
目录
简介
矩阵因子分解(Matrix Factorization)是一种常用的推荐算法,特别适用于基于用户历史评分数据的协同过滤推荐场景。本文将详细介绍如何使用ML.NET实现一个基于矩阵因子分解的电影推荐系统。
实现步骤
1. 创建项目与安装依赖
C#// 创建.NET 6 控制台应用
// 安装NuGet包:
// - Microsoft.ML
// - Microsoft.ML.Recommender
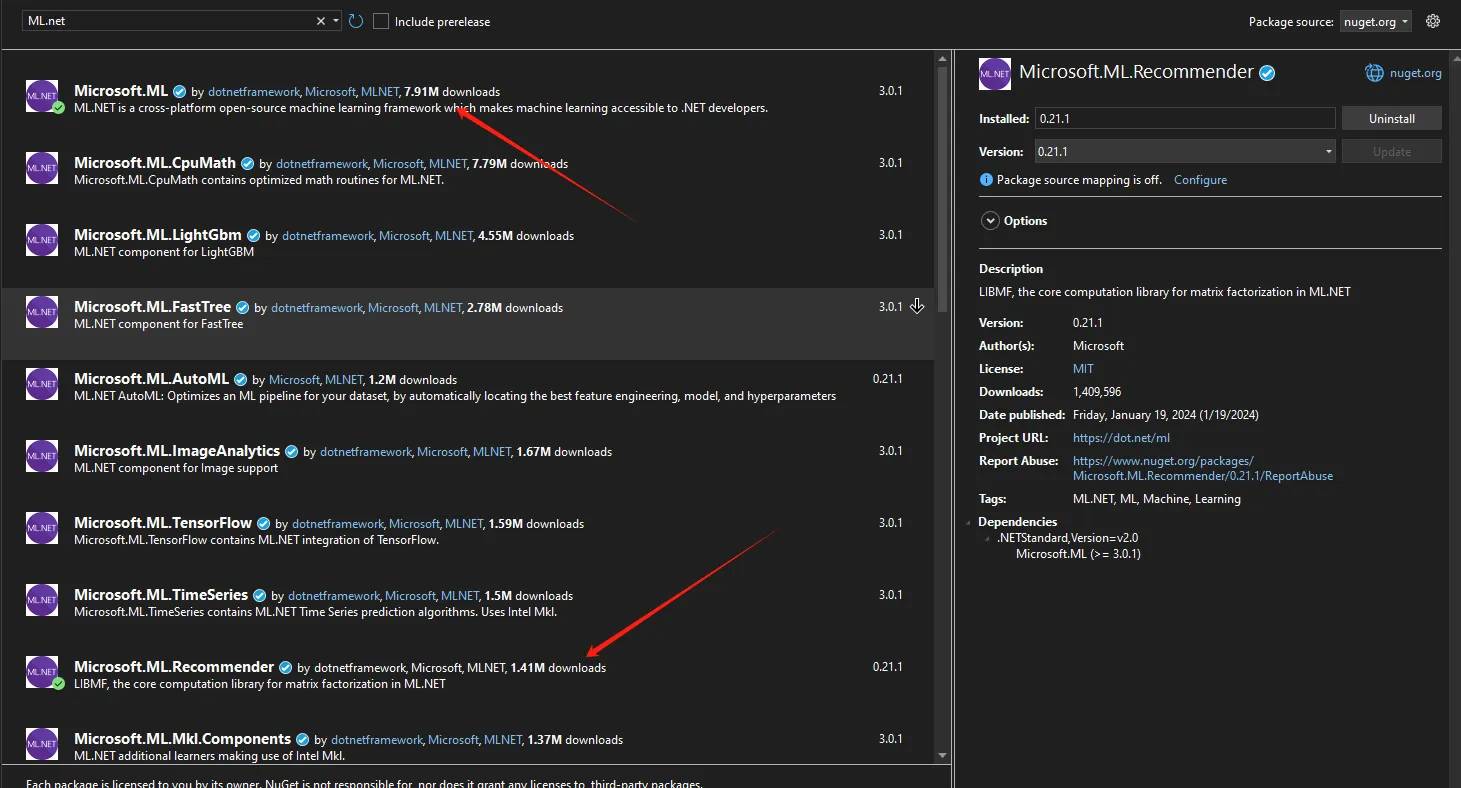
准备工作
找到一个测试文件,一个训练文件,Ms官方的。
HTMLhttps://raw.githubusercontent.com/dotnet/machinelearning-samples/main/samples/csharp/getting-started/MatrixFactorization_MovieRecommendation/Data/recommendation-ratings-train.csv
HTMLhttps://raw.githubusercontent.com/dotnet/machinelearning-samples/main/samples/csharp/getting-started/MatrixFactorization_MovieRecommendation/Data/recommendation-ratings-test.csv
格式如下:
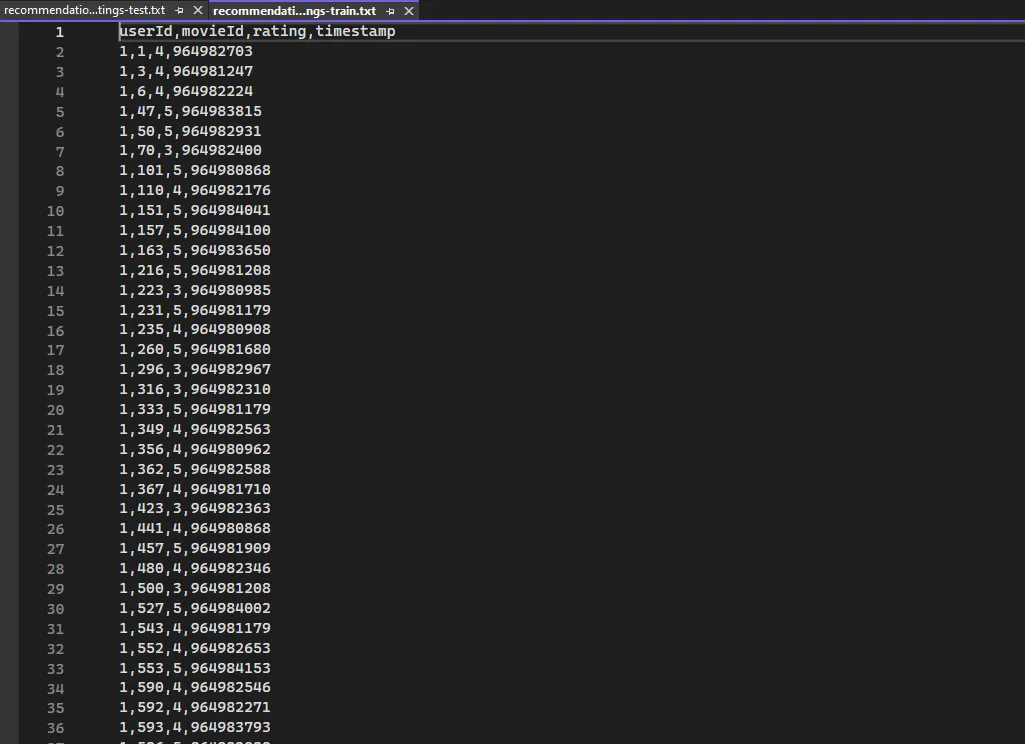
添加到项目中,记得,我习惯总是copy
这个集的列分别为userId、movieId 用来预测 Label(rating)
2. 定义数据模型
C#public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
MovieRating定义了数据类型,LoadColumn 属性指定应加载的列。userId和 movieId 是预测的特征,rating是预测的标签。
类 MovieRatingPrediction,通过在 MovieRatingData.cs 中的 MovieRating 类之后添加以下代码来表示预测结果
3. 加载数据
C#// 加载训练和测试数据
static (IDataView training, IDataView test) LoadData(MLContext mlContext)
{
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.txt");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.txt");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(
trainingDataPath,
hasHeader: true,
separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(
testDataPath,
hasHeader: true,
separatorChar: ',');
return (trainingDataView, testDataView);
}
LoadFromTextFile() 方法用于定义数据架构并读取文件,返回 IDataView 对象。主要参数包括:
- 数据路径变量 (path) - 指定要加载的文本文件路径
- hasHeader (bool) - 指示文本文件是否包含标题行,用于正确使用列名称
- true: 文件包含标题行
- false: 文件不包含标题行
- separatorChar (char) - 指定数据分隔符字符
- 默认分隔符是制表符
- 可以指定其他分隔符,如逗号 ','
4. 构建和训练模型
C#static ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
// 定义数据转换
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion
.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion
.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
// 配置Matrix Factorization训练器
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 200,
ApproximationRank = 100
};
// 添加训练器
var trainerEstimator = estimator.Append(
mlContext.Recommendation().Trainers.MatrixFactorization(options));
// 训练模型
Console.WriteLine("=============== 训练模型 ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
}
estimator变量,主要目的是将用户ID和电影ID转换为算法可以处理的数字键类型特征列。
- 由于
userId和movieId代表的是用户和电影的标识符,而不是实际的数值,所以需要进行转换 - 使用
MapValueToKey()方法将:userId转换为userIdEncoded列movieId转换为movieIdEncoded列
- 转换后的数据结构会变成:
MarkdownuserId movieId Label userIdEncoded movieIdEncoded 1 4 3 userKey1 movieKey1 1 3 4 userKey1 movieKey2 1 6 4 userKey1 movieKey3
- 这种转换是必要的,因为推荐算法需要使用这种数字键类型的格式来处理数据
.Append()方法用于将多个转换步骤串联起来,形成一个完整的数据处理管道
MatrixFactorizationTrainer.Options 的参数:
MatrixColumnIndexColumnName = "userIdEncoded"- 指定矩阵分解中的列索引列名
- 这里使用编码后的用户ID作为列索引
MatrixRowIndexColumnName = "movieIdEncoded"- 指定矩阵分解中的行索引列名
- 这里使用编码后的电影ID作为行索引
LabelColumnName = "Label"- 指定标签列的名称
- 这里是用户对电影的评分值
NumberOfIterations = 20- 指定训练迭代的次数
- 每次迭代都会尝试减小误差,使预测更准确
- 这里设置为20次迭代
ApproximationRank = 100- 指定矩阵分解的近似秩
- 这个参数影响模型的复杂度和精确度
- 值越大,模型可以捕捉更复杂的模式,但也可能导致过拟合
这些是矩阵分解算法的参数,可以通过调整这些参数来优化模型性能。可以尝试调整 NumberOfIterations 和 ApproximationRank 这两个参数来获得更好的预测结果。
C#var trainerEstimator = estimator.Append(
mlContext.Recommendation().Trainers.MatrixFactorization(options));
构建推荐系统的训练管道,具体解释如下:
mlContext.Recommendation()- 访问 ML.NET 中的推荐系统功能模块
.Trainers.MatrixFactorization(options)- 选择矩阵分解算法作为推荐系统的训练器
- 使用之前定义的 options 参数配置训练器
estimator.Append()- 将矩阵分解训练器添加到之前创建的数据转换管道中
- 之前的 estimator 包含了 userId 和 movieId 的编码转换步骤
- 整体流程:
- 首先对原始数据进行预处理(ID编码)
- 然后使用矩阵分解算法进行模型训练
- 形成一个完整的端到端训练管道
这行代码实际上将数据预处理和模型训练组合在一起,创建了一个完整的推荐系统训练流程。当这个管道运行时,数据会依次经过ID编码转换,然后进入矩阵分解算法进行训练。
5. 评估模型
C#static void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
Console.WriteLine("=============== 评估模型 ===============");
var prediction = model.Transform(testDataView);
var metrics = mlContext.Regression.Evaluate(
prediction,
labelColumnName: "Label",
scoreColumnName: "Score");
Console.WriteLine($"RMSE : {metrics.RootMeanSquaredError}");
Console.WriteLine($"RSquared: {metrics.RSquared}");
}
metrics 包含两个重要的评估指标:
- Root Mean Squared Error (RMS 或 RMSE)
- 用于衡量模型预测值与测试数据集实际观察值之间的差异
- 从技术角度看,它是误差平方的平均值的平方根
- 这个指标越低越好,表示模型预测更准确
- RMSE = √(Σ(预测值 - 实际值)²/n)
- R Squared (R²)
- 用于表明数据与模型的拟合程度
- 取值范围从 0 到 1
- 0 表示数据是随机的,模型无法拟合
- 1 表示模型与数据完全匹配
- 通常希望 R Squared 分数尽可能接近 1
这些指标用于评估模型的性能。如果对模型质量不满意,可以通过以下方式改进:
- 提供更大的训练数据集
- 选择不同的训练算法
- 调整算法的MatrixFactorizationTrainer.Options 参数
6. 使用模型进行预测
C#static void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
Console.WriteLine("=============== 预测单个实例 ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
// 创建测试数据
var testInput = new MovieRating { userId = 6, movieId = 10 };
// 进行预测
var movieRatingPrediction = predictionEngine.Predict(testInput);
// 基于预测结果推荐
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine($"电影 {testInput.movieId} 推荐给用户 {testInput.userId}");
}
else
{
Console.WriteLine($"电影 {testInput.movieId} 不推荐给用户 {testInput.userId}");
}
}
C#var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
- 创建一个预测引擎实例
- 用于对单个数据实例进行预测
- 注意:PredictionEngine 不是线程安全的,仅适用于单线程或原型环境
- 在生产环境中建议使用 PredictionEnginePool 服务来确保线程安全和性能
7. 保存模型
C#static void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== 保存模型文件===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
}
8.运行
C#static void Main(string[] args)
{
MLContext mlContext = new MLContext();
(IDataView training, IDataView test) = LoadData(mlContext);
ITransformer model = BuildAndTrainModel(mlContext, training);
EvaluateModel(mlContext, test, model);
UseModelForSinglePrediction(mlContext, model);
SaveModel(mlContext, training.Schema, model);
Console.WriteLine("按任意键退出...");
Console.ReadKey();
}

注意:
- 预测值与实际值之间的平均偏差大约在1个单位左右
- 在电影推荐系统的例子中,如果评分范围是1-5分,RMSE=1意味着系统预测的评分与实际用户评分平均相差1分左右
从模型性能来看:
-
RMSE=1说明模型的预测精度一般,还有改进空间
-
因为RMSE的值越小越好,理想情况下应该接近0
-
在1-5分的评分体系中,预测误差1分算是比较大的偏差
-
R²的取值范围是0到1之间
-
R²=0.4意味着模型能解释40%的数据变异性
-
换句话说:
- 40%的预测结果可以被模型解释
- 还有60%的变异性无法被当前模型解释
- 表明模型的拟合程度一般,还有较大的改进空间
结合RMSE=1来看:
-
RMSE=1表示预测值与实际值的平均偏差在1个单位左右
-
R²=0.4表示模型只捕捉到40%的数据规律
-
这两个指标都表明模型性能一般:
- RMSE较大,说明预测误差较大
- R²较低,说明模型解释能力有限
改进建议
- 数据量: 增加训练数据量可提升模型性能
- 特征工程: 可添加用户和电影的其他特征
- 参数调优: 可尝试不同的NumberOfIterations和ApproximationRank值
- 冷启动处理: 对新用户可要求其提供初始评分数据
使用场景
- 电商产品推荐
- 影视内容推荐
- 音乐推荐
- 新闻文章推荐
这个实现展示了如何使用ML.NET构建一个基础的推荐系统。在实际应用中,可以根据具体需求进行优化和扩展。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!