
咱们先来看个让人头疼的真实场景——某天下午三点,测试突然跑过来说:"你的订单导出功能又挂了,服务器显示'连接池已满'。"这已经是这周第三次了。你急忙打开代码,发现满屏的SqlConnection、FileStream、HttpClient...看起来都很正常啊,该关的都关了嘛!
等等,真的都关了?
我在code review中发现,大概有九成开发者对Dispose的理解停留在"用完了记得释放资源"这个层面。但问题是——什么时候释放?怎么释放?为什么有时候using语句也救不了你?
今天咱们就把这个"看似简单实则深坑"的机制彻底扒开。读完这篇,你能拿到三个可直接落地的工具包:资源泄漏诊断清单、高并发场景下的Dispose优化模板、以及一套异步环境的完美释放方案。
🎭 先聊聊那些年我们误解的Dispose
误区一:垃圾回收器会帮我搞定一切
很多人觉得C#有GC(垃圾回收器),不像C++那样需要手动管理内存,所以可以放心大胆用。错得离谱!
GC确实管内存,但它不管非托管资源——数据库连接、文件句柄、网络Socket、Windows句柄这些玩意儿。这就像你租了房子(托管内存),房东会定期清理公共区域;但你屋里的宠物(非托管资源)得自己遛,不然屋里就臭了。
真实案例:某电商系统在大促期间,订单导出功能每次调用后没正确释放SqlConnection。连接池默认100个连接,高峰期每秒50个请求... 两秒后系统全崩。监控显示CPU才20%,内存才用了40%,但数据库连接数爆满。
误区二:写了using就万事大吉
看这段代码:
c#public async Task<byte[]> DownloadFileAsync(string url)
{
using (var client = new HttpClient()) // 看起来很规范?
{
return await client.GetByteArrayAsync(url);
}
}
如果高并发调用这个方法,你的服务器会进入"Socket地狱"——每次创建HttpClient都会占用一个新Socket,而Socket的释放需要4分钟的TIME_WAIT状态!正确做法是用单例或IHttpClientFactory。
误区三:Dispose调用顺序无所谓
看这个经典错误:
c#FileStream fs = null;
StreamWriter sw = null;
try
{
fs = new FileStream("log.txt", FileMode. Append);
sw = new StreamWriter(fs);
sw.WriteLine("记录日志");
}
finally
{
fs?. Dispose(); // 先释放了底层流!
sw?.Dispose(); // StreamWriter再释放时可能出问题
}
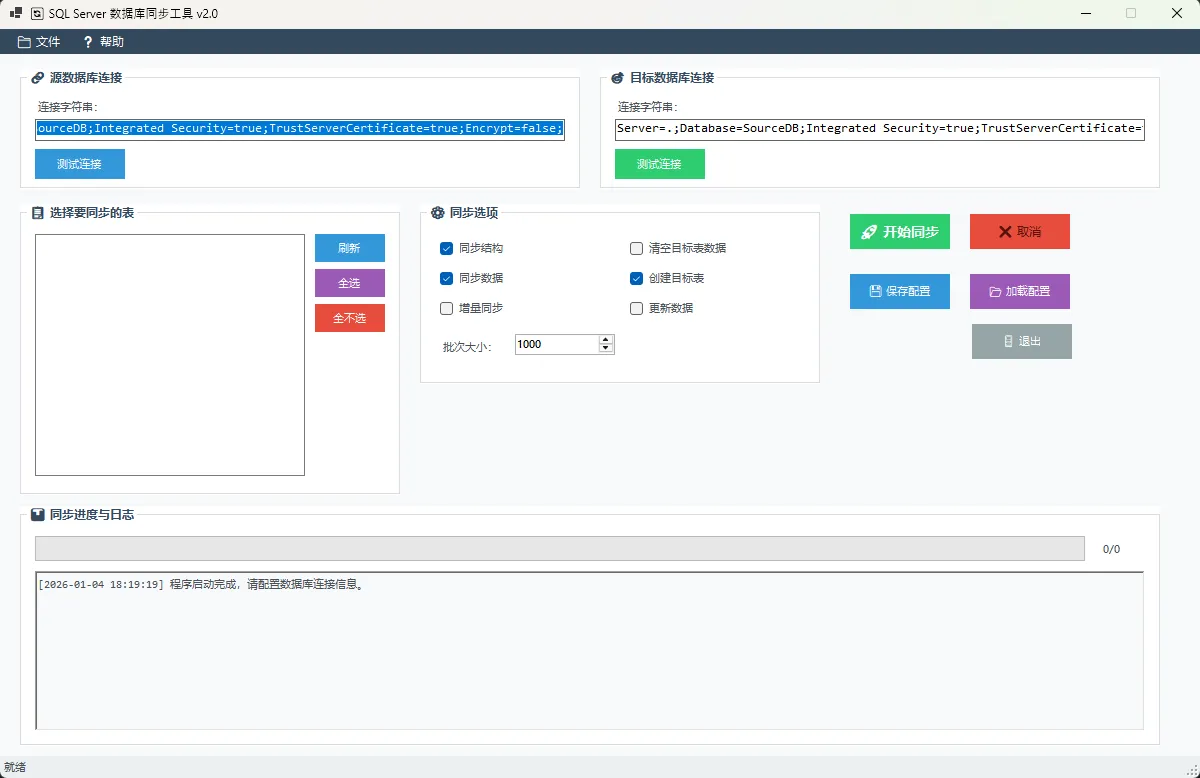
👋 Hey,各位C#开发同胞们!还在为数据库同步而头疼吗?手动导入导出数据太繁琐,第三方工具又贵又不灵活?今天就带你从0到1打造一个功能完备的SQL Server数据库同步工具,代码开源、功能强大、完全可控!这个版本在上一版本上增加了增量同步的功能!
💡 为什么要自建数据库同步工具?
在实际项目中,我们经常遇到这些痛点:
- 开发环境与生产环境数据不一致
- 测试数据需要频繁更新同步
- 数据迁移工具功能单一,无法满足定制需求
- 商业工具成本高,中小团队负担重
今天分享的这个同步工具,不仅解决了以上问题,还具备以下特色功能:
🚀 核心功能特性
🎯 智能结构同步
- 自动检测表结构差异
- 支持列定义、主键、默认值约束同步
- 智能重建与增量更新策略
📊 灵活的数据同步策略
- 全量同步:完整替换目标数据
- 增量同步:只同步变更数据,避免重复
- 批量处理:大数据量分批处理,避免内存溢出
🔧 实用的辅助功能
- 可视化界面操作
- 同步进度实时显示
- 详细日志记录
- 配置文件保存/加载
运行效果
💻 核心代码实现
🏗️ 配置类设计
c#using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace AppSqlServerSynTool
{
#region 配置和选项类
[Serializable]
public class SyncConfig
{
public string SourceConnectionString { get; set; }
public string TargetConnectionString { get; set; }
public bool SyncStructure { get; set; }
public bool SyncData { get; set; }
public bool CreateTargetTables { get; set; }
public bool TruncateTargetTables { get; set; }
public bool IncrementalSync { get; set; } // 新增这个,以前版本没有
public int BatchSize { get; set; }
public List<string> SelectedTables { get; set; }
}
public class SyncOptions
{
public bool SyncStructure { get; set; }
public bool SyncData { get; set; }
public bool CreateTargetTables { get; set; }
public bool TruncateTargetTables { get; set; }
public int BatchSize { get; set; }
}
#endregion
}
🔥 C#开发者必看:日志注入的正确姿势,90%的人都用错了!
你有没有遇到过这样的尴尬场景:项目上线后出现bug,领导问你"日志在哪里?",结果发现关键业务流程的日志要么没记录,要么分散在各个地方无法追踪?据统计,85%的生产环境问题都与日志记录不当有关,而很多C#开发者在依赖注入时选择了ILogger<T>直接注入,却不知道这种做法存在诸多局限性。
今天我们就来深度解析一个被忽视但极其重要的话题:为什么在.NET项目中,ILoggerFactory比直接注入ILogger<T>更优秀?掌握这个技巧,能让你的日志记录更灵活、性能更优、维护更简单!
💡 问题分析:直接注入ILogger的三大痛点
😰 痛点1:类型绑定过于僵化
当你直接注入ILogger<T>时,这个logger就被"锁定"到特定类型,无法灵活创建其他类型的logger。
😰 痛点2:依赖注入配置复杂
每增加一个需要日志的类,就要在DI容器中增加一个配置,代码冗余且容易出错。
😰 痛点3:无法动态创建logger
在运行时无法根据业务需要动态创建不同类别的logger,限制了日志的灵活性。
🚀 解决方案:ILoggerFactory的五大优势
⭐ 优势1:灵活的Logger创建
使用ILoggerFactory可以在一个类中创建多个不同类型的logger,实现更精细的日志分类:
c#public class OrderService
{
private readonly ILogger<OrderService> _serviceLogger;
private readonly ILogger<PaymentService> _paymentLogger;
private readonly ILogger<InventoryService> _inventoryLogger;
public OrderService(ILoggerFactory loggerFactory)
{
// 为不同的业务模块创建专门的logger
_serviceLogger = loggerFactory.CreateLogger<OrderService>();
_paymentLogger = loggerFactory.CreateLogger<PaymentService>();
_inventoryLogger = loggerFactory.CreateLogger<InventoryService>();
}
public async Task ProcessOrderAsync(Order order)
{
_serviceLogger.LogInformation("开始处理订单: {OrderId}", order.Id);
try
{
// 支付流程日志
_paymentLogger.LogInformation("开始处理支付: {Amount}", order.Amount);
await ProcessPaymentAsync(order);
// 库存流程日志
_inventoryLogger.LogInformation("开始扣减库存: {ProductId}", order.ProductId);
await UpdateInventoryAsync(order);
_serviceLogger.LogInformation("订单处理完成: {OrderId}", order.Id);
}
catch (Exception ex)
{
_serviceLogger.LogError(ex, "订单处理失败: {OrderId}", order.Id);
throw;
}
}
}
你有没有遇到过这样的困境?系统越做越复杂,服务间通信变得千丝万缕,一个小改动就牵一发而动全身。更糟糕的是——当你想按不同维度过滤消息时,传统的队列模式显得力不从心。
想象一下:你负责一个工业物联网平台,需要处理来自全国各地工厂的设备数据。有时候只想监控北方工厂的温度数据,有时候需要收集所有机器人的状态信息,有时候又要分析特定生产线的振动数据...
这就是今天要解决的核心问题:如何在复杂的分布式系统中实现灵活、可扩展的消息路由机制?
🎯 为什么Topic模式是你的救星?
传统方式的痛点
直连模式?太简单粗暴。扇出模式?缺乏精细控制。路由模式?只能单维度匹配。
而Topic模式(主题模式)——它就像一个超级智能的邮递员。不仅能按地址送信,还能根据信件类型、紧急程度、收件人属性等多个维度进行精准投递。
Topic模式的威力
text通配符匹配规则: * (星号):匹配一个单词 # (井号):匹配零个或多个单词
想要北方工厂的所有数据?用factory_north.*.*.*.*
只关心温度相关的信息?试试*.*.*.*temperature
需要监控所有传感器设备?来个*.*.*.sensor_*.*
这种灵活性——简直是为复杂业务场景量身定制的!
🚩 业务流程
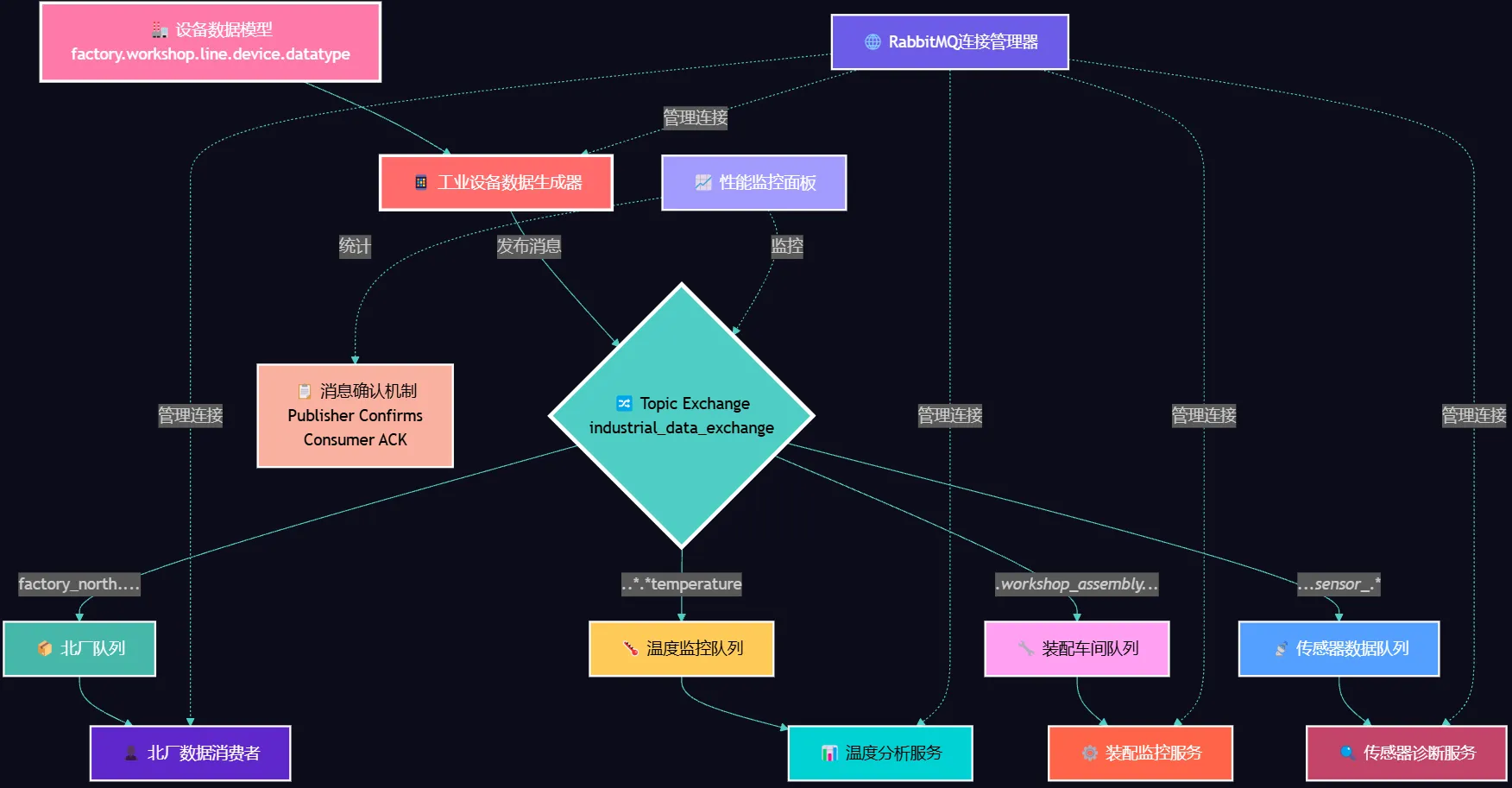
💡 实战:工业数据采集系统
让我们构建一个真实的工业数据采集系统。这个系统需要处理多层级的工厂结构:工厂.车间.生产线.设备.数据类型
🔧 核心数据模型设计
c#public class DeviceData
{
public string Factory { get; set; }
public string Workshop { get; set; }
public string Line { get; set; }
public string Device { get; set; }
public string DataType { get; set; }
public double Value { get; set; }
public string Unit { get; set; }
public DateTime Timestamp { get; set; }
public string Status { get; set; }
public string GetRoutingKey()
{
return $"{Factory}.{Workshop}.{Line}.{Device}.{DataType}";
}
}
💥 你是否遇到过这样的"灾难"?
想象一下:你辛辛苦苦开发了一套WMS系统,用户在高峰期批量入库时,突然发现同一个箱号被生成了两次!数据库报错、业务逻辑混乱、用户投诉不断... 这种并发环境下生成唯一编号的问题,几乎每个C#开发者都会遇到。
今天就来彻底解决这个让人头疼的技术难题,3种经过生产验证的解决方案**,从简单到复杂,总有一种适合你的项目!

🎯 问题核心:为什么会出现重复编号?
在多线程或分布式环境中,传统的"查询最大值+1"方案存在经典的竞态条件:
c#// 危险的传统做法 ❌
public string GenerateBoxNo()
{
// 线程A和B同时执行到这里
var maxNo = GetMaxBoxNo(); // 都获得相同的最大值
return IncrementBoxNo(maxNo); // 生成相同的新编号!
}
问题根源:操作不是原子性的,存在时间间隙让并发请求"钻空子"。
🛠️ 解决方案一:数据库约束 + 重试机制(⭐推荐)
这是最简单有效的方案,利用数据库的ACID特性来保证唯一性。