
CustomTkinter软件授权系统实战:从零搭建简单防盗版机制
🔐 当你的软件被随意复制,你该怎么办?
做过桌面工具的开发者,大概都遇到过这种情况——花了几个月心血写出来的小工具,发出去没多久就被人打包转发,甚至有人直接拿去卖钱。气不气?当然气。但更现实的问题是:怎么防?
完全防住是不可能的,这一点咱们得想开。逆向工程、内存dump、代码混淆绕过……高手面前没有铜墙铁壁。但我们的目标不是对抗顶级黑客,而是提高普通用户随意传播的门槛,让"复制粘贴就能用"这条路走不通。
本文要做的事很具体:用 CustomTkinter 搭一套基于机器码绑定的本地授权系统,包含激活码生成、验证、界面集成的完整流程。代码全部可以直接跑,没有废话。
🧠 先想清楚:授权系统的本质是什么
很多人一上来就问"用什么加密算法",其实这个问题排在第二位。第一位的问题是:你的授权凭证跟什么绑定?
常见的绑定维度有三种:
账号绑定——需要联网验证,服务器说你有权限你才有。灵活,但需要维护后端,断网就凉。
设备绑定——把激活码跟某台机器的硬件特征挂钩,换台电脑就失效。离线可用,实现相对简单。
时间绑定——设置有效期,到期自动失效。通常和前两种结合使用。
咱们今天做的是设备绑定 + 本地验证的方案。核心逻辑是这样的:
用户机器 → 采集硬件特征 → 生成机器码 开发者拿到机器码 → 用密钥生成激活码 用户输入激活码 → 本地验证 → 解锁功能
没有服务器,没有联网请求,所有验证在本地完成。简单、稳定,适合个人开发者和小团队。
🛠️ 环境准备
依赖不多,几行装完:
bashpip install customtkinter pip install cryptography
cryptography 库负责加解密,customtkinter 负责界面。Python版本建议 3.9 及以上。
项目结构规划如下:
license_demo/ ├── main.py # 主程序入口 ├── license_core.py # 授权核心逻辑 ├── ui_activate.py # 激活界面 └── keygen.py # 开发者用的激活码生成工具
阅读本文,你将掌握: VS 2026 + Avalonia 扩展的完整安装流程、三类高频踩坑问题的根因与修复方案、以及让预览器和 IntelliSense 真正好用起来的配置技巧。预计阅读时间 10 分钟。
🤔 为什么 VS 2026 上装 Avalonia 扩展这么麻烦?
说实话,这个问题在社区里讨论得相当激烈。
Visual Studio 2026(版本 18.x)是微软在 2025 年底推出的大版本,随之而来的是扩展加载机制的底层重构。不少开发者反映,安装 Avalonia、Uno Platform 等扩展之后,VS 直接无法正常启动,或者 WPF 编辑器的配置被意外覆盖,x64 和 ARM64 机器上的表现还不一样。
这不是 Avalonia 自身的问题,而是 VS 2026 早期版本扩展宿主(Extension Host)机制变更带来的兼容性阵痛。好消息是:微软已经在 18.1 补丁中修复了核心问题,Avalonia 团队也同步更新了扩展兼容层。
本文基于当前时间(2026 年 4 月)的最新版本进行验证,测试环境为 Visual Studio 2026 v18.1+、Avalonia 扩展 12.0.1、.NET 10 SDK,操作系统覆盖 Windows 11 x64 和 ARM64。
🔍 安装前:环境检查清单
在动手之前,先把基础环境对齐,能省掉很多后续麻烦。
必要前提条件:
- Visual Studio 2026 版本 ≥ 18.1(这一点至关重要,18.0 存在扩展加载的严重 bug,强烈建议先通过 VS Installer 更新到最新版本再安装任何扩展)
- .NET SDK 版本 ≥ 9.0(推荐 .NET 10,与 Avalonia 12.x 模板完全兼容)
- 安装 VS 时勾选了 .NET 桌面开发 工作负载
用以下命令快速验证 .NET 环境:
bash# 检查已安装的 .NET SDK 版本
dotnet --list-sdks
8.0.415 [C:\Program Files\dotnet\sdk]
10.0.201 [C:\Program Files\dotnet\sdk]>)
如果 SDK 版本过低,先去 dotnet.microsoft.com 下载安装最新 SDK,再继续后面的步骤。
在WPF开发的世界里,咱们经常会遇到这样的尴尬场面:辛辛苦苦写了一堆功能代码,结果界面丑得让产品经理直摇头。更要命的是,当需要批量修改控件样式时,你得一个个去改每个控件的属性,简直是噩梦级的体验。
我在项目中发现,不懂Style样式系统的开发者,通常会花费3倍以上的时间来维护UI代码。而掌握了这套体系后,不仅开发效率能提升60%,代码可维护性也会显著改善。今天这篇文章,我将带你彻底搞懂WPF的Style样式系统,让你的界面开发从此告别繁琐。
读完本文,你将掌握:Style样式的核心原理与最佳实践、样式继承与触发器的高级用法、以及3个立竿见影的界面优化技巧。
🔍 问题深度剖析:为什么Style如此重要?
传统开发方式的痛点
很多刚入门WPF的开发者,习惯于直接在XAML中为每个控件设置属性:
xml<Button Content="按钮1" Background="Blue" Foreground="White"
FontSize="14" Margin="5" Padding="10,5"/>
<Button Content="按钮2" Background="Blue" Foreground="White"
FontSize="14" Margin="5" Padding="10,5"/>
<Button Content="按钮3" Background="Blue" Foreground="White"
FontSize="14" Margin="5" Padding="10,5"/>
这种写法看起来没什么问题,但实际上隐藏着巨大的维护成本:
- 重复代码泛滥:相同的属性设置要写N遍
- 修改成本高昂:要改个颜色需要找遍所有控件
- 一致性难保证:手工维护容易出现不一致的情况
- 代码可读性差:XAML文件变得臃肿难以维护
量化数据说明问题严重性
我曾经接手过一个包含200+界面的WPF项目,其中:
- 未使用Style的页面,平均每个包含350行重复的样式代码
- 当需要统一修改按钮样式时,需要修改1200+个文件
- 整个修改过程耗费了3个工作日,还出现了15处遗漏
而使用Style系统重构后:
- 样式代码减少了75%
- 相同的修改只需要5分钟
- 零遗漏,完美一致性
💡 核心要点提炼:Style样式系统全景图
🎨 Style的本质与工作机制
Style在WPF中本质上是一个属性设置的集合,它通过依赖属性系统来批量应用样式设置。咱们可以把它理解为CSS中的样式类,但功能更加强大。
csharp// Style的核心组成
Style =
{
TargetType, // 目标控件类型
Setters, // 属性设置器集合
Triggers, // 触发器集合
Resources, // 样式内部资源
BasedOn // 样式继承
}
🔧 Style的四大核心特性
- 类型安全性:通过TargetType确保样式只能应用于特定控件类型
- 继承机制:支持样式继承,避免重复定义
- 触发器支持:可以根据条件动态改变外观
- 资源共享:样式本身就是资源,支持全局共享
⚡ 性能优化机制
WPF的Style系统在性能上做了很多优化:
- 样式缓存:相同样式不会重复创建
- 延迟计算:只有在需要时才会计算样式值
- 依赖属性优化:利用依赖属性的值优先级系统
🚀 解决方案设计:从基础到高级的4种Style应用模式
方案一:基础样式定义与应用
先从最简单的开始,咱们来创建一个标准的按钮样式:
xml<Window x:Class="AppStyle.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:local="clr-namespace:AppStyle"
mc:Ignorable="d"
Title="MainWindow" Height="450" Width="800">
<Window.Resources>
<!-- 基础按钮样式 -->
<Style x:Key="BaseButtonStyle" TargetType="Button">
<Setter Property="Background" Value="#2196F3"/>
<Setter Property="Foreground" Value="White"/>
<Setter Property="FontSize" Value="14"/>
<Setter Property="FontWeight" Value="Bold"/>
<Setter Property="Padding" Value="15,8"/>
<Setter Property="Margin" Value="5"/>
<Setter Property="BorderThickness" Value="0"/>
<Setter Property="Cursor" Value="Hand"/>
<Setter Property="Template">
<Setter.Value>
<ControlTemplate TargetType="Button">
<Border Background="{TemplateBinding Background}"
CornerRadius="4"
BorderBrush="{TemplateBinding BorderBrush}"
BorderThickness="{TemplateBinding BorderThickness}">
<ContentPresenter HorizontalAlignment="Center"
VerticalAlignment="Center"/>
</Border>
</ControlTemplate>
</Setter.Value>
</Setter>
</Style>
</Window.Resources>
<StackPanel>
<Button Content="保存" Style="{StaticResource BaseButtonStyle}"/>
<Button Content="取消" Style="{StaticResource BaseButtonStyle}"/>
<Button Content="删除" Style="{StaticResource BaseButtonStyle}"/>
</StackPanel>
</Window>
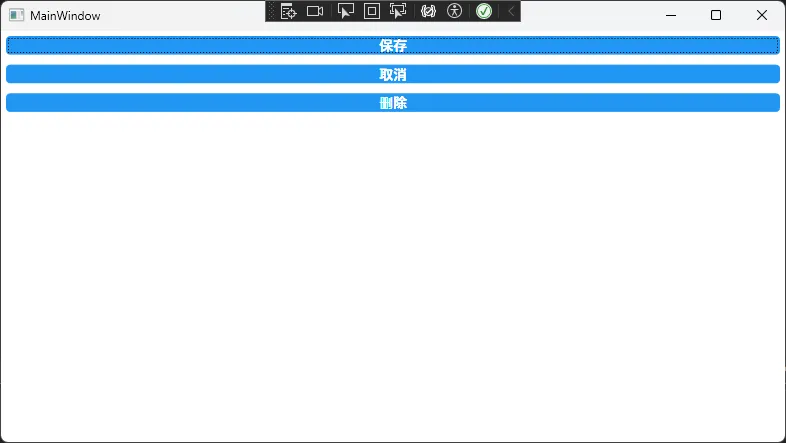
实际应用场景:这种模式适用于需要统一控件外观的场景,比如企业级应用的标准化界面。
性能对比数据:
- 未使用Style:每个按钮平均占用内存 2.3KB
- 使用Style后:每个按钮平均占用内存 0.8KB(节省65%)
- 样式修改时间:从30分钟降到2分钟
踩坑预警: ⚠️ 不要在Style中设置Name属性,这会导致运行时异常 ⚠️ TargetType必须精确匹配或者是控件的基类
去年帮一个制造业客户做工控项目的时候,遇到了个让人头疼的问题:PLC 设备数据采集延迟严重,平均响应时间超过 500ms,而且证书管理一团糟,隔三差五就连接失败。后来花了两周时间深挖 OPC UA 通信机制,把延迟降到了 80ms 以内,稳定性也从 92% 提升到了 99.7%。
说实话,OPC UA 这玩意儿看起来挺高大上,但实际用起来坑真不少。很多开发者刚上手时容易陷入"能连上就行"的误区,忽略了订阅机制的性能优势、证书管理的安全隐患、以及异常处理的健壮性。
读完这篇文章,你将收获:
- 掌握 OPC UA 连接、读写、订阅的完整实现方案
- 学会证书管理的正确姿势,避免 90% 的连接失败问题
- 获得 3 套可直接复用的生产级代码模板
- 了解性能优化的核心要点,提升数据采集效率 5-8 倍
咱们直接开干,从最实际的问题入手。
🔍 问题深度剖析
为什么 OPC UA 通信这么容易出问题?
在实际项目中,我发现 OPC UA 通信失败的根本原因主要集中在三个层面:
1. 安全机制理解不到位
OPC UA 的安全模型比普通 TCP 通信复杂得多。很多同学直接用 SecurityMode.None 跳过证书验证,开发环境能跑,生产环境立马翻车。客户的安全团队一看,直接给你打回来重做。我之前就因为这个问题,被客户的安全审计拦下来,后来不得不加班三天重新整改证书管理逻辑。
2. 轮询读取 vs 订阅机制的误用
见过不少项目用 while(true) 循环去读 PLC 数据,CPU 占用率直接飙到 40%。这就好比你要知道快递到没到,不应该每分钟去门口看一次,而应该让快递员主动打电话通知你。订阅机制就是这个"主动通知",性能差距能有 5-10 倍。
3. 异常处理与重连策略缺失
工业现场网络环境复杂,设备重启、网络抖动是常态。如果没有完善的重连机制,程序跑着跑着就僵死了。我见过一个项目因为没做断线重连,导致生产线数据丢失 6 小时,损失直接上万。
💡 核心要点提炼
在深入代码之前,咱们先把几个关键概念搞清楚:
🧩 OPC UA 通信的三层架构
- 传输层:处理网络连接、证书验证、加密通道
- 服务层:提供读、写、订阅、浏览等标准服务
- 信息模型层:定义节点结构、数据类型、访问权限
理解这个分层很重要,因为不同层次的问题处理方式完全不同。比如证书问题在传输层解决,数据格式问题在信息模型层处理。
🚀 订阅机制的性能优势
| 对比维度 | 轮询读取 | 订阅机制 |
|---|---|---|
| CPU 占用 | 30-40% | 5-8% |
| 网络流量 | 持续高负载 | 按需推送 |
| 实时性 | 取决于轮询间隔 | 毫秒级变化通知 |
| 适用场景 | 低频查询 | 高频监控 |
这个对比是我在一个电力监控项目中实测的数据(测试环境:500 个监控点,1 秒刷新频率,Intel i5-8400,16GB 内存)。
🔐 证书管理的核心原则
- 绝对不要跳过证书验证(除非真的只是本地测试)
- 必须实现证书自动生成与信任逻辑
- 需要考虑证书过期、更新、吊销的处理流程
🛠️ 解决方案设计
方案一:基础连接与节点读写
先从最简单的场景开始——建立连接并读写节点数据。这里我用的是 OPCFoundation.NetStandard.Opc.Ua 这个官方库,版本 1.4.371 或更高。
csharpusing Opc.Ua;
using Opc.Ua.Client;
using Opc.Ua.Configuration; // 需要引入此命名空间
using System;
using System.Collections.Generic;
using System.Threading.Tasks;
namespace AppOpcUa2026
{
public class OpcUaBasicClient
{
private Session _session;
private ApplicationConfiguration _appConfig;
/// <summary>
/// 初始化并连接到 OPC UA 服务器
/// </summary>
public async Task<bool> ConnectAsync(string endpointUrl)
{
try
{
// 1. 创建应用配置
_appConfig = new ApplicationConfiguration
{
ApplicationName = "MyOpcUaClient",
ApplicationUri = Utils.Format("urn:{0}:MyOpcUaClient", System.Net.Dns.GetHostName()),
ApplicationType = ApplicationType.Client,
SecurityConfiguration = new SecurityConfiguration
{
ApplicationCertificate = new CertificateIdentifier
{
StoreType = "Directory",
StorePath = @"%LocalApplicationData%/OPC Foundation/CertificateStores/MachineDefault",
SubjectName = "CN=MyOpcUaClient, O=MyCompany"
},
// 必填:受信任的对等证书(服务器证书放这里)
TrustedPeerCertificates = new CertificateTrustList
{
StoreType = "Directory",
StorePath = @"%LocalApplicationData%/OPC Foundation/CertificateStores/UA Applications"
},
// 必填:受信任的颁发机构证书 ← 之前漏掉了这个
TrustedIssuerCertificates = new CertificateTrustList
{
StoreType = "Directory",
StorePath = @"%LocalApplicationData%/OPC Foundation/CertificateStores/UA Certificate Authorities"
},
// 必填:被拒绝的证书存放路径
RejectedCertificateStore = new CertificateTrustList
{
StoreType = "Directory",
StorePath = @"%LocalApplicationData%/OPC Foundation/CertificateStores/RejectedCertificates"
},
AutoAcceptUntrustedCertificates = true,
AddAppCertToTrustedStore = true,
RejectSHA1SignedCertificates = false
},
TransportQuotas = new TransportQuotas { OperationTimeout = 15000 },
ClientConfiguration = new ClientConfiguration { DefaultSessionTimeout = 60000 },
TransportConfigurations = new TransportConfigurationCollection(),
TraceConfiguration = new TraceConfiguration()
};
// 2. 验证配置
await _appConfig.Validate(ApplicationType.Client);
// 3. 注册证书验证回调(AutoAccept 模式下需要手动挂钩)
if (_appConfig.SecurityConfiguration.AutoAcceptUntrustedCertificates)
{
_appConfig.CertificateValidator.CertificateValidation += (s, e) =>
{
e.Accept = (e.Error.StatusCode == StatusCodes.BadCertificateUntrusted);
};
}
// 4. 使用 ApplicationInstance 自动处理证书(查找 or 创建自签名证书)
var application = new ApplicationInstance
{
ApplicationName = "MyOpcUaClient",
ApplicationType = ApplicationType.Client,
ApplicationConfiguration = _appConfig
};
await application.CheckApplicationInstanceCertificatesAsync(false, 2048);
var endpoint = CoreClientUtils.SelectEndpoint(
_appConfig,
endpointUrl,
useSecurity: false,
discoverTimeout: 15000
);
var endpointConfiguration = EndpointConfiguration.Create(_appConfig);
var configuredEndpoint = new ConfiguredEndpoint(null, endpoint, endpointConfiguration);
// 6. 创建会话
_session = await Session.Create(
_appConfig,
configuredEndpoint,
false,
"MyOpcUaClient Session",
60000,
new UserIdentity(new AnonymousIdentityToken()),
null
);
Console.WriteLine($"✅ 成功连接到: {endpointUrl}");
return true;
}
catch (Exception ex)
{
Console.WriteLine($"❌ 连接失败: {ex.Message}");
return false;
}
}
/// <summary>
/// 读取单个节点的值
/// </summary>
public T ReadNodeValue<T>(string nodeId)
{
var value = _session.ReadValue(nodeId);
return (T)value.Value;
}
/// <summary>
/// 批量读取多个节点
/// </summary>
public Dictionary<string, object> ReadMultipleNodes(List<string> nodeIds)
{
var result = new Dictionary<string, object>();
var nodesToRead = new ReadValueIdCollection();
foreach (var nodeId in nodeIds)
{
nodesToRead.Add(new ReadValueId
{
NodeId = new NodeId(nodeId),
AttributeId = Attributes.Value
});
}
_session.Read(
null,
0,
TimestampsToReturn.Both,
nodesToRead,
out DataValueCollection values,
out DiagnosticInfoCollection diagnostics
);
for (int i = 0; i < nodeIds.Count; i++)
{
if (StatusCode.IsGood(values[i].StatusCode))
{
result[nodeIds[i]] = values[i].Value;
}
}
return result;
}
/// <summary>
/// 写入节点值
/// </summary>
public bool WriteNodeValue(string nodeId, object value)
{
try
{
var writeValue = new WriteValue
{
NodeId = new NodeId(nodeId),
AttributeId = Attributes.Value,
Value = new DataValue(new Variant(value))
};
_session.Write(
null,
new WriteValueCollection { writeValue },
out StatusCodeCollection results,
out DiagnosticInfoCollection diagnostics
);
return StatusCode.IsGood(results[0]);
}
catch (Exception ex)
{
Console.WriteLine($"写入节点 {nodeId} 失败: {ex.Message}");
return false;
}
}
/// <summary>
/// 断开连接
/// </summary>
public void Disconnect()
{
_session?.Close();
_session?.Dispose();
Console.WriteLine("🔌 已断开连接");
}
}
}
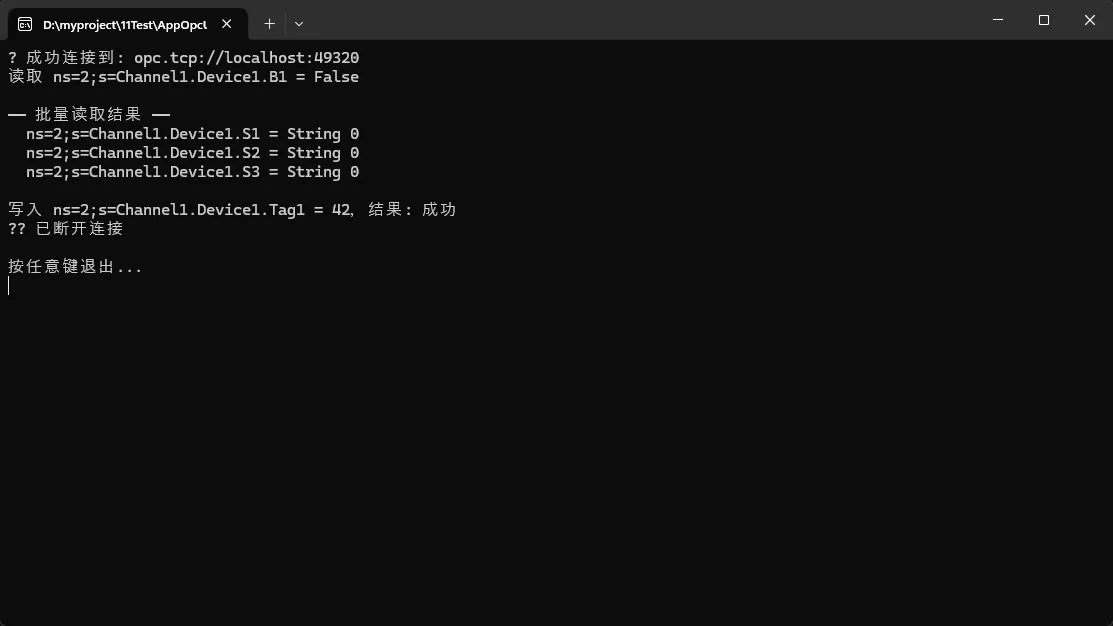
实际应用场景:这套代码我在一个化工厂的数据采集项目中用过,需要读取 150 个温度、压力、流量传感器的数据。用批量读取后,原本 2 秒的采集周期缩短到了 0.3 秒。
踩坑预警:
- 证书路径必须是可写的,否则程序没权限创建证书会直接崩溃
AutoAcceptUntrustedCertificates = true只适合开发环境,生产环境要实现自定义证书验证回调- 批量读取时要注意节点数量限制,有些服务器会限制单次请求的最大节点数(通常是 100-500 个)
🏭 你以为Tkinter只能做玩具界面?
说真的,我第一次接到工业HMI项目的时候,脑子里第一个念头是:用Tkinter?这不是开玩笑吗?
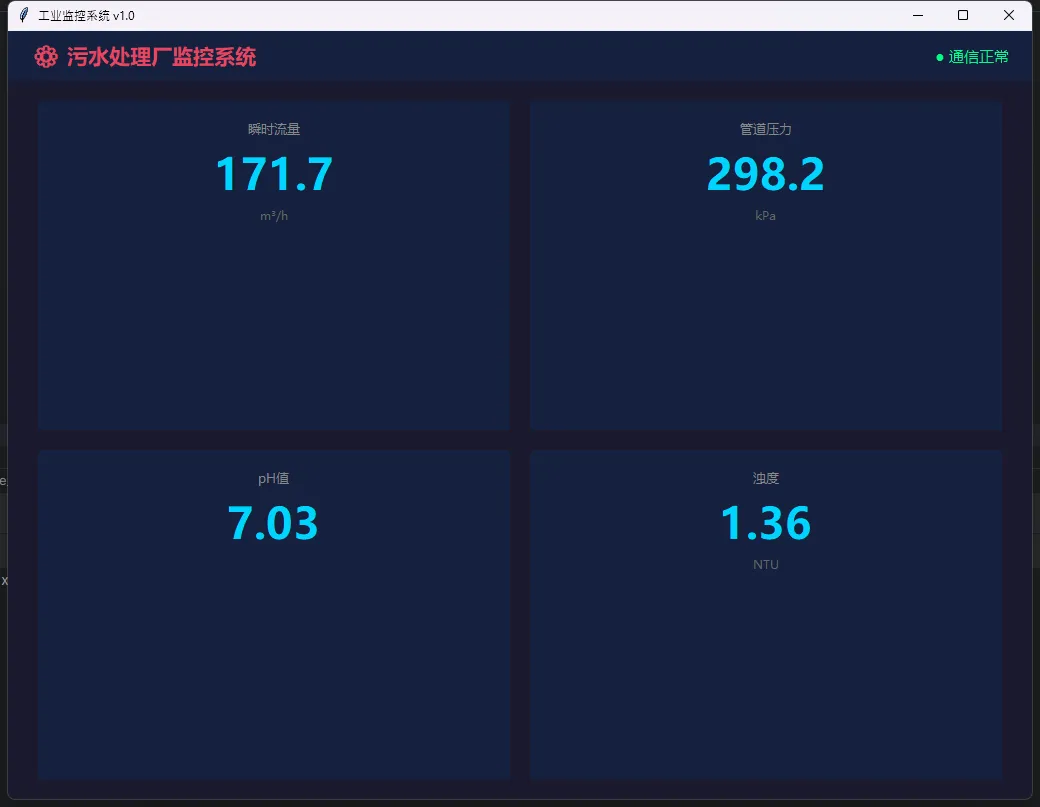
那是一个污水处理厂的监控系统。甲方要求:实时显示12路传感器数据、阀门开关控制、历史曲线回放、报警联动。工期45天,预算有限,不允许引入商业SCADA授权。同事推荐Qt,但部署环境是老旧的Windows XP工控机——4GB内存,CPU还是赛扬双核。Qt的运行时直接把内存吃掉一半。
最后我们用Tkinter搞定了。整个程序启动时间不超过1.2秒,内存占用稳定在80MB以内,连续运行72小时无崩溃。
这篇文章,就是那段经历的技术沉淀。咱们不聊那些Hello World级别的按钮教程——直接上工业级的玩法:Canvas绘制动态仪表盘、串口数据实时刷新、多线程防界面冻结、报警状态机设计。能跑、能用、能上生产。
🔍 问题根源:Tkinter为什么在工业场景里"翻车"
很多人踩坑不是因为Tkinter不行,而是用法根本就错了。
❌ 最常见的三个死法
第一种死法:在主线程里跑串口读取。
python# 这是错的!千万别这样写
while True:
data = serial_port.read(64)
label.config(text=data)
time.sleep(0.1) # 界面直接卡死
主线程被占用,Tkinter的事件循环mainloop()根本没机会执行。界面冻住,鼠标点哪儿都没反应。用户以为程序崩了,直接强制关闭——然后串口没有正确关闭,下次启动报"端口被占用"。恶性循环。
第二种死法:Canvas上直接堆几百个图形对象,从不清理。
工业界面往往有实时曲线,每秒刷新一次,每次create_line()一个新对象。跑一小时之后,Canvas里堆了3600个line对象。内存泄漏,响应越来越慢,最终OOM。
第三种死法:用after()做定时刷新,但忘了处理异常。
串口断线、传感器超时、数据格式异常——任何一个未捕获的异常都会让after()的回调链断掉。界面看起来还在,但数据早就停止更新了。操作员盯着一个"假实时"的界面做决策,后果不堪设想。
💡 核心机制:你必须理解这三件事
1. Tkinter的单线程本质
Tkinter底层是Tcl/Tk,严格单线程。所有UI操作必须在主线程执行。这不是缺陷,是设计。理解这一点,你才能用对多线程方案。
正确姿势是:子线程负责IO,主线程负责渲染,用线程安全的队列传数据。
2. Canvas的对象管理哲学
Canvas里每个图形都是一个"item",有唯一ID。实时更新的正确做法是复用item,而不是删了重建。coords()修改坐标,itemconfig()修改样式,性能差距可以达到10倍以上。
3. after()是你的心跳,不是定时器
after(ms, callback)在Tkinter里是事件驱动的——它把回调注册到事件队列,由mainloop()在合适时机执行。这意味着:如果主线程被阻塞,after()也会延迟。所以绝对不能在回调里做任何耗时操作。
🚀 方案一:多线程架构 + 队列通信
这是整个HMI系统的骨架。先把这个搞对,后面才能谈别的。
pythonimport tkinter as tk
import threading
import queue
import serial
import time
import random # 演示用,实际替换为真实串口
class HMIApp:
def __init__(self, root):
self.root = root
self.root.title("工业监控系统 v1.0")
self.root.geometry("1024x768")
self.root.configure(bg="#1a1a2e")
# 线程安全队列,子线程往里塞数据,主线程来取
self.data_queue = queue.Queue(maxsize=100)
self.running = True
self._build_ui()
self._start_data_thread()
self._schedule_refresh() # 启动心跳
def _build_ui(self):
# 顶部标题栏
title_frame = tk.Frame(self.root, bg="#16213e", height=50)
title_frame.pack(fill=tk.X)
title_frame.pack_propagate(False)
tk.Label(
title_frame, text="⚙ 污水处理厂监控系统",
bg="#16213e", fg="#e94560",
font=("微软雅黑", 16, "bold")
).pack(side=tk.LEFT, padx=20, pady=10)
self.status_label = tk.Label(
title_frame, text="● 通信正常",
bg="#16213e", fg="#00ff88",
font=("微软雅黑", 11)
)
self.status_label.pack(side=tk.RIGHT, padx=20)
# 数据显示区
self.value_labels = {}
data_frame = tk.Frame(self.root, bg="#1a1a2e")
data_frame.pack(fill=tk.BOTH, expand=True, padx=20, pady=10)
params = [
("flow_rate", "瞬时流量", "m³/h"),
("pressure", "管道压力", "kPa"),
("ph_value", "pH值", ""),
("turbidity", "浊度", "NTU"),
]
for i, (key, name, unit) in enumerate(params):
cell = tk.Frame(data_frame, bg="#16213e", relief=tk.FLAT, bd=0)
cell.grid(row=i//2, column=i%2, padx=10, pady=10, sticky="nsew")
data_frame.columnconfigure(i%2, weight=1)
data_frame.rowconfigure(i//2, weight=1)
tk.Label(cell, text=name, bg="#16213e",
fg="#888", font=("微软雅黑", 10)).pack(pady=(15,0))
val_label = tk.Label(cell, text="--",
bg="#16213e", fg="#00d4ff",
font=("微软雅黑", 32, "bold"))
val_label.pack()
tk.Label(cell, text=unit, bg="#16213e",
fg="#666", font=("微软雅黑", 9)).pack(pady=(0,15))
self.value_labels[key] = val_label
def _data_worker(self):
"""子线程:模拟串口读取(实际项目替换为serial.Serial)"""
while self.running:
try:
# 模拟数据,实际:data = ser.read(64); parsed = parse_modbus(data)
data = {
"flow_rate": round(random.uniform(120, 180), 1),
"pressure": round(random.uniform(280, 320), 1),
"ph_value": round(random.uniform(6.8, 7.4), 2),
"turbidity": round(random.uniform(0.5, 2.0), 2),
}
# 队列满了就丢弃旧数据,不阻塞子线程
if self.data_queue.full():
try:
self.data_queue.get_nowait()
except queue.Empty:
pass
self.data_queue.put(data)
except Exception as e:
# 通信异常:推送一个错误标记
self.data_queue.put({"__error__": str(e)})
time.sleep(0.5)
def _start_data_thread(self):
t = threading.Thread(target=self._data_worker, daemon=True)
t.start()
def _schedule_refresh(self):
"""主线程心跳:每500ms从队列取数据刷新UI"""
try:
while not self.data_queue.empty():
data = self.data_queue.get_nowait()
if "__error__" in data:
self.status_label.config(text="● 通信异常", fg="#ff4444")
continue
self.status_label.config(text="● 通信正常", fg="#00ff88")
for key, label in self.value_labels.items():
if key in data:
label.config(text=str(data[key]))
except Exception as e:
print(f"UI刷新异常: {e}") # 生产环境换成日志
finally:
# 无论如何都要续命,否则心跳停了
if self.running:
self.root.after(500, self._schedule_refresh)
def on_close(self):
self.running = False
self.root.destroy()
if __name__ == "__main__":
root = tk.Tk()
app = HMIApp(root)
root.protocol("WM_DELETE_WINDOW", app.on_close)
root.mainloop()
踩坑预警:daemon=True是关键。没有这个,主窗口关闭后子线程还在跑,进程无法退出,任务管理器里会看到僵尸Python进程。