目录
聚合函数是 SQL 中非常重要的一类函数,它们能够对一组值进行计算,并返回单一结果。这些函数在数据分析、报表生成和复杂查询中扮演着关键角色。本文将深入探讨 SQLite 聚合函数的各个方面,包括其定义、类型、用法、高级特性以及最佳实践。
什么是聚合函数?
聚合函数是对一组值执行计算并返回单个结果的函数。它们通常用于数据汇总、统计分析和报表生成。聚合函数在处理大量数据时特别有用,可以快速提供数据的概览和洞察。
SQLite 中的标准聚合函数
SQLite 提供了以下标准聚合函数:
- count():计算行数或非 NULL 值的数量。
- sum():计算一组数值的总和。
- avg():计算一组数值的平均值。
- max():返回一组值中的最大值。
- min():返回一组值中的最小值。
- group_concat():将一组字符串连接成一个字符串。
- total():类似于 sum(),但返回浮点数。
准备测试数据
SQL-- 创建员工表
CREATE TABLE employees (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
department TEXT NOT NULL,
salary REAL
);
-- 创建部门字段的索引以优化GROUP BY查询
CREATE INDEX idx_department ON employees(department);
-- 插入示例数据
INSERT INTO employees (name, department, salary) VALUES
('张三', '人力资源', 60000),
('李四', '工程部', 75000),
('王五', '人力资源', 50000),
('赵六', '工程部', 80000),
('钱七', '销售部', 55000),
('孙八', '销售部', 45000),
('周九', '工程部', 70000),
('吴十', '人力资源', 48000),
('郑十一', '销售部', 62000),
('刘十二', '工程部', 85000);
聚合函数的基本用法
以下是一些基本用法示例:
SQL-- 计算总行数
SELECT count(*) FROM employees;
-- 计算工资总和
SELECT sum(salary) FROM employees;
-- 计算平均工资
SELECT avg(salary) FROM employees;
-- 找出最高工资
SELECT max(salary) FROM employees;
-- 找出最低工资
SELECT min(salary) FROM employees;
-- 连接所有员工姓名
SELECT group_concat(name, ', ') FROM employees;
GROUP BY 子句与聚合函数
GROUP BY 子句通常与聚合函数一起使用,用于对数据进行分组计算:
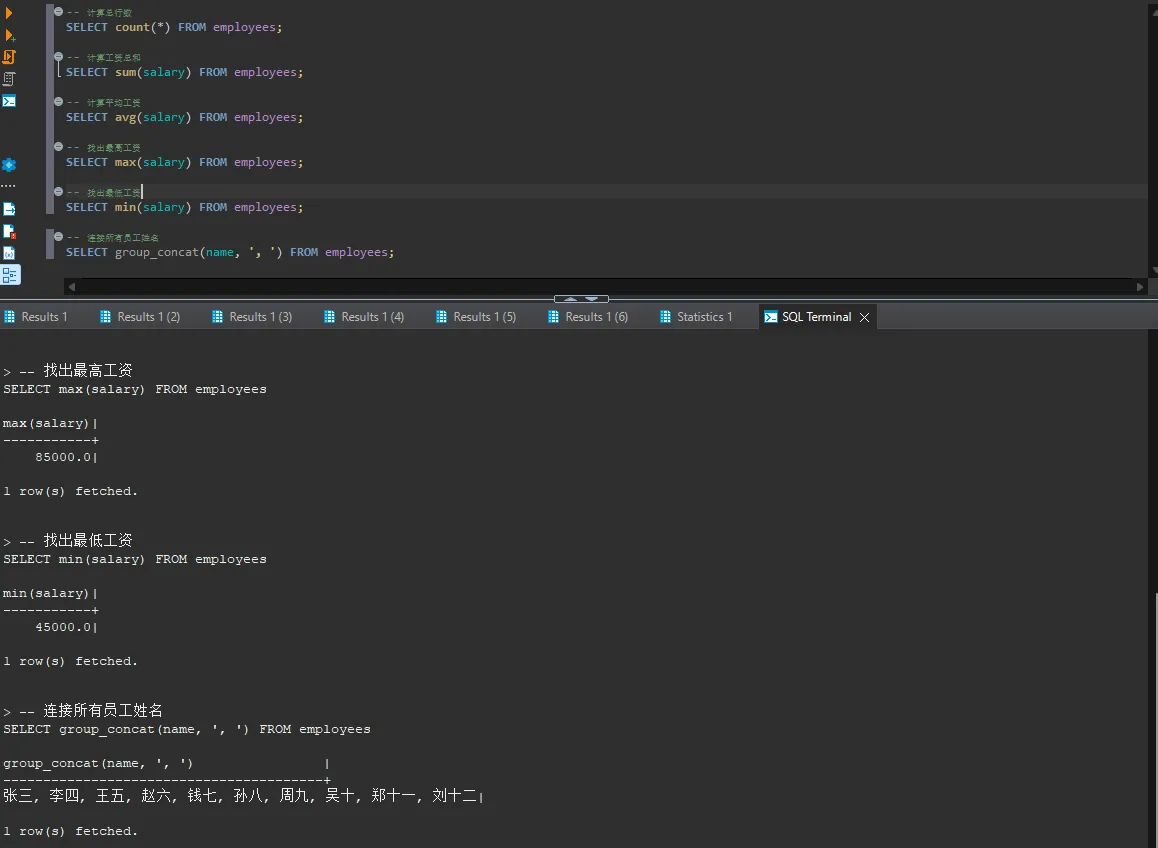
SQL-- 按部门计算平均工资
SELECT department, avg(salary) AS avg_salary
FROM employees
GROUP BY department;
-- 计算每个部门的员工数量
SELECT department, count(*) AS employee_count
FROM employees
GROUP BY department;
HAVING 子句
HAVING 子句用于过滤分组后的结果:
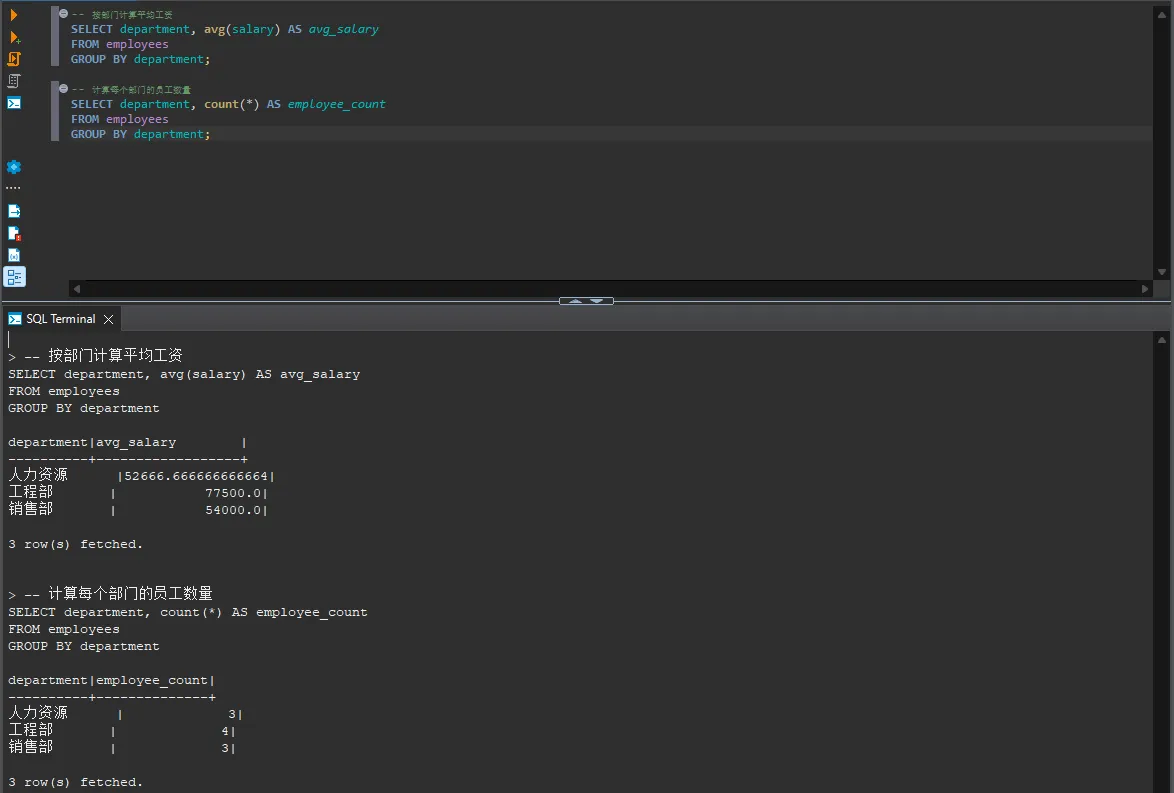
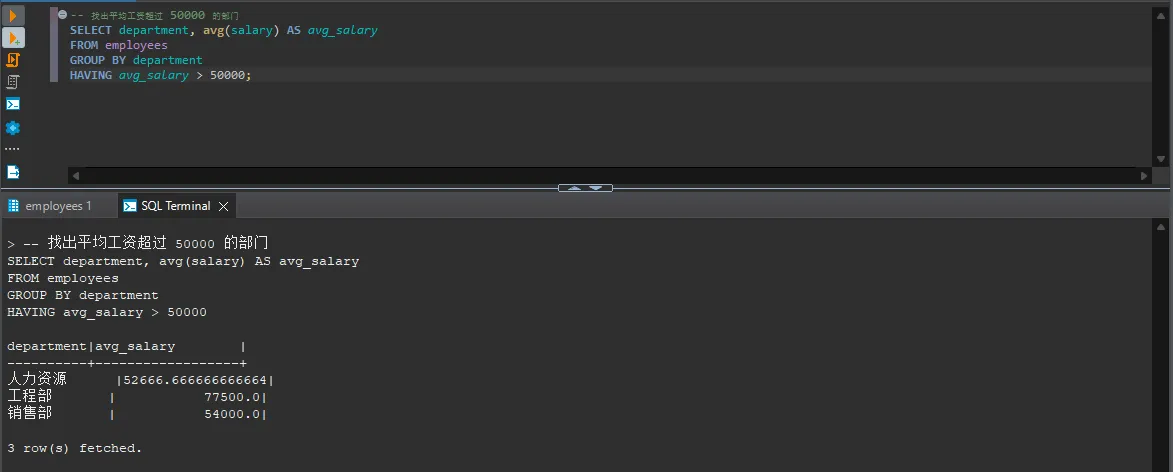
SQL-- 找出平均工资超过 50000 的部门
SELECT department, avg(salary) AS avg_salary
FROM employees
GROUP BY department
HAVING avg_salary > 50000;
窗口函数中的聚合
从 SQLite 3.25.0 版本开始,支持窗口函数,这允许在更复杂的场景中使用聚合函数:
SQL-- 计算每个员工的工资和部门平均工资
SELECT name, salary,
avg(salary) OVER (PARTITION BY department) AS dept_avg_salary
FROM employees;
-- 计算累计工资总和
SELECT name, salary,
sum(salary) OVER (ORDER BY salary) AS running_total
FROM employees;
自定义聚合函数
SQLite 允许创建自定义聚合函数。这通常通过 C API 或特定语言的绑定来实现。例如,可以创建一个计算中位数的函数:
C++// C 代码示例(简化版)
static void medianStep(sqlite3_context *context, int argc, sqlite3_value **argv) {
// 实现步骤逻辑
}
static void medianFinalize(sqlite3_context *context) {
// 实现最终计算逻辑
}
// 注册函数
sqlite3_create_function(db, "median", 1, SQLITE_UTF8, NULL, NULL, medianStep, medianFinalize);
使用自定义函数:
SQLSELECT median(salary) FROM employees;
聚合函数的高级用法
-
条件聚合
使用 CASE 语句进行条件聚合:
SQLSELECT
count(CASE WHEN salary > 50000 THEN 1 END) AS high_salary_count,
count(CASE WHEN salary <= 50000 THEN 1 END) AS low_salary_count
FROM employees;
-
嵌套聚合
在某些情况下可以嵌套使用聚合函数:
SQLSELECT avg(total_salary) AS avg_dept_total
FROM (
SELECT department, sum(salary) AS total_salary
FROM employees
GROUP BY department
);
- 聚合函数与子查询
SQLSELECT name, salary,
(SELECT avg(salary) FROM employees) AS overall_avg_salary
FROM employees;
聚合函数与 NULL 值
聚合函数处理 NULL 值的方式:
- count(*):包括 NULL 值在内的所有行。
- count(column):不包括 NULL 值。
- sum(), avg(), max(), min():忽略 NULL 值。
示例:
SQLSELECT
count(*) AS total_rows,
count(salary) AS salary_count,
avg(salary) AS avg_salary
FROM employees;
聚合函数的性能考虑
- 索引使用:确保 GROUP BY 子句中的列有适当的索引。
- 内存使用:大量数据的聚合可能消耗大量内存。
- 分批处理:对于大数据集,考虑分批处理或使用临时表。
- 避免过度使用:复杂的聚合查询可能影响性能,考虑在应用层处理部分逻辑。
聚合函数的最佳实践
- 选择合适的函数:使用最适合任务的聚合函数。
- 注意数据类型:确保输入数据类型与聚合函数兼容。
- 处理 NULL 值:了解并适当处理 NULL 值对结果的影响。
- 使用 EXPLAIN:分析查询计划以优化性能。
- 合理分组:避免过度细粒度的分组,可能导致性能问题。
- 结合其他 SQL 特性:灵活使用 CASE、子查询等与聚合函数结合。
- 定期维护统计信息:确保数据库统计信息是最新的,以优化查询计划。
结论
SQLite 的聚合函数是进行数据分析和生成报告的强大工具。从基本的计数和求和到复杂的条件聚合和窗口函数,这些功能为数据处理提供了极大的灵活性。正确使用聚合函数不仅可以简化查询逻辑,还能显著提高数据处理的效率。
然而,使用聚合函数时也需要谨慎。过度复杂的聚合查询可能导致性能问题,特别是在处理大量数据时。因此,在设计查询时,需要平衡查询的复杂性和性能需求。
通过深入理解聚合函数的工作原理、适用场景以及最佳实践,开发者可以充分利用 SQLite 的这一强大特性,构建出高效、灵活的数据分析解决方案。无论是在移动应用、桌面软件还是嵌入式系统中,聚合函数都是处理和分析数据的关键工具。
最后,随着 SQLite 不断evolve,我们可以期待未来版本中聚合函数的进一步增强和优化。持续学习和实践将有助于开发者充分发挥 SQLite 聚合函数的潜力,创造出更加强大和高效的数据库应用。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!