
在计算机视觉和图像处理领域,OpenCV无疑是最受欢迎的开源库之一。作为一名Windows平台的Python开发者,你是否曾为OpenCV的安装和配置而头疼?本文将从OpenCV的历史背景讲起,深入解析其应用场景,并提供详细的Python环境安装教程。无论你是初学者还是有经验的开发者,这篇文章都将帮你彻底掌握OpenCV在Python中的使用,解决安装过程中的各种疑难杂症,让你的计算机视觉项目开发更加顺畅。
🔍 OpenCV历史与核心价值
📚 OpenCV的发展历程
OpenCV(Open Source Computer Vision Library)诞生于1999年,由Intel公司发起。这个开源计算机视觉库经历了近25年的发展,已经成为计算机视觉领域的标准工具库。
发展里程碑:
- 1999年:Intel启动OpenCV项目
- 2006年:发布OpenCV 1.0版本
- 2009年:OpenCV 2.0引入C++接口
- 2015年:OpenCV 3.0重大架构升级
- 2018年:OpenCV 4.0发布,性能大幅提升
- 2024年:OpenCV 4.9持续优化
🌟 为什么选择OpenCV?
OpenCV之所以在Python开发者中如此受欢迎,主要有以下几个原因:
- 跨平台兼容性:完美支持Windows、Linux、macOS
- 丰富的功能模块:图像处理、特征检测、机器学习一应俱全
- 优异的性能表现:底层C++实现,执行效率极高
- 活跃的社区支持:海量教程和解决方案
- 商业友好许可:BSD许可证,可用于商业项目
🚀 OpenCV核心应用场景解析
🎮 游戏与娱乐行业
实际应用案例:
- 手势识别游戏控制:通过摄像头捕获手势,控制游戏角色
- AR滤镜效果:实时面部检测和特效叠加
- 体感游戏开发:动作捕获和姿态识别
🏭 工业自动化与质检
核心应用场景:
- 产品缺陷检测:自动识别生产线上的不良品
- 尺寸测量:精确测量工件尺寸
- OCR文字识别:自动读取产品标签和序列号
- 机器人视觉导航:工业机器人的视觉定位
🚗 智能交通系统
典型应用:
- 车牌识别系统:停车场和交通监控
- 交通流量统计:实时车辆计数和流量分析
- 驾驶员疲劳检测:通过面部表情判断驾驶状态
🏥 医疗影像分析
医疗场景应用:
- X光片自动分析:辅助医生诊断
- 皮肤病变检测:皮肤癌筛查
- 视网膜病变识别:糖尿病视网膜病变检测
🔧 Python环境下OpenCV安装详解
💻 环境准备与检查
在开始安装之前,确保你的开发环境满足以下要求:
系统要求:
- Windows 10/11(推荐64位系统)
- Python 3.7+(建议使用Python 3.9-3.11)
- 充足的磁盘空间(至少500MB)
检查Python版本:
bashpython --version
# 或者
python -V
检查pip版本:
bashpip --version
🌐 方法一:pip安装(一般不会直接这样安装)
这是最简单、最常用的安装方法,适合大多数开发场景。
基础安装命令:
bash# 安装主要的OpenCV包
pip install opencv-python
# 安装包含额外功能的完整版本
pip install opencv-contrib-python
指定版本安装:
bash# 安装特定版本
pip install opencv-python==4.8.1.78
# 安装最新稳定版
pip install --upgrade opencv-python
使用国内镜像源加速:
bash# 使用清华源
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 使用阿里源
pip install opencv-python -i https://mirrors.aliyun.com/pypi/simple/
🎯 你是不是也遇到过这个问题?
做数据可视化的时候,折线图是用得最多的图表类型。但默认的折线图往往太"硬"——直来直去的折线放在展示页面上,总感觉少了点什么。客户看了说"能不能做得好看一点",领导看了说"这个曲线能不能平滑一些",自己看了也觉得差点意思。
更让人头疼的是,LiveCharts 2 的文档虽然有,但关于平滑曲线、阶梯线、虚线这几个进阶配置,说得相当简略。很多开发者翻了半天文档,要么找不到对应的属性,要么配置了没效果,要么效果出来了但不知道怎么组合使用。
读完本文,你将掌握三个可以直接落地的技能:
- 平滑曲线的插值算法原理与
GeometryFill、LineSmoothness的正确配置方式 - 阶梯线在库存、状态变化等离散数据场景下的应用与实现
- 虚线样式的自定义配置,以及多种线型组合使用的最佳实践
测试环境:.NET 6 + LiveCharts2 0.19.x + WinForms,代码经过本地运行验证。
🔍 问题深度剖析:为什么默认折线图"不够用"
折线图的视觉表达局限
默认折线图用的是直线段连接数据点,这在数学上没问题,但在视觉传达上会带来两个问题。
第一,数据波动被放大。直线连接会让相邻数据点之间的变化显得很"突兀",尤其是传感器采集的连续数据,本来是平滑变化的物理量,折线图画出来却像锯齿一样,反而干扰了读者对趋势的判断。
第二,无法区分数据语义。有些数据是连续变化的(比如温度、压力),有些数据是离散跳变的(比如设备状态、库存数量)。用同一种直线去表达这两类数据,在语义上是有歧义的。阶梯线正是为后者设计的——它明确地告诉读者"这个值在某个时间点发生了突变,而不是线性过渡"。
常见的错误做法
很多开发者在遇到这个问题时,会尝试手动插值——在原始数据点之间插入大量中间点来"模拟"平滑效果。这个做法有几个明显的坑:
- 数据量膨胀,绑定到图表后渲染压力成倍增加
- 插值精度难以控制,曲线可能在极值附近出现"过冲"
- 维护成本高,数据更新时需要重新计算所有插值点
LiveCharts 2 其实内置了完整的曲线插值支持,根本不需要手动处理。问题只是很多人不知道去哪里找、怎么配置。
💡 核心要点提炼
LineSeries 的关键属性
在深入代码之前,先把 LineSeries<T> 里几个最重要的属性梳理清楚:
| 属性 | 类型 | 作用 |
|---|---|---|
LineSmoothness | double(0~1) | 控制曲线平滑程度,0 为直线,1 为最大平滑 |
GeometrySize | double | 数据点圆点的大小,设为 0 可隐藏 |
GeometryFill | SolidColorPaint | 数据点填充色 |
GeometryStroke | SolidColorPaint | 数据点边框色 |
Stroke | IPaint<SkiaSharpDrawingContext> | 折线描边,虚线也在这里配置 |
Fill | IPaint<SkiaSharpDrawingContext> | 折线下方区域填充 |
StepLineSeries<T> 是独立的系列类型,用于阶梯线,属性结构与 LineSeries<T> 基本一致。
🚀 解决方案一:平滑曲线配置
应用场景
适合展示连续变化的物理量,如温度曲线、心率监测、股价走势、传感器数据实时展示等。平滑曲线能有效降低视觉噪声,让趋势更直观。
完整代码示例
csharpusing LiveChartsCore;
using LiveChartsCore.SkiaSharpView;
using LiveChartsCore.SkiaSharpView.Painting;
using SkiaSharp;
namespace AppLiveChart13
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
InitChart();
}
private void InitChart()
{
// 模拟温度传感器数据(24小时)
var temperatureData = new double[]
{
18.2, 17.8, 17.1, 16.9, 16.5, 17.0,
18.5, 20.3, 22.1, 24.6, 26.2, 27.8,
28.5, 29.1, 28.7, 27.9, 26.5, 24.8,
23.1, 21.6, 20.4, 19.7, 19.1, 18.6
};
var smoothSeries = new LineSeries<double>
{
Values = temperatureData,
Name = "室内温度(°C)",
// 核心配置:平滑度设为 0.8,接近最大平滑
// 取值范围 0~1,0 = 折线,1 = 最大曲率
LineSmoothness = 0.8,
// 折线描边:蓝色,2px 宽
Stroke = new SolidColorPaint(SKColors.DodgerBlue, 2),
// 折线下方填充:半透明蓝色
Fill = new SolidColorPaint(SKColors.DodgerBlue.WithAlpha(40)),
// 数据点配置
GeometrySize = 8,
GeometryFill = new SolidColorPaint(SKColors.White),
GeometryStroke = new SolidColorPaint(SKColors.DodgerBlue, 2),
};
// 绑定到 CartesianChart 控件
cartesianChart1.Series = new ISeries[] { smoothSeries };
// X 轴配置(显示小时标签)
cartesianChart1.XAxes = new[]
{
new Axis
{
Name = "时间(小时)",
Labels = Enumerable.Range(0, 24)
.Select(h => $"{h}:00")
.ToArray(),
LabelsRotation = 45
}
};
cartesianChart1.YAxes = new[]
{
new Axis { Name = "温度(°C)" }
};
}
}
}
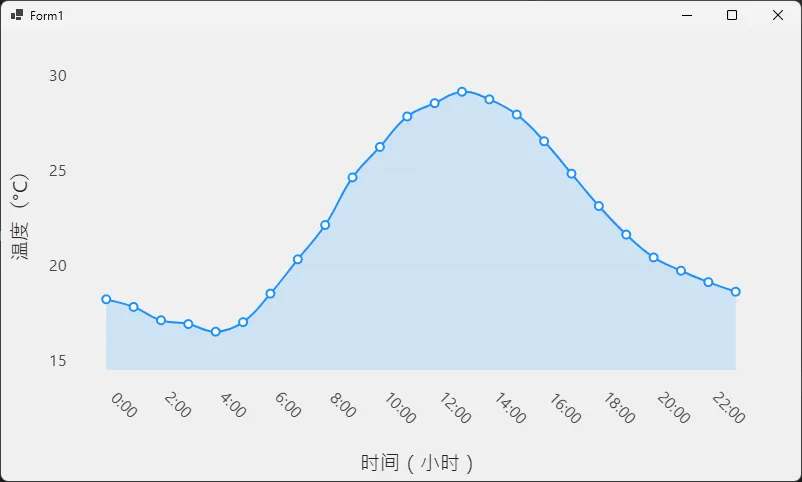
平滑度参数的选择经验
LineSmoothness 的取值不是越大越好。在我的项目实践中,0.5~0.7 是大多数场景下视觉效果最自然的区间。设置为 1 的时候,曲线在极值点附近可能会出现轻微的"过冲"——也就是曲线会短暂超出实际数据点的值域范围,在某些业务场景下(比如金融数据)这是不可接受的,需要特别注意。
做过一个温控系统的维护工作,接手的时候差点没绷住——Form1.cs 足足 2300 行,btnStart_Click、btnStop_Click、btnExport_Click 密密麻麻,每个按钮里头都塞着一坨业务逻辑,改一个功能要翻半天,生怕动了哪根线把别的东西带崩。
这种代码,不是写出来的,是"堆"出来的。
后来我把这个项目用 [RelayCommand] 重构了一遍,Form 从 2300 行缩到不到 300 行,测试覆盖率从零提到 74%。今天就把这套东西拆开讲清楚,从原理到工业落地,一次说透。
🤔 事件驱动到底哪里"坏了"
先说清楚问题在哪。传统 WinForms 的写法,大概长这个样子:
csharpprivate void btnStart_Click(object sender, EventArgs e)
{
if (!_isRunning)
{
_timer.Interval = (int)nudInterval.Value;
_timer.Start();
_isRunning = true;
btnStart.Enabled = false;
btnStop.Enabled = true;
lblStatus.Text = "采集中...";
}
}
看起来没什么问题对吧?但麻烦就藏在这几行里。业务状态(_isRunning)、UI 操作(btnStart.Enabled)、服务调用(_timer.Start())全部揉在一起,Form 既是界面,又是控制器,还是状态机。
想单元测试?没法测,因为逻辑依赖 UI 控件。想复用逻辑?没法复用,因为它跟 Form 死死绑着。想换个界面框架?——那就重写吧。
这不是某个人的问题,是这种写法天然的局限。
💡 命令模式:把"做什么"和"谁来触发"拆开
ICommand 接口其实挺老了,WPF 时代就有,但 WinForms 开发者用得少。它的核心思路就一句话:把操作封装成对象,让 UI 只负责触发,不负责实现。
按钮点击 → Execute(command) → ViewModel 里的方法 ↑ CanExecute() 决定按钮灰不灰
UI 不再需要知道"点了之后干什么",只需要知道"有没有权限点"。这个权限——也就是 CanExecute——由 ViewModel 自己管,UI 监听结果就好。
干净。彻底。
🔧 [RelayCommand] 是怎么工作的
CommunityToolkit.Mvvm 把这套东西做到了极致简洁。你只需要在方法上贴一个特性:
csharp[RelayCommand(CanExecute = nameof(CanStartSampling))]
private void StartSampling()
{
_timer.Interval = Interval;
_timer.Start();
IsRunning = true;
}
private bool CanStartSampling() => !IsRunning;
编译器(Source Generator)在后台帮你生成了这些:
csharp// 这段代码你不用写,编译器自动生成在 .g.cs 里
private RelayCommand? _startSamplingCommand;
public IRelayCommand StartSamplingCommand =>
_startSamplingCommand ??=
new RelayCommand(StartSampling, CanStartSampling);
零样板代码。不是"少写一点",是一个字都不用写。
更妙的是 [NotifyCanExecuteChangedFor],把它贴在属性上:
csharp[ObservableProperty]
[NotifyCanExecuteChangedFor(nameof(StartSamplingCommand))]
[NotifyCanExecuteChangedFor(nameof(StopSamplingCommand))]
private bool _isRunning;
IsRunning 一变,两个命令的 CanExecuteChanged 自动触发,按钮的 Enabled 状态跟着联动——整个过程,Form 里一行判断代码都不需要。
👨💻 先看一下效果
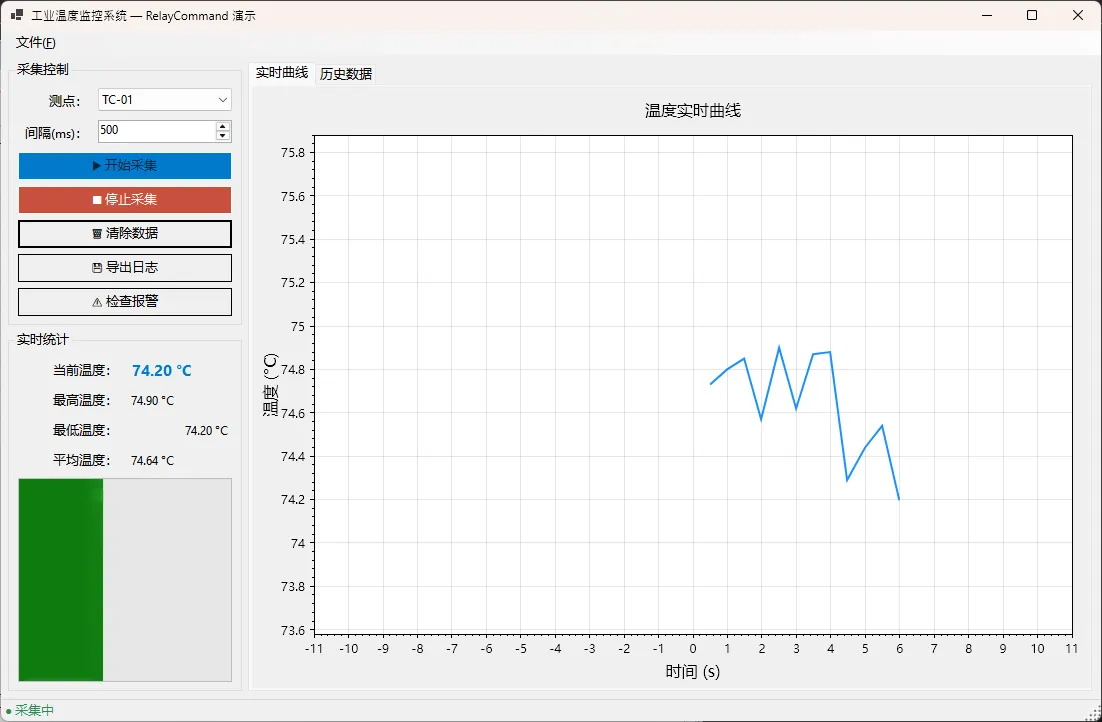
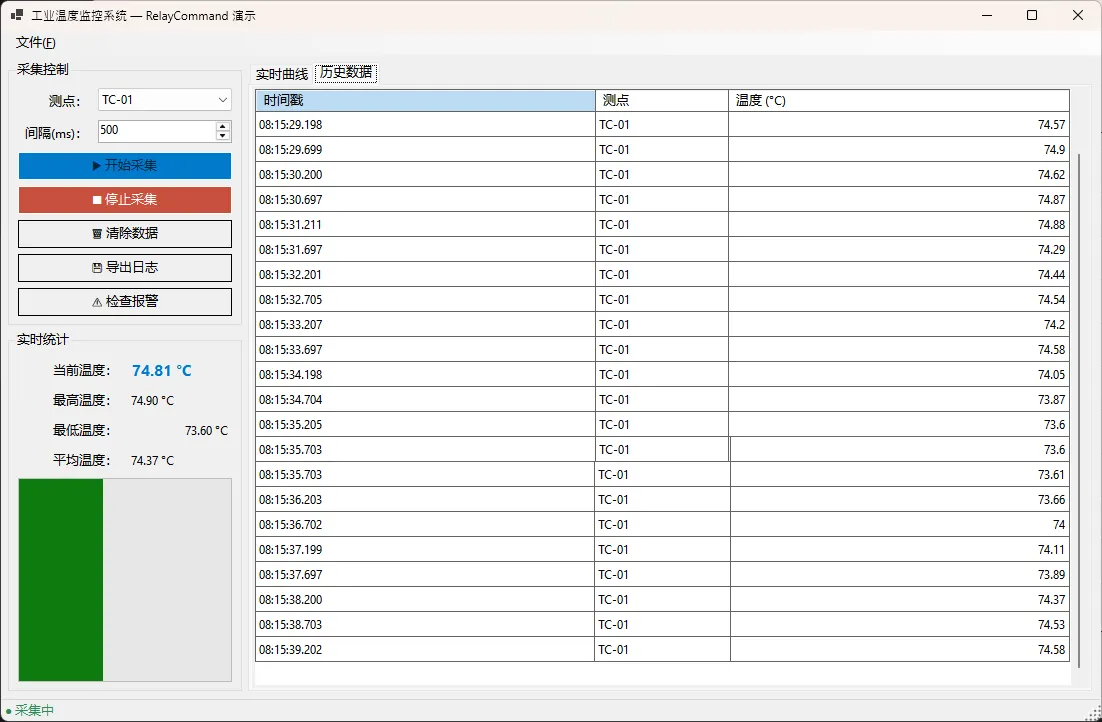
🏭 工业场景落地:温度监控面板
光说概念没用,来看实际项目怎么组织。我用的是一个工业温度采集面板,场景包括:周期采样、停止、清除历史、导出 CSV 日志、报警检查。
ViewModel 骨架
csharppublic sealed partial class SensorViewModel : ObservableObject
{
private readonly SensorService _sensor = new();
private readonly System.Windows.Forms.Timer _timer = new();
[ObservableProperty]
[NotifyPropertyChangedFor(nameof(StatusText))]
[NotifyCanExecuteChangedFor(nameof(StartSamplingCommand))]
[NotifyCanExecuteChangedFor(nameof(StopSamplingCommand))]
private bool _isRunning;
[ObservableProperty] private double _currentTemp;
[ObservableProperty] private double _maxTemp;
[ObservableProperty] private double _minTemp = 999;
[ObservableProperty] private double _avgTemp;
public string StatusText => IsRunning ? "● 采集中" : "○ 已停止";
public ObservableCollection<SensorReading> Readings { get; } = [];
}
你有没有遇到过这种情况:
从 PLC 读回来一个温度值,明明是 "85.6",存的是字符串。你想把它和报警阈值 90.0 比大小,结果编译器直接给你报红——"无法将 string 隐式转换为 double"。
你改了半天,改出了一个新问题:数值截断了,85.6 变成了 85,精度没了。
这种情况,不是你代码写得差,是你还没搞清楚 C# 的类型转换规则。今天这篇,把三种转换方式讲透,工厂场景全覆盖。
📌 上节回顾
「上一节我们学了 const 和 enum,掌握了用常量锁定报警阈值、用枚举定义设备状态的方法。
今天在这个基础上,我们进一步学习如何在不同数据类型之间安全地"搬运"数值——类型转换。」
💡 核心知识讲解
为什么工厂程序特别需要类型转换?
工业现场的数据来源极其复杂。
PLC 给你的是 int,数据库存的是 string,界面控件绑定的是 double,通信协议传来的是 byte[]。
这些数据要在一起"工作",就必须先统一"语言"。类型转换,就是让不同格式的数据能互相理解的翻译官。
C# 里的类型转换,主要分三种:隐式转换、显式转换(强制转换)、Convert 类转换。
第一种:隐式转换(系统自动帮你转)
隐式转换(Implicit Conversion):不需要写任何额外代码,编译器自动完成,且100%安全,不会丢失数据。
类比工厂:就像把一个 500ml 的量杯里的水倒进 1000ml 的量杯,绝对装得下,不会溢出,不用你操心。
什么情况下可以隐式转换? 简单记:小范围 → 大范围,整数 → 浮点数。
| 从(小) | 到(大) | 是否安全 |
|---|---|---|
int | long | ✅ 安全 |
int | double | ✅ 安全 |
float | double | ✅ 安全 |
byte | int | ✅ 安全 |
举个工厂例子:设备编号是 int,统计报表需要 long 类型存储,直接赋值就行,编译器不报错。
第二种:显式转换(你亲自动手,风险自负)
显式转换(Explicit Conversion),也叫强制转换(Cast),需要你用括号明确告诉编译器"我知道风险,我要转"。
类比工厂:把 1000ml 量杯的水倒进 500ml 量杯——可以倒,但超出的部分会溢出丢失。
语法格式:(目标类型)变量名
「⚠️ 警示:显式转换可能造成数据精度损失或溢出,使用前必须确认数值范围。」
比如把 double 类型的温度值 85.6 强制转成 int,结果是 85,小数点后直接截断,不是四舍五入。
这在工业场景里很危险——报警阈值如果精度丢失,可能导致设备该停不停。
设备温度报警阈值,你是直接在代码里写的 85.0 吗?
三个月后,领导说"把报警温度改成 90 度"。你翻遍整个项目,发现 85.0 出现了 17 次——哪些是温度?哪些是别的参数?你已经分不清了。
改了 12 处,漏了 5 处,上线后某台注塑机没触发报警,差点出了事故。
这不是假设,这是很多工厂项目的真实故事。今天学完 const 和 enum,这种问题你以后不会再有。
📌 上节回顾
上一节我们学了变量与数据类型,掌握了用 int、double、string、bool 存储不同类型数据的方法。
今天在这个基础上,我们进一步学习不会变的数据和有限选项的数据该怎么定义。
💡 核心知识讲解
先搞清楚:什么是"不该变的数据"?
在工厂项目里,有些数值是写死在规格书里的——设备额定电压是 380V,圆周率是 3.14159,一条产线最多 64 个工位。
这些数据从项目立项到退役,永远不会变。如果你把它们写成普通变量,代码运行时理论上可以被修改,这是个隐患。
const(常量)就是给这类数据用的。 它告诉编译器:这个值定死了,谁都别想改。
// 错误方式:用变量存不变的数据 double voltage = 380.0; // 万一哪里不小心 voltage = 0,完蛋 // 正确方式:用常量 const double RatedVoltage = 380.0; // 改都改不了
「const 的本质:编译时就把值固定下来,运行时无法修改。」
const 的使用规则
| 特性 | 说明 |
|---|---|
| 声明时必须赋值 | const int Max = 100; ✅ |
| 不能运行时赋值 | const int Max = GetMax(); ❌ |
| 支持的类型 | 数字、字符串、bool、char |
| 作用范围 | 类内、方法内均可用 |
有一点要记住:const 只能存编译时就能确定的值。比如你不能把一个从数据库读出来的值赋给 const,因为那个值要运行时才知道。
再说"有限选项":什么时候用 enum?
工厂里设备的运行状态,就那么几种:停机、运行、报警、维护。
如果你用数字表示,0=停机,1=运行,2=报警,3=维护,代码里就会出现:
csharpif (deviceStatus == 2) // 2 是什么?谁记得住?
三个月后,你自己都不记得 2 代表什么。
enum(枚举)就是把这些有限选项起个名字,统一管理。 用了枚举之后:
csharpif (deviceStatus == DeviceStatus.Alarm) // 一眼就懂
「枚举的本质:给一组有限的选项,贴上人能读懂的标签。」
enum 的底层是整数
枚举在内存里存的其实是整数,默认从 0 开始自动编号。
csharpenum DeviceStatus
{
Stopped = 0, // 停机
Running = 1, // 运行
Alarm = 2, // 报警
Maintain = 3 // 维护
}
你也可以手动指定数值,比如对接 PLC(可编程逻辑控制器,工厂里控制设备的"大脑")时,PLC 返回的状态码是 10、20、30,你可以直接写:
csharpenum PlcStatus
{
Stopped = 10,
Running = 20,
Fault = 30
}
这样枚举值和 PLC 的状态码一一对应,读取数据时直接强制转换,省去了大量的 if-else 判断。
const vs enum 怎么选?
| 场景 | 推荐用法 |
|---|---|
| 单个固定数值(如报警阈值) | const |
| 一组互斥的状态/类型 | enum |
| 多个相关常量打包管理 | enum |
| 需要和 PLC 状态码对应 | enum(手动赋值) |
「记住这个口诀:一个值用 const,一组状态用 enum。」
💻 VS2026 操作步骤
Step 1 新建控制台项目
打开 VS2026,选择 文件 > 新建 > 项目,搜索"控制台应用",选择 .NET 10 框架,项目名填 IndustrialConstEnumDemo,点击创建。
Copilot 辅助: 创建完成后,在
Program.cs顶部右键点击"使用 Copilot 解释此文件",可以快速了解 .NET 10 顶级语句(Top-level statements)结构。
Step 2 定义常量和枚举
在 Program.cs 同目录下,右键 添加 > 新建类,命名为 ProductionConfig.cs。在这个文件里集中定义所有 const 和 enum,便于统一维护。
Copilot 辅助: 在类文件里输入注释
// 定义注塑机设备状态枚举,然后按Tab键,Copilot 会自动补全一个符合工业场景的枚举结构,你只需要核对状态名称是否正确。
Step 3 使用 Vibe Coding 生成枚举逻辑
在 Copilot Chat 面板中输入以下 Prompt:
Prompt 示例: "帮我写一个 C# 方法,接收一个
InjectionMachineStatus枚举值,用 switch 表达式返回对应的中文状态描述字符串,枚举包含:待机、运行、报警、模具切换四种状态。"
Copilot 会直接生成完整方法。
Step 4 运行验证
按 F5 启动调试,在控制台窗口确认输出的状态描述与预期一致。如有报错,选中错误行,右键选择 "让 Copilot 修复",通常一键即可解决。