
目录
在Python开发中,特别是数据分析和科学计算领域,NumPy可以说是最核心的基础库之一。无论你是刚入门的Python新手,还是正在从事上位机开发、数据处理的工程师,掌握NumPy都是必不可少的技能。
很多初学者在接触NumPy时,往往被其丰富的API和复杂的概念搞得晕头转向。什么是多维数组?如何高效地创建和操作这些数组?这些看似简单的问题,实际上隐藏着许多实战中的关键技巧。
本文将从实际应用角度出发,通过详细的代码示例和实战场景,带你彻底掌握NumPy数组的创建与基本操作,让你在Windows环境下的Python开发更加得心应手。
🔍 问题分析:为什么选择NumPy?
在深入学习NumPy之前,我们先来理解一个核心问题:为什么不直接使用Python原生的list,而要选择NumPy数组?
性能对比实验
让我们通过一个简单的实验来直观感受差异:
Pythonimport numpy as np
import time
# 创建大型数据集
size = 1000000
python_list = list(range(size))
numpy_array = np.arange(size)
# 测试Python list求和性能
start_time = time.time()
python_sum = sum(python_list)
python_time = time.time() - start_time
# 测试NumPy数组求和性能
start_time = time.time()
numpy_sum = np.sum(numpy_array)
numpy_time = time.time() - start_time
print(f"Python list求和耗时: {python_time:.4f}秒")
print(f"NumPy数组求和耗时: {numpy_time:.4f}秒")
print(f"NumPy性能提升: {python_time/numpy_time:.1f}倍")
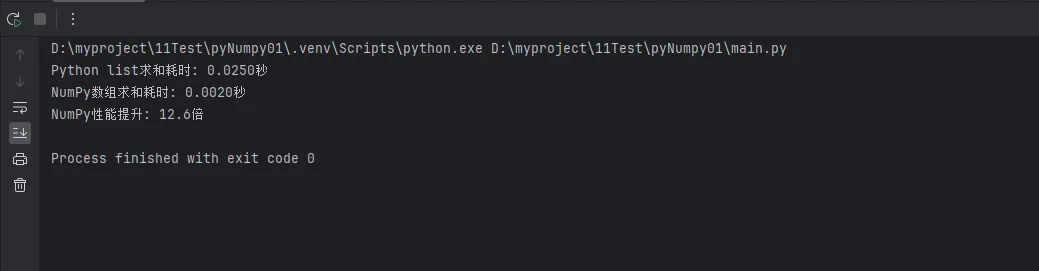
运行结果通常显示,NumPy的性能比原生Python list快10-100倍!这种性能优势在处理大数据时尤为明显。
💡 解决方案:NumPy数组创建的六种核心方法
🌟 方法一:从Python数据结构创建
这是最直观的创建方式,适合将现有的Python数据转换为NumPy数组:
Pythonimport numpy as np
# 从列表创建一维数组
data_1d = [1, 2, 3, 4, 5]
arr_1d = np.array(data_1d)
print(f"一维数组: {arr_1d}")
print(f"数组形状: {arr_1d.shape}")
print(f"数据类型: {arr_1d.dtype}")
# 从嵌套列表创建二维数组
data_2d = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
arr_2d = np.array(data_2d)
print(f"二维数组:\n{arr_2d}")
print(f"数组形状: {arr_2d.shape}")
# 指定数据类型
arr_float = np.array([1, 2, 3], dtype=np.float32)
print(f"指定float32类型: {arr_float}")
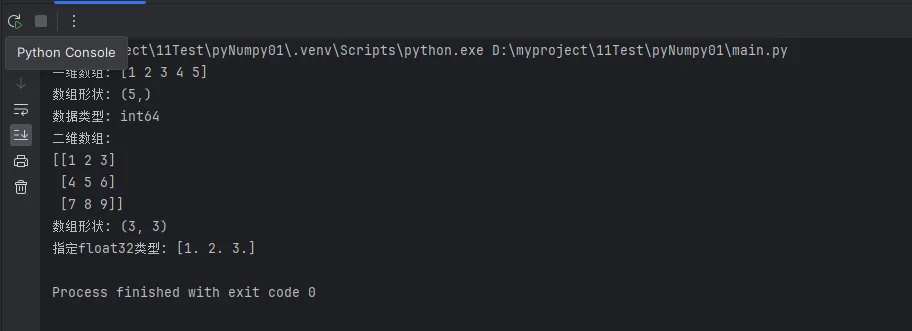
实战技巧:在Windows环境下进行上位机开发时,经常需要处理从传感器读取的数据,这种创建方式最为常用。
🌟 方法二:使用内置函数快速创建
NumPy提供了多个便捷函数,可以快速创建特定模式的数组:
Pythonimport numpy as np
# 创建全零数组(常用于初始化缓冲区)
zeros_arr = np.zeros((3, 4))
print(f"全零数组:\n{zeros_arr}")
# 创建全一数组
ones_arr = np.ones((2, 3), dtype=int)
print(f"全一数组:\n{ones_arr}")
# 创建单位矩阵(在线性代数计算中必不可少)
identity_matrix = np.eye(3)
print(f"3x3单位矩阵:\n{identity_matrix}")
# 创建指定值填充的数组
full_arr = np.full((2, 4), 7)
print(f"指定值填充数组:\n{full_arr}")
# 创建空数组(注意:内容是随机的!)
empty_arr = np.empty((2, 2))
print(f"空数组:\n{empty_arr}")
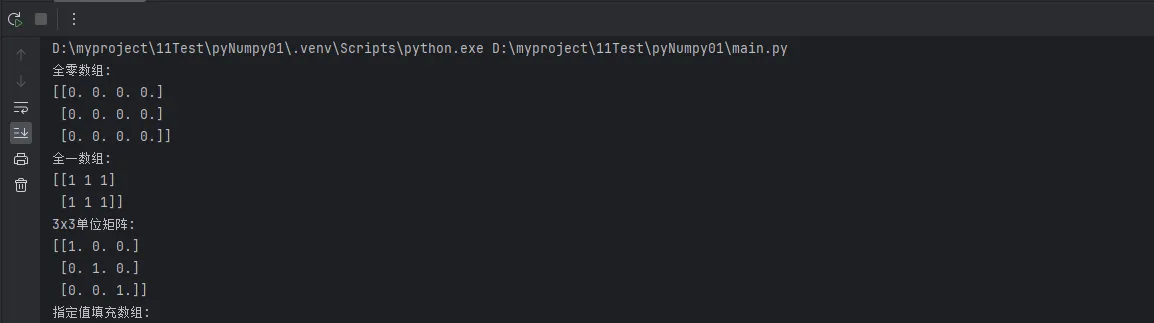
注意事项:np.empty()创建的数组内容是未定义的,在实际项目中使用时要格外小心,建议优先使用np.zeros()。
🌟 方法三:数值范围创建法
这类方法在生成测试数据、创建坐标系等场景中极其有用:
Pythonimport matplotlib
matplotlib.use('TkAgg') # Set the backend to TkAgg
import numpy as np
import matplotlib.pyplot as plt
# arange:类似Python的range,但返回NumPy数组
arr_range = np.arange(0, 10, 2) # 起始值、结束值、步长
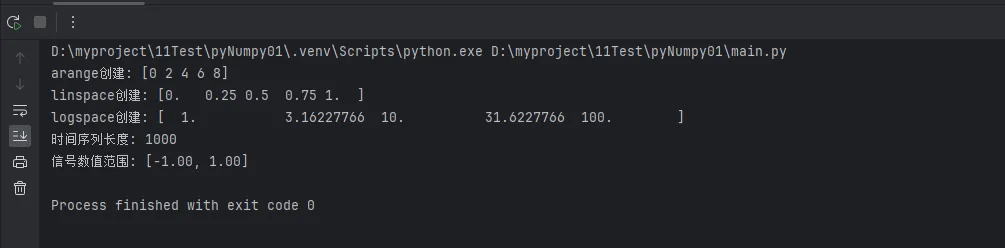
print(f"arange创建: {arr_range}")
# linspace:在指定区间内创建等间距的数值
arr_linspace = np.linspace(0, 1, 5) # 起始值、结束值、元素个数
print(f"linspace创建: {arr_linspace}")
# logspace:创建等比数列
arr_logspace = np.logspace(0, 2, 5) # 10^0到10^2,5个元素
print(f"logspace创建: {arr_logspace}")
# 实战应用:创建时间序列
time = np.linspace(0, 4*np.pi, 1000)
signal = np.sin(time)
print(f"时间序列长度: {len(time)}")
print(f"信号数值范围: [{signal.min():.2f}, {signal.max():.2f}]")
plt.plot(time, signal)
plt.title("Sine Wave")
plt.xlabel("Time")
plt.ylabel("Amplitude")
plt.grid()
plt.show()
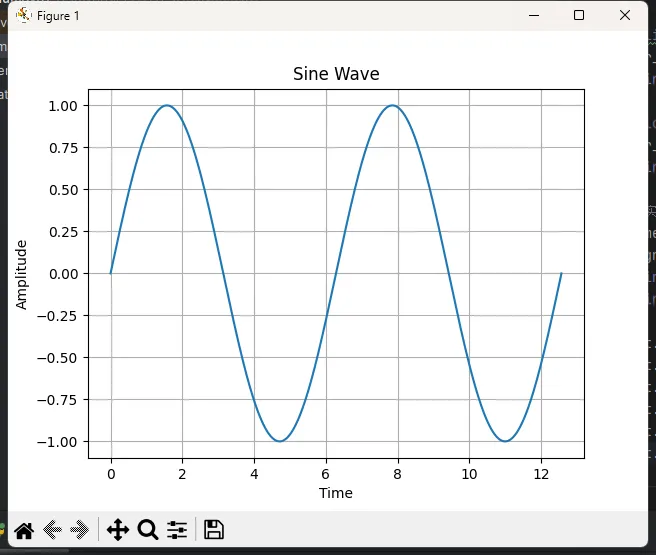
编程技巧:在Windows下开发数据可视化应用时,linspace是创建平滑曲线的最佳选择。
🌟 方法四:随机数组创建
在机器学习、数据模拟、测试等场景中,随机数组创建是必备技能:
Pythonimport numpy as np
# 设置随机种子(确保结果可重现)
np.random.seed(42)
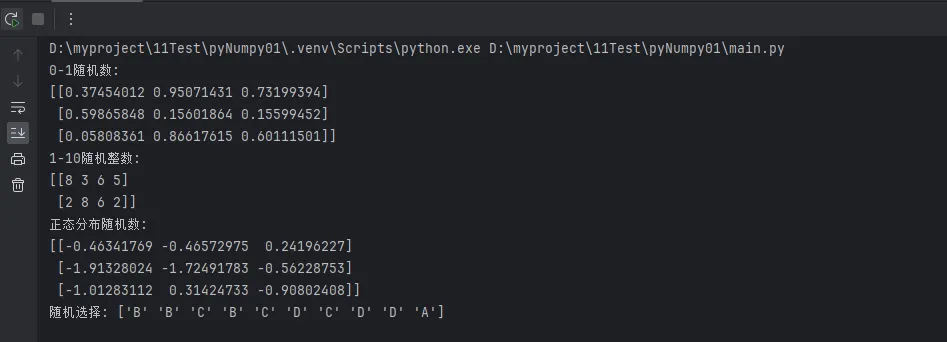
# 创建0-1之间的随机数
random_uniform = np.random.random((3, 3))
print(f"0-1随机数:\n{random_uniform}")
# 创建指定范围的随机整数
random_int = np.random.randint(1, 10, size=(2, 4))
print(f"1-10随机整数:\n{random_int}")
# 创建正态分布随机数
random_normal = np.random.normal(0, 1, (3, 3)) # 均值0,标准差1
print(f"正态分布随机数:\n{random_normal}")
# 从数组中随机选择元素
choices = np.array(['A', 'B', 'C', 'D'])
random_choice = np.random.choice(choices, size=10, replace=True)
print(f"随机选择: {random_choice}")
实战提示:在进行算法测试时,使用np.random.seed()设置固定种子,可以确保每次运行得到相同的随机数,便于调试和结果对比。
🌟 方法五:从文件读取创建
在实际项目中,数据往往存储在外部文件中,NumPy提供了便捷的文件读取功能:
Pythonimport numpy as np
# 创建示例数据并保存到文件
sample_data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 保存为.npy格式(NumPy原生格式,速度最快)
np.save('sample_data.npy', sample_data)
# 保存为文本格式
np.savetxt('sample_data.txt', sample_data, delimiter=',')
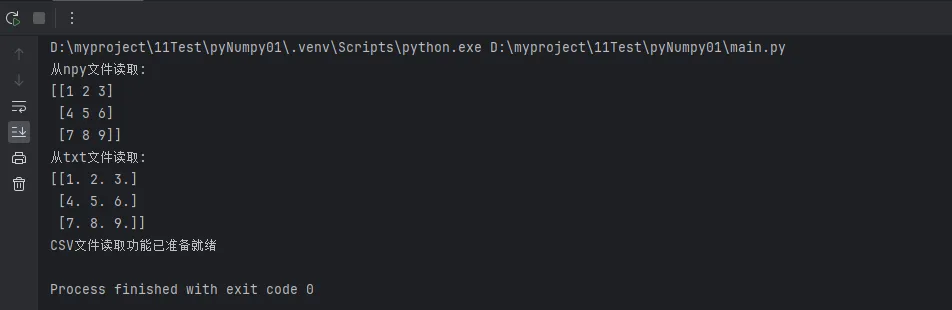
# 从.npy文件读取
loaded_npy = np.load('sample_data.npy')
print(f"从npy文件读取:\n{loaded_npy}")
# 从文本文件读取
loaded_txt = np.loadtxt('sample_data.txt', delimiter=',')
print(f"从txt文件读取:\n{loaded_txt}")
# 处理CSV文件(在数据分析中最常用)
try:
# 假设有一个data.csv文件
# csv_data = np.loadtxt('data.csv', delimiter=',', skiprows=1)
print("CSV文件读取功能已准备就绪")
except:
print("CSV文件不存在,但代码结构正确")
最佳实践:对于大型数据集,推荐使用.npy格式,读写速度比文本格式快数倍。
🌟 方法六:特殊结构数组创建
某些特殊应用场景需要创建具有特定结构的数组:
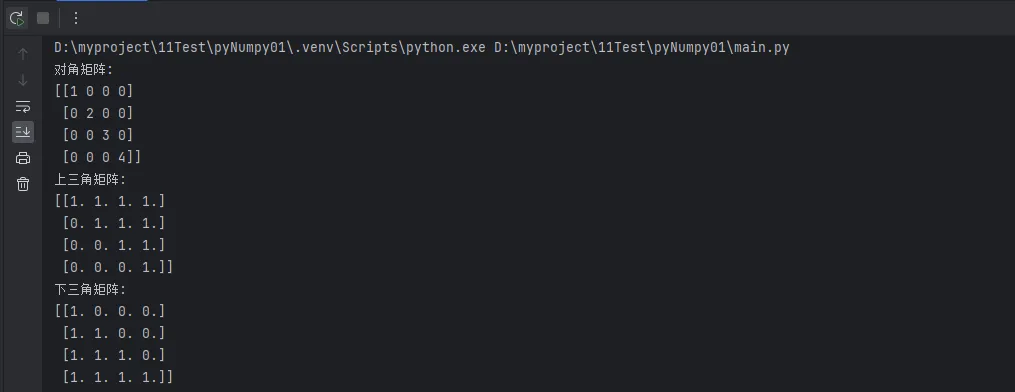
Python# 创建对角矩阵
diag_arr = np.diag([1, 2, 3, 4])
print(f"对角矩阵:\n{diag_arr}")
# 创建上三角矩阵
upper_tri = np.triu(np.ones((4, 4)))
print(f"上三角矩阵:\n{upper_tri}")
# 创建下三角矩阵
lower_tri = np.tril(np.ones((4, 4)))
print(f"下三角矩阵:\n{lower_tri}")
# 使用meshgrid创建坐标矩阵(在图像处理中常用)
x = np.arange(0, 3)
y = np.arange(0, 4)
X, Y = np.meshgrid(x, y)
print(f"X坐标矩阵:\n{X}")
print(f"Y坐标矩阵:\n{Y}")
🔥 代码实战:基本操作深度解析
数组属性查看
了解数组的基本属性是进行后续操作的前提:
Pythonimport numpy as np
# 创建一个示例数组
arr = np.random.randint(0, 100, (3, 4, 2))
print(f"数组形状: {arr.shape}")
print(f"数组维度: {arr.ndim}")
print(f"元素总数: {arr.size}")
print(f"数据类型: {arr.dtype}")
print(f"每个元素字节数: {arr.itemsize}")
print(f"总字节数: {arr.nbytes}")
print(f"数组步长: {arr.strides}")
# 查看数组的内存布局
print(f"数组是否连续: {arr.flags.c_contiguous}")
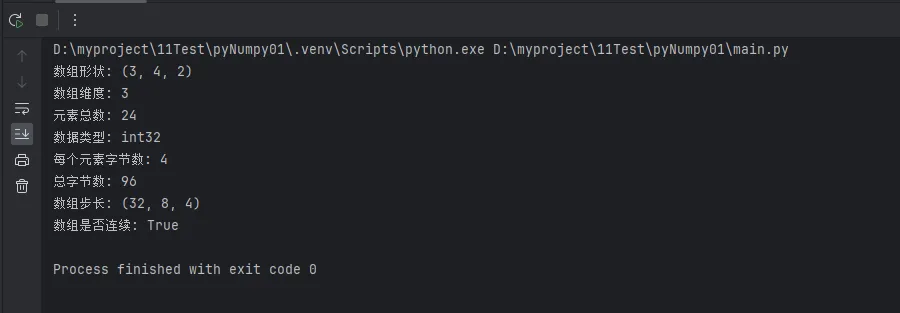
调试技巧:在Windows环境下调试NumPy程序时,经常查看这些属性可以快速定位数组操作问题。
数组形状操作
形状操作是NumPy中最重要的概念之一:
Pythonimport numpy as np
# 原始数组
original = np.arange(12)
print(f"原始数组: {original}")
# reshape:改变形状但不改变数据
reshaped = original.reshape(3, 4)
print(f"重塑为3x4:\n{reshaped}")
# resize:改变形状可能改变数据
arr_copy = original.copy()
arr_copy.resize(2, 8) # 如果元素不够会用0填充
print(f"resize结果:\n{arr_copy}")
# flatten vs ravel
matrix = np.array([[1, 2], [3, 4]])
flat1 = matrix.flatten() # 返回副本
flat2 = matrix.ravel() # 返回视图(如果可能)
flat1[0] = 999 # 不会影响原数组
print(f"flatten修改后原数组: {matrix}")
flat2[0] = 888 # 会影响原数组
print(f"ravel修改后原数组: {matrix}")
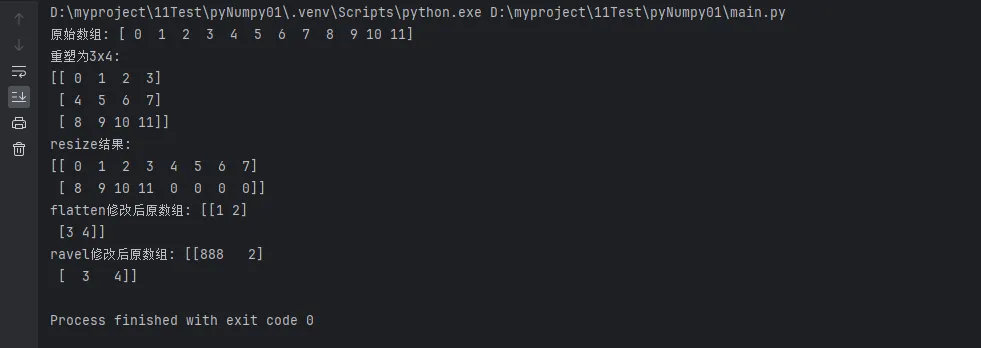
重要区别:flatten()总是返回副本,而ravel()尽可能返回视图,这在处理大数组时对性能影响很大。
数组索引与切片
掌握高效的索引和切片技巧是NumPy编程的核心:
Python# 创建二维数组进行索引演示
arr_2d = np.arange(20).reshape(4, 5)
print(f"原始数组:\n{arr_2d}")
# 基础索引
print(f"第2行第3列元素: {arr_2d[1, 2]}")
print(f"第一行: {arr_2d[0, :]}")
print(f"第一列: {arr_2d[:, 0]}")
# 高级索引
# 布尔索引
bool_idx = arr_2d > 10
print(f"大于10的元素: {arr_2d[bool_idx]}")
# 整数索引
row_idx = [0, 2]
col_idx = [1, 3]
print(f"指定位置元素: {arr_2d[row_idx, col_idx]}")
# 切片操作
print(f"前两行,后三列:\n{arr_2d[:2, -3:]}")
# 条件索引的实战应用
# 模拟传感器数据,筛选异常值
sensor_data = np.random.normal(25, 5, 100) # 模拟温度数据
abnormal_data = sensor_data[(sensor_data < 10) | (sensor_data > 40)]
print(f"异常温度数据: {abnormal_data}")
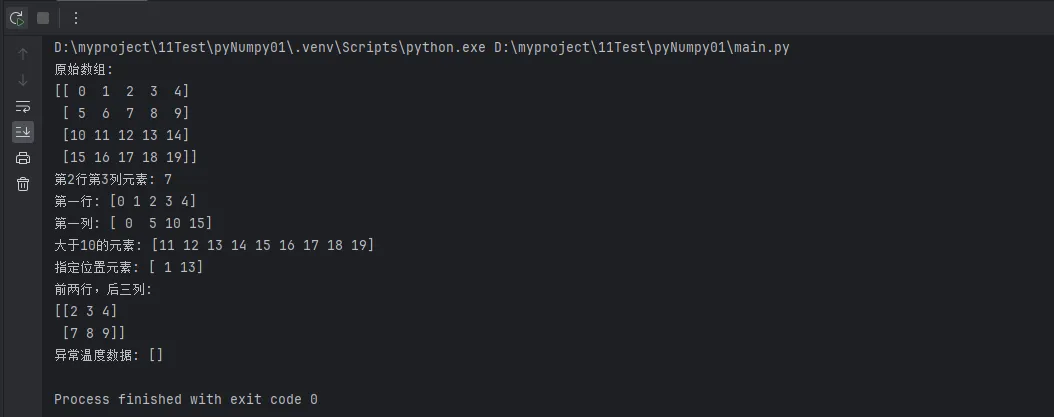
实战经验:在Windows下开发上位机程序时,布尔索引是筛选异常数据的最佳方式。
数学运算与统计
NumPy的向量化运算是其最大优势:
Pythonimport numpy as np
# 创建测试数组
arr1 = np.array([1, 2, 3, 4, 5])
arr2 = np.array([10, 20, 30, 40, 50])
# 基本数学运算
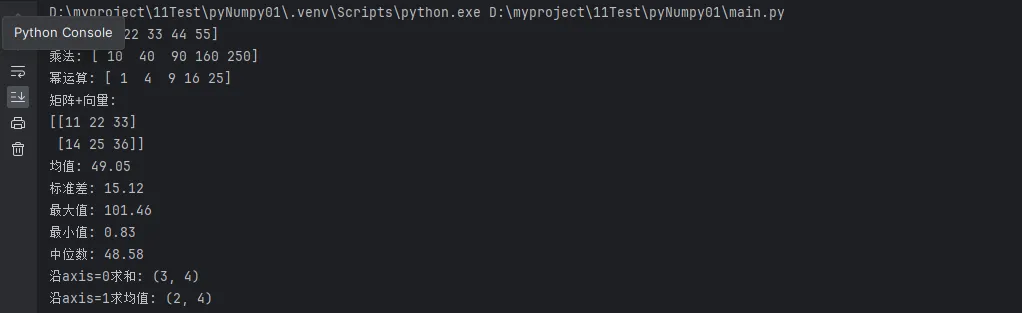
print(f"加法: {arr1 + arr2}")
print(f"乘法: {arr1 * arr2}")
print(f"幂运算: {arr1 ** 2}")
# 广播机制
matrix = np.array([[1, 2, 3], [4, 5, 6]])
vector = np.array([10, 20, 30])
print(f"矩阵+向量:\n{matrix + vector}")
# 统计函数
data = np.random.normal(50, 15, 1000)
print(f"均值: {np.mean(data):.2f}")
print(f"标准差: {np.std(data):.2f}")
print(f"最大值: {np.max(data):.2f}")
print(f"最小值: {np.min(data):.2f}")
print(f"中位数: {np.median(data):.2f}")
# 沿指定轴的运算
matrix_3d = np.random.randint(0, 100, (2, 3, 4))
print(f"沿axis=0求和: {np.sum(matrix_3d, axis=0).shape}")
print(f"沿axis=1求均值: {np.mean(matrix_3d, axis=1).shape}")
 性能提示:使用NumPy的内置函数比使用Python循环快50-100倍,在处理大数据时差异更加明显。
性能提示:使用NumPy的内置函数比使用Python循环快50-100倍,在处理大数据时差异更加明显。
数组连接与分割
在数据处理中,经常需要合并或分割数组:
Python# 数组连接
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[5, 6], [7, 8]])
# 垂直连接(按行)
v_concat = np.vstack([arr1, arr2])
print(f"垂直连接:\n{v_concat}")
# 水平连接(按列)
h_concat = np.hstack([arr1, arr2])
print(f"水平连接:\n{h_concat}")
# 通用连接函数
concat_axis0 = np.concatenate([arr1, arr2], axis=0)
concat_axis1 = np.concatenate([arr1, arr2], axis=1)
# 数组分割
large_arr = np.arange(16).reshape(4, 4)
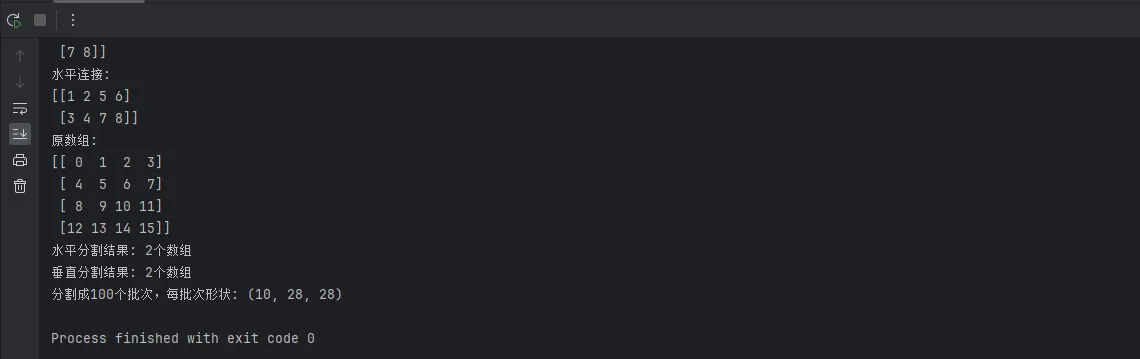
print(f"原数组:\n{large_arr}")
# 水平分割
h_splits = np.hsplit(large_arr, 2)
print(f"水平分割结果: {len(h_splits)}个数组")
# 垂直分割
v_splits = np.vsplit(large_arr, 2)
print(f"垂直分割结果: {len(v_splits)}个数组")
# 实际应用:批量处理数据
batch_data = np.random.randint(0, 255, (1000, 28, 28)) # 模拟图像数据
batch_size = 100
batches = np.array_split(batch_data, batch_size)
print(f"分割成{len(batches)}个批次,每批次形状: {batches[0].shape}")
🎯 实战项目:数据处理完整案例
让我们通过一个完整的实战案例来巩固所学知识:
Pythonimport numpy as np
import matplotlib.pyplot as plt
# 模拟工业传感器数据处理项目
def sensor_data_analysis():
"""
模拟传感器数据采集与分析
应用场景:Windows环境下的上位机数据处理
"""
# 1. 创建模拟传感器数据
np.random.seed(42) # 确保结果可重现
# 模拟24小时温度数据,每分钟一个数据点
time_points = 24 * 60 # 1440个数据点
base_temp = 25 # 基础温度
# 创建时间序列
time = np.linspace(0, 24, time_points)
# 添加日夜温差(正弦波)
daily_pattern = 5 * np.sin(2 * np.pi * time / 24 - np.pi/2)
# 添加随机噪声
noise = np.random.normal(0, 1, time_points)
# 添加一些异常值
anomaly_indices = np.random.choice(time_points, 20, replace=False)
anomaly_values = np.random.uniform(-10, 10, 20)
# 生成最终温度数据
temperature = base_temp + daily_pattern + noise
temperature[anomaly_indices] += anomaly_values
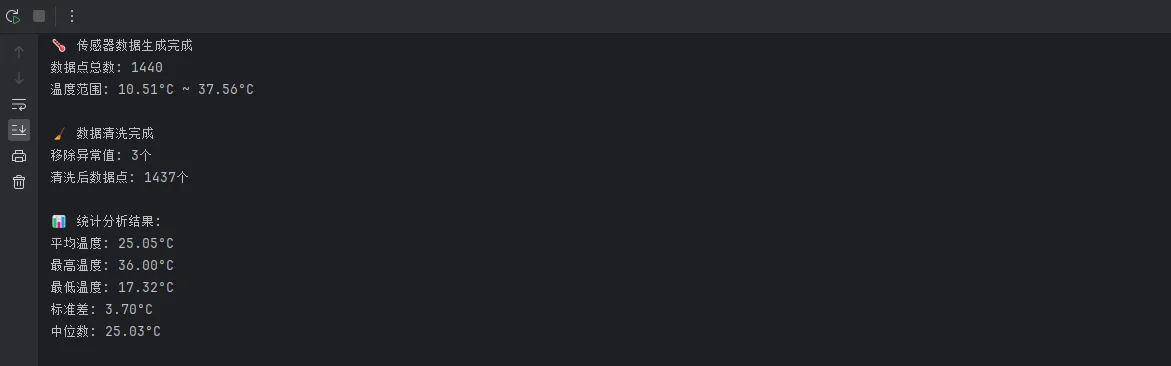
print("🌡️ 传感器数据生成完成")
print(f"数据点总数: {len(temperature)}")
print(f"温度范围: {temperature.min():.2f}°C ~ {temperature.max():.2f}°C")
# 2. 数据清洗:去除异常值
# 使用3σ原则检测异常值
mean_temp = np.mean(temperature)
std_temp = np.std(temperature)
# 定义异常值阈值
threshold = 3 * std_temp
normal_mask = np.abs(temperature - mean_temp) <= threshold
clean_temperature = temperature[normal_mask]
clean_time = time[normal_mask]
print(f"\n🧹 数据清洗完成")
print(f"移除异常值: {len(temperature) - len(clean_temperature)}个")
print(f"清洗后数据点: {len(clean_temperature)}个")
# 3. 数据统计分析
stats = {
'平均温度': np.mean(clean_temperature),
'最高温度': np.max(clean_temperature),
'最低温度': np.min(clean_temperature),
'标准差': np.std(clean_temperature),
'中位数': np.median(clean_temperature)
}
print(f"\n📊 统计分析结果:")
for key, value in stats.items():
print(f"{key}: {value:.2f}°C")
# 4. 时段分析
# 将数据按小时分组
hours = np.arange(24)
hourly_temps = []
for hour in hours:
# 找到该小时的所有数据点
hour_mask = (clean_time >= hour) & (clean_time < hour + 1)
hour_temps = clean_temperature[hour_mask]
if len(hour_temps) > 0:
hourly_temps.append(np.mean(hour_temps))
else:
hourly_temps.append(np.nan)
hourly_temps = np.array(hourly_temps)
# 找出最热和最冷的时段
valid_hours = ~np.isnan(hourly_temps)
hottest_hour = hours[valid_hours][np.argmax(hourly_temps[valid_hours])]
coldest_hour = hours[valid_hours][np.argmin(hourly_temps[valid_hours])]
print(f"\n🕐 时段分析:")
print(f"最热时段: {hottest_hour}:00 - {hottest_hour+1}:00")
print(f"最冷时段: {coldest_hour}:00 - {coldest_hour+1}:00")
# 5. 数据导出
# 创建结构化数据用于导出
export_data = np.column_stack([clean_time, clean_temperature])
# 保存为CSV格式
header = 'Time(hours),Temperature(°C)'
np.savetxt('sensor_data_clean.csv', export_data,
delimiter=',', header=header, comments='')
# 保存统计结果
stats_array = np.array([list(stats.values())])
stats_header = ','.join(stats.keys())
np.savetxt('sensor_stats.csv', stats_array,
delimiter=',', header=stats_header, comments='')
print(f"\n💾 数据导出完成:")
print("- sensor_data_clean.csv: 清洗后的原始数据")
print("- sensor_stats.csv: 统计分析结果")
return clean_time, clean_temperature, hourly_temps
# 运行实战项目
if __name__ == "__main__":
print("🚀 开始传感器数据分析项目")
print("=" * 50)
try:
time_data, temp_data, hourly_data = sensor_data_analysis()
print("\n✅ 项目执行成功!")
# 额外的数据验证
print(f"\n🔍 最终验证:")
print(f"时间数据形状: {time_data.shape}")
print(f"温度数据形状: {temp_data.shape}")
print(f"小时数据形状: {hourly_data.shape}")
except Exception as e:
print(f"❌ 项目执行出错: {e}")
这个实战项目展示了NumPy在实际数据处理中的完整应用流程,从数据生成到清洗、分析、导出,每一步都体现了NumPy的强大功能。
⚡ 性能优化技巧
在Windows环境下进行Python开发,性能优化至关重要:
Pythonimport numpy as np
# 性能优化技巧演示
import time
# 技巧1:使用向量化操作替代循环
def compare_performance():
size = 1000000
arr1 = np.random.random(size)
arr2 = np.random.random(size)
# 低效的Python循环
start = time.time()
result_slow = []
for i in range(len(arr1)):
result_slow.append(arr1[i] * arr2[i] + 1)
time_slow = time.time() - start
# 高效的NumPy向量化操作
start = time.time()
result_fast = arr1 * arr2 + 1
time_fast = time.time() - start
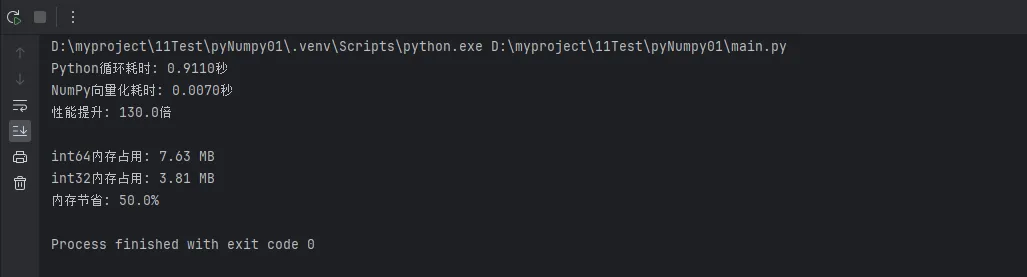
print(f"Python循环耗时: {time_slow:.4f}秒")
print(f"NumPy向量化耗时: {time_fast:.4f}秒")
print(f"性能提升: {time_slow / time_fast:.1f}倍")
# 技巧2:合理使用数据类型
def optimize_memory():
# 默认int64占用更多内存
large_arr_64 = np.arange(1000000, dtype=np.int64)
# 如果数值范围允许,使用int32
large_arr_32 = np.arange(1000000, dtype=np.int32)
print(f"int64内存占用: {large_arr_64.nbytes / 1024 / 1024:.2f} MB")
print(f"int32内存占用: {large_arr_32.nbytes / 1024 / 1024:.2f} MB")
print(f"内存节省: {(1 - large_arr_32.nbytes / large_arr_64.nbytes) * 100:.1f}%")
# 运行性能测试
compare_performance()
print()
optimize_memory()
🎯 结尾呼应
通过本文的详细学习,我们已经全面掌握了NumPy数组创建与基本操作的核心技能。让我们来总结三个关键要点:
1. 多样化的创建方式是基础:从基础的np.array()到高级的随机数生成,从文件读取到特殊结构创建,每种方式都有其特定的应用场景。在Windows环境下的Python开发中,选择合适的创建方式能够显著提升开发效率。
2. 向量化操作是性能保证:NumPy的最大优势在于向量化运算,相比原生Python循环能够提升10-100倍的性能。在处理大数据或实时数据时,这种性能优势是决定性的。掌握索引、切片、广播等核心概念,是编写高效NumPy代码的关键。
3. 实战应用是最终目标:理论知识只有结合实际项目才能真正发挥价值。无论是上位机开发、数据分析还是科学计算,NumPy都是不可或缺的基础工具。通过本文的完整实战案例,你已经具备了在实际项目中应用NumPy的能力。
NumPy作为Python科学计算生态的基石,值得每一位开发者深入学习。希望本文能够成为你NumPy学习路上的得力助手,助你在编程技巧提升的道路上更进一步。继续深入学习NumPy的高级功能,如线性代数运算、傅里叶变换等,将为你的Python开发能力带来质的飞跃。
本文适合收藏学习,建议配合实际项目练习,在Windows环境下逐步掌握NumPy的精髓。如果你在学习过程中遇到问题,欢迎交流讨论!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!