准,通过丰富的代码实例和最佳实践,帮你打造高质量、易维护的Python代码。无论你是Python初学者还是有经验的开发者,这篇文章都将为你的编程技能提升提供实用的指导。
🔍 问题分析:为什么需要规范的注释和代码风格?
💥 常见的代码问题
在日常的Python开发和上位机开发中,我们经常遇到这些问题:
Python# 糟糕的代码示例
def calc(x,y,z):
if x>0:
result=x*y+z
else:
result=x*y-z
return result
data=[1,2,3,4,5]
for i in range(len(data)):
if data[i]%2==0:
print(data[i])
这样的代码存在哪些问题?
- 可读性差:函数名不清晰,参数意义不明
- 格式混乱:缺少空格,缩进不统一
- 缺少注释:无法理解代码的业务逻辑
- 维护困难:后续修改和调试成本极高
📊 规范代码的价值
根据软件工程统计,规范的代码风格和完善的注释能够:
- 🚀 提升开发效率25%:减少理解和调试时间
- 🛡️ 降低Bug率30%:清晰的逻辑减少错误
- 👥 改善团队协作:统一标准便于多人维护
- 📈 提高代码质量:符合行业最佳实践
🛠️ 解决方案:PEP8标准与注释规范详解
📋 PEP8核心规范
**PEP8(Python Enhancement Proposal 8)**是Python官方的代码风格指南,以下是核心要点:
🎨 代码布局和缩进
Python# ✅ 正确的代码布局
def calculate_area(length: float, width: float) -> float:
"""
计算矩形面积
Args:
length: 矩形长度
width: 矩形宽度
Returns:
float: 矩形面积
"""
if length <= 0 or width <= 0:
raise ValueError("长度和宽度必须大于0")
area = length * width
return area
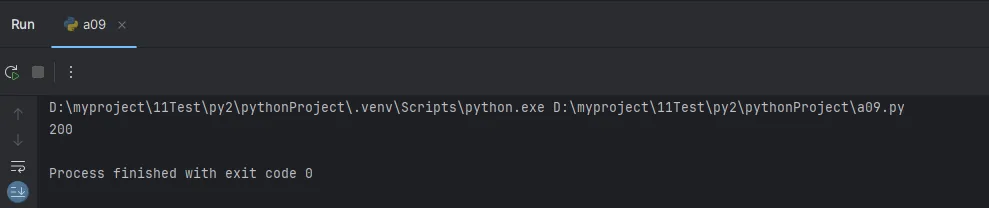
print(calculate_area(10, 20))
Python# ✅ 类定义规范
class DataProcessor:
"""数据处理器类"""
def __init__(self, data_source: str):
self.data_source = data_source
self._processed_count = 0
def process_data(self) -> dict:
"""处理数据的主要方法"""
# 实现细节...
pass
🔤 命名规范
Python# ✅ 推荐的命名方式
# 变量和函数:小写字母+下划线
user_name = "张三"
total_amount = 1000.50
def get_user_info():
"""获取用户信息"""
pass
def calculate_tax_amount(income: float) -> float:
"""计算税额"""
pass
# 类名:首字母大写的驼峰命名
class UserManager:
"""用户管理器"""
pass
class DatabaseConnection:
"""数据库连接类"""
pass
# 常量:全大写字母+下划线
MAX_CONNECTION_COUNT = 100
DEFAULT_TIMEOUT = 30
API_BASE_URL = "https://api.com"
# 私有属性:单下划线开头
class Employee:
def __init__(self, name: str):
self.name = name
self._salary = 0 # 受保护的属性
self.__id = None # 私有属性
📏 行长度和空行规范
Python# ✅ 行长度控制(建议不超过88字符)
def process_employee_data(employee_list: List[dict],
department_filter: str = None,
include_inactive: bool = False) -> List[dict]:
"""
处理员工数据,支持部门筛选和状态过滤
这个函数演示了如何正确处理长参数列表
"""
pass
Python# ✅ 正确的空行使用
import json
import os
import sys
from typing import List, Dict, Optional
# 两个空行分隔顶级定义
DEFAULT_CONFIG = {
'timeout': 30,
'retry_count': 3
}
class ConfigManager:
"""配置管理器"""
def __init__(self):
self.config = {}
def load_config(self, file_path: str) -> bool:
"""加载配置文件"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
self.config = json.load(f)
self._validate_config()
self._apply_defaults()
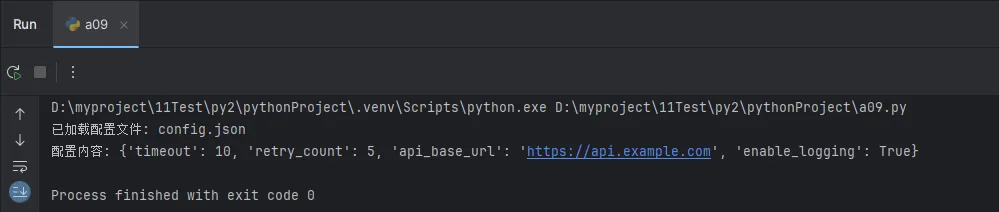
print(f"已加载配置文件: {file_path}")
print(f"配置内容: {self.config}")
return True
except Exception as e:
print(f"配置加载失败: {e}")
return False
def _validate_config(self):
"""验证配置文件(占位方法)"""
pass
def _apply_defaults(self):
"""应用默认配置(占位方法)"""
pass
config = ConfigManager()
config.load_config('config.json')
📝 Python注释规范详解
🎯 文档字符串(Docstring)
Pythonfrom typing import Optional
def connect_to_database(host: str, port: int, username: str,
password: str, database: str) -> Optional[object]:
"""
连接到数据库服务器
这个函数用于建立与数据库的连接,支持MySQL和PostgreSQL。
在Windows环境下,建议使用连接池来提高性能。
Args:
host (str): 数据库服务器地址
port (int): 数据库端口号
username (str): 用户名
password (str): 密码
database (str): 数据库名称
Returns:
Optional[object]: 数据库连接对象,连接失败时返回None
Raises:
ConnectionError: 当无法建立连接时抛出
ValueError: 当参数格式不正确时抛出
Examples:
>>> conn = connect_to_database('localhost', 3306, 'root', 'password', 'mydb')
>>> if conn:
... print("连接成功")
Note:
在Windows环境下,请确保已安装相应的数据库驱动程序
"""
pass
💬 行内注释规范
Pythonfrom typing import List
def process_sales_data(data: List[dict]) -> dict:
"""处理销售数据"""
total_sales = 0 # 总销售额
valid_orders = [] # 有效订单列表
for order in data:
# 检查订单有效性
if order.get('amount', 0) > 0 and order.get('status') == 'completed':
valid_orders.append(order)
total_sales += order['amount'] # 累计销售额
# TODO: 添加订单异常处理逻辑
# FIXME: 处理重复订单问题
return {
'total_sales': total_sales,
'order_count': len(valid_orders),
'average_order_value': total_sales / len(valid_orders) if valid_orders else 0
}
# 👇 例如准备一段测试数据
orders = [
{'id': 1, 'amount': 100, 'status': 'completed'},
{'id': 2, 'amount': 0, 'status': 'completed'}, # 金额为0,无效
{'id': 3, 'amount': 200, 'status': 'completed'},
{'id': 4, 'amount': -50, 'status': 'completed'}, # 金额为负,无效
{'id': 5, 'amount': 300, 'status': 'pending'}, # 状态不是completed,无效
{'id': 6, 'amount': 150, 'status': 'completed'}
]
# 调用方法
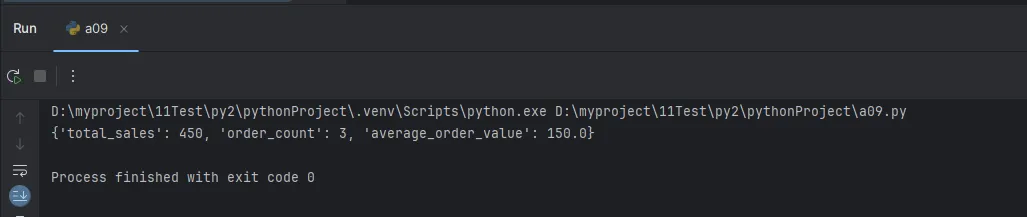
result = process_sales_data(orders)
# 打印处理结果
print(result)
🔧 类和模块注释
Python#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
上位机数据采集模块
这个模块提供了与PLC设备通信的功能,支持Modbus TCP协议。
主要用于工业自动化项目中的数据采集和监控。
Author: 张三
Date: 2024-06-28
Version: 1.0.0
Dependencies:
- pymodbus>=3.0.0
- asyncio
Usage:
from data_collector import PLCCollector
collector = PLCCollector('192.168.1.100', 502)
data = collector.read_holding_registers(0, 10)
"""
import asyncio
import logging
from typing import List, Dict, Optional
from pymodbus.client import ModbusTcpClient
class PLCCollector:
"""
PLC数据采集器
这个类封装了与PLC设备通信的相关功能,支持读取和写入操作。
适用于Modbus TCP协议的工业设备。
Attributes:
host (str): PLC设备IP地址
port (int): 通信端口号
client (ModbusTcpClient): Modbus客户端实例
is_connected (bool): 连接状态
Examples:
>>> collector = PLCCollector('192.168.1.100', 502)
>>> collector.connect()
>>> data = collector.read_holding_registers(0, 10)
>>> collector.disconnect()
"""
def __init__(self, host: str, port: int = 502):
"""
初始化PLC采集器
Args:
host: PLC设备IP地址
port: Modbus TCP端口号,默认502
"""
self.host = host
self.port = port
self.client = None
self.is_connected = False
# 配置日志
logging.basicConfig(level=logging.INFO)
self.logger = logging.getLogger(__name__)
💻 代码实战:Windows环境下的最佳实践
🚀 项目结构规范
Python# 项目目录结构示例
"""
my_project/
├── src/
│ ├── __init__.py
│ ├── main.py
│ ├── config/
│ │ ├── __init__.py
│ │ └── settings.py
│ ├── utils/
│ │ ├── __init__.py
│ │ ├── file_helper.py
│ │ └── data_processor.py
│ └── models/
│ ├── __init__.py
│ └── user.py
├── tests/
├── docs/
├── requirements.txt
└── README.md
"""
# src/config/settings.py
"""
应用程序配置模块
集中管理应用程序的各种配置参数,支持不同环境的配置切换。
"""
import os
from pathlib import Path
from typing import Dict, Any
class AppConfig:
"""应用程序配置类"""
# 基础配置
APP_NAME = "数据采集系统"
VERSION = "1.0.0"
DEBUG = os.getenv('DEBUG', 'False').lower() == 'true'
# 文件路径配置(Windows环境)
BASE_DIR = Path(__file__).parent.parent
DATA_DIR = BASE_DIR / 'data'
LOG_DIR = BASE_DIR / 'logs'
# 数据库配置
DATABASE_CONFIG = {
'host': os.getenv('DB_HOST', 'localhost'),
'port': int(os.getenv('DB_PORT', '3306')),
'username': os.getenv('DB_USER', 'root'),
'password': os.getenv('DB_PASSWORD', ''),
'database': os.getenv('DB_NAME', 'myapp')
}
@classmethod
def get_config(cls) -> Dict[str, Any]:
"""获取完整配置字典"""
return {
'app_name': cls.APP_NAME,
'version': cls.VERSION,
'debug': cls.DEBUG,
'database': cls.DATABASE_CONFIG,
'paths': {
'base': str(cls.BASE_DIR),
'data': str(cls.DATA_DIR),
'log': str(cls.LOG_DIR)
}
}
🛠️ 异常处理和日志规范
Python# src/utils/file_helper.py
"""
文件操作辅助模块
提供文件读写、路径处理等常用功能,针对Windows环境进行了优化。
"""
import json
import logging
from pathlib import Path
from typing import Any, Optional, Union
class FileHelper:
"""文件操作辅助类"""
def __init__(self, base_path: Union[str, Path] = None):
"""
初始化文件助手
Args:
base_path: 基础路径,默认为当前目录
"""
self.base_path = Path(base_path) if base_path else Path.cwd()
self.logger = logging.getLogger(__name__)
def read_json_file(self, file_path: Union[str, Path]) -> Optional[dict]:
"""
读取JSON文件
Args:
file_path: 文件路径(相对或绝对路径)
Returns:
Optional[dict]: JSON数据,读取失败时返回None
Raises:
FileNotFoundError: 文件不存在
json.JSONDecodeError: JSON格式错误
"""
try:
# 处理相对路径
if not Path(file_path).is_absolute():
file_path = self.base_path / file_path
self.logger.info(f"正在读取JSON文件: {file_path}")
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
self.logger.info(f"成功读取JSON文件,包含 {len(data)} 个键")
return data
except FileNotFoundError:
self.logger.error(f"文件不存在: {file_path}")
raise
except json.JSONDecodeError as e:
self.logger.error(f"JSON格式错误: {file_path}, 错误信息: {e}")
raise
except Exception as e:
self.logger.error(f"读取文件时发生未知错误: {e}")
return None
def write_json_file(self, data: dict, file_path: Union[str, Path],
ensure_ascii: bool = False) -> bool:
"""
写入JSON文件
Args:
data: 要写入的数据
file_path: 文件路径
ensure_ascii: 是否确保ASCII编码(中文处理)
Returns:
bool: 写入是否成功
"""
try:
# 处理相对路径
if not Path(file_path).is_absolute():
file_path = self.base_path / file_path
# 确保目录存在
file_path.parent.mkdir(parents=True, exist_ok=True)
self.logger.info(f"正在写入JSON文件: {file_path}")
with open(file_path, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=ensure_ascii,
indent=2, separators=(',', ': '))
self.logger.info(f"成功写入JSON文件: {file_path}")
return True
except Exception as e:
self.logger.error(f"写入文件失败: {file_path}, 错误信息: {e}")
return False
# 1. 实例化 FileHelper(可选传 base_path,比如放在指定目录下)
file_helper = FileHelper(base_path="./") # 或省略参数使用当前目录
# 2. 读取 JSON 文件
try:
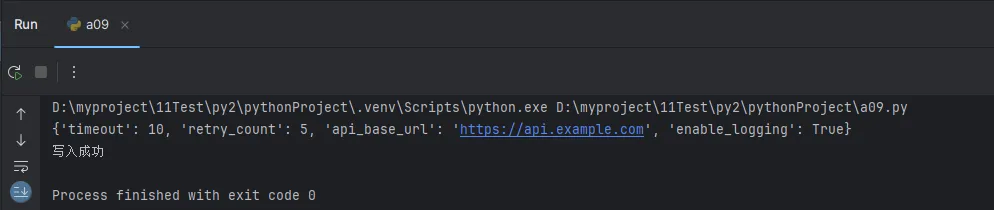
data = file_helper.read_json_file("config.json")
print(data)
except Exception as e:
print(f"读取文件失败: {e}")
# 3. 写入 JSON 文件
success = file_helper.write_json_file({'a': 1, 'b': 2}, "data_out.json")
print("写入成功" if success else "写入失败")
🎛️ 完整的类设计示例
Python# src/models/user.py
"""
用户模型模块
定义用户相关的数据模型和业务逻辑,遵循面向对象设计原则。
"""
from datetime import datetime
from typing import Optional, List, Dict
from dataclasses import dataclass, field
from enum import Enum
class UserRole(Enum):
"""用户角色枚举"""
ADMIN = "administrator"
USER = "user"
GUEST = "guest"
@dataclass
class User:
"""
用户数据模型
使用dataclass简化用户对象的创建和管理,提供类型注解和默认值。
Attributes:
id: 用户唯一标识
username: 用户名
email: 邮箱地址
role: 用户角色
created_at: 创建时间
last_login: 最后登录时间
is_active: 账户是否激活
profile: 用户资料信息
"""
id: Optional[int] = None
username: str = ""
email: str = ""
role: UserRole = UserRole.USER
created_at: datetime = field(default_factory=datetime.now)
last_login: Optional[datetime] = None
is_active: bool = True
profile: Dict[str, str] = field(default_factory=dict)
def __post_init__(self):
"""数据初始化后的验证"""
if not self.username:
raise ValueError("用户名不能为空")
if not self.email or '@' not in self.email:
raise ValueError("邮箱格式不正确")
def update_last_login(self) -> None:
"""更新最后登录时间"""
self.last_login = datetime.now()
def is_admin(self) -> bool:
"""检查是否为管理员"""
return self.role == UserRole.ADMIN
def get_display_name(self) -> str:
"""获取显示名称"""
return self.profile.get('display_name', self.username)
def to_dict(self) -> Dict:
"""转换为字典格式"""
return {
'id': self.id,
'username': self.username,
'email': self.email,
'role': self.role.value,
'created_at': self.created_at.isoformat(),
'last_login': self.last_login.isoformat() if self.last_login else None,
'is_active': self.is_active,
'profile': self.profile
}
class UserManager:
"""
用户管理器
负责用户对象的创建、查询、更新和删除操作。
实现了基本的用户管理业务逻辑。
"""
def __init__(self):
"""初始化用户管理器"""
self._users: Dict[int, User] = {}
self._next_id = 1
def create_user(self, username: str, email: str,
role: UserRole = UserRole.USER) -> User:
"""
创建新用户
Args:
username: 用户名
email: 邮箱地址
role: 用户角色,默认为普通用户
Returns:
User: 创建的用户对象
Raises:
ValueError: 用户名已存在或参数无效
"""
# 检查用户名是否已存在
if self.get_user_by_username(username):
raise ValueError(f"用户名 '{username}' 已存在")
# 创建用户对象
user = User(
id=self._next_id,
username=username,
email=email,
role=role
)
# 保存用户
self._users[user.id] = user
self._next_id += 1
return user
def get_user_by_id(self, user_id: int) -> Optional[User]:
"""根据ID获取用户"""
return self._users.get(user_id)
def get_user_by_username(self, username: str) -> Optional[User]:
"""根据用户名获取用户"""
for user in self._users.values():
if user.username == username:
return user
return None
def get_active_users(self) -> List[User]:
"""获取所有激活的用户"""
return [user for user in self._users.values() if user.is_active]
def deactivate_user(self, user_id: int) -> bool:
"""停用用户账户"""
user = self.get_user_by_id(user_id)
if user:
user.is_active = False
return True
return False
# 创建用户管理器实例
user_manager = UserManager()
# 新建用户
user1 = user_manager.create_user(username="alice", email="alice@example.com", role=UserRole.ADMIN)
user2 = user_manager.create_user(username="bob", email="bob@example.com") # 默认为普通用户
# 获取用户(通过ID)
fetch_user = user_manager.get_user_by_id(user1.id)
print(fetch_user.to_dict())
# 获取用户(通过用户名)
fetch_user2 = user_manager.get_user_by_username("bob")
print(fetch_user2.to_dict())
# 列出所有激活用户
active_users = user_manager.get_active_users()
for u in active_users:
print(u.to_dict())
# 停用一个用户
user_manager.deactivate_user(user2.id)
# 查看停用后的激活用户
active_users = user_manager.get_active_users()
for u in active_users:
print(u.to_dict())

🎯 总结与实践建议
通过本文的详细解析,我们深入了解了Python注释规范与PEP8代码风格的核心要点。让我总结三个关键要点,帮你在实际Python开发和上位机开发项目中快速应用这些最佳实践:
🔑 核心要点总结
1. 统一的代码风格是团队协作的基石
- 严格遵循PEP8命名规范:变量用小写+下划线,类名用驼峰式
- 控制行长度在88字符以内,合理使用空行分隔逻辑块
- 配置代码格式化工具(如black、pylint),实现自动化规范检查
2. 完善的注释体系提升代码可维护性
- 为每个函数和类编写详细的docstring,包含参数说明和返回值
- 使用行内注释解释复杂的业务逻辑,避免过度注释简单代码
- 在Windows开发环境下,特别注意编码声明和路径处理的注释说明
3. 实践中的渐进式改进策略
- 从新项目开始严格执行规范,对老项目采用渐进式重构
- 在IDE中配置代码格式化和检查插件,形成良好的编程习惯
- 建立代码审查机制,确保团队成员都能遵循统一的编程技巧标准
记住,优秀的代码不仅仅是能够运行,更要具备良好的可读性和可维护性。这些Python开发规范看似繁琐,但它们是构建高质量软件系统的重要基础。从今天开始,让我们一起写出更加专业、优雅的Python代码!
如果这篇文章对你的Python开发有帮助,欢迎分享给更多的朋友。在实践过程中遇到问题,也欢迎留言讨论,让我们一起提升编程技能!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录