
目录
在机器学习中,感知器(Perceptron)是一种历史悠久且影响力深远的线性分类算法,尤其在文本分类、情感分析、手写数字识别等领域有着广泛的应用。ML.NET 提供了 AveragedPerceptronTrainer 训练器,让 C# 开发者无需切换技术栈即可轻松构建基于感知器的预测模型。下面,我们就来深入探讨这一训练器的适用场景、优点以及如何在 ML.NET 中使用它。
AveragedPerceptronTrainer 简介
线性模型的基础
感知器是一种 线性模型,通过学习输入特征的加权和并应用激活函数来完成分类任务。对于二元分类而言,它会输出一个大于或小于某个阈值的数值来判断属于正类或负类。在训练过程中,感知器不断更新权重(weights),试图最小化预测错误。
算法的“平均”权重
AveragedPerceptronTrainer 与传统感知器最大的区别在于 采用了平均权重策略。在训练过程中,每次更新参数时,训练器都会累加并平均所有更新后的权重值,从而减少对噪声数据的敏感度,提高模型的泛化能力。
适用场景
文本分类/情感分析
AveragedPerceptronTrainer 在处理高维稀疏特征问题时表现良好,例如文本分类、情感分析、垃圾邮件检测等。通过基于 TF-IDF 或词袋(Bag of Words)的向量化方式来转换文本特征,即可使用 AveragedPerceptronTrainer 进行训练。
小规模、高速训练需求
如果你需要在资源有限或数据规模不大的场景下进行快速实验,AveragedPerceptronTrainer 是一种非常高效的选择。它训练速度快,往往不需要大量计算资源,适合在小规模数据集上快速迭代模型。
对线性可分问题表现良好
对于线性可分问题,感知器可在有限次迭代后找到一个合适的超平面进行分类。同时,AveragedPerceptronTrainer 利用平均权重来减少过拟合风险,帮助模型更好的泛化。
实战示例:使用 AveragedPerceptronTrainer 进行评论情感分析
下面通过一个完整的示例,演示如何使用 AveragedPerceptronTrainer 来区分评论的正向情感和负向情感(“正面”“负面”二元分类)。
数据示例
本示例中,假设我们有一个示例数据集 SentimentData.tsv ,其中包含了文本内容和情感标签。文件内容大概形式如下:
Markdownlabel,text 1,很快,好吃,味道足,量大 1,没有送水没有送水没有送水 1,非常快,态度好。 1,方便,快捷,味道可口,快递给力 1,菜味道很棒!送餐很及时! 1,今天师傅是不是手抖了,微辣格外辣! 1,"送餐快,态度也特别好,辛苦啦谢谢" 1,超级快就送到了,这么冷的天气骑士们辛苦了。谢谢你们。麻辣香锅依然很好吃。 1,经过上次晚了2小时,这次超级快,20分钟就送到了……
Label:标签列,0表示负面情感,1表示正面情感Text:评论文本
Nuget 安装ML.Net
C# 实现示例代码
以下是一个完整的 C# 控制台程序示例,展示了如何使用 ML.NET 的 AveragedPerceptronTrainer 进行训练和预测。请留意我们为每一步都添加了清晰的中文注释,帮助你快速理解各环节的作用。
C#using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.ML.Data;
namespace AppAveragedPerceptronTrainer
{
// 定义数据模型类
public class ReviewData
{
[LoadColumn(0)]
public bool Label { get; set; }
[LoadColumn(1)]
public string Text { get; set; }
}
// 定义预测输出类
public class ReviewPrediction
{
[ColumnName("PredictedLabel")]
public bool Prediction { get; set; }
[ColumnName("Probability")]
public float Probability { get; set; }
[ColumnName("Score")]
public float Score { get; set; }
}
}
C#using Microsoft.ML;
using Microsoft.ML.Transforms.Text;
namespace AppAveragedPerceptronTrainer
{
internal class Program
{
static readonly string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "reviews.csv");
static readonly string _modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "Model.zip");
static void Main(string[] args)
{
// 创建 ML.NET 环境
var mlContext = new MLContext(seed: 1);
// 加载数据
IDataView dataView = mlContext.Data.LoadFromTextFile<ReviewData>(_dataPath, hasHeader: true, separatorChar: ',');
// 分割训练集和测试集
var trainTestData = mlContext.Data.TrainTestSplit(dataView, testFraction: 0.2);
// 创建数据处理和训练管道
var pipeline = mlContext.Transforms.Text
.FeaturizeText(outputColumnName: "Features", inputColumnName: nameof(ReviewData.Text))
// 添加AveragedPerceptron训练器
.Append(mlContext.BinaryClassification.Trainers.AveragedPerceptron(
labelColumnName: nameof(ReviewData.Label), // 标签列名
numberOfIterations: 10, // 迭代次数
learningRate: 1.0f, // 学习率
featureColumnName: "Features")) // 特征列名
// 添加概率校准器
.Append(mlContext.BinaryClassification.Calibrators.Platt());
// 训练模型
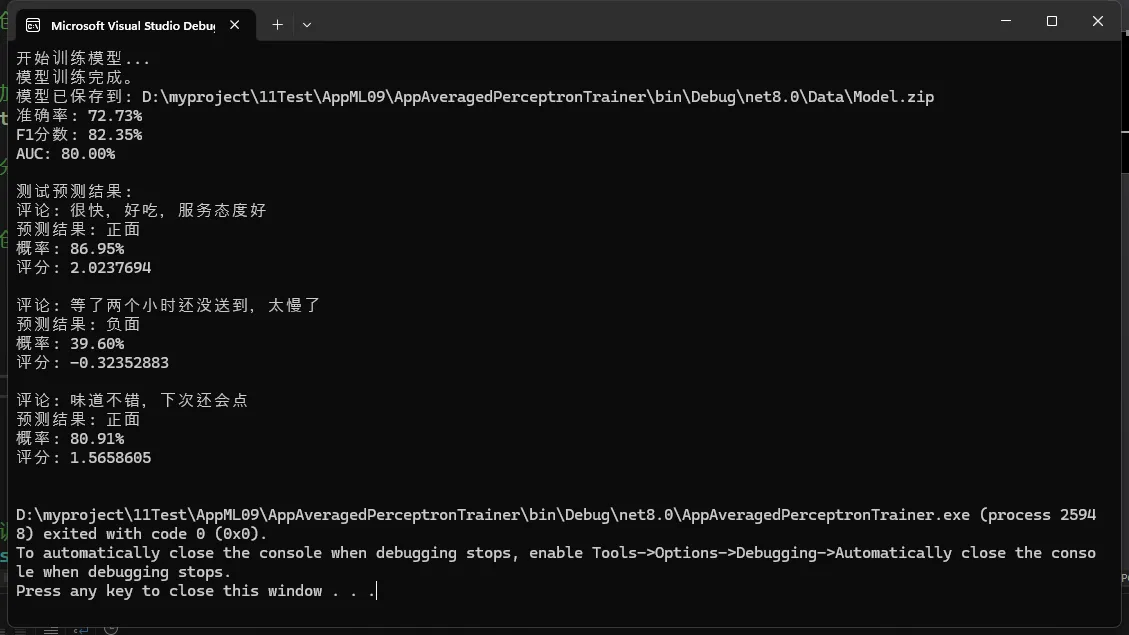
Console.WriteLine("开始训练模型...");
var model = pipeline.Fit(trainTestData.TrainSet);
Console.WriteLine("模型训练完成。");
// 保存模型
mlContext.Model.Save(model, dataView.Schema, _modelPath);
Console.WriteLine($"模型已保存到: {_modelPath}");
// 评估模型
var predictions = model.Transform(trainTestData.TestSet);
var metrics = mlContext.BinaryClassification.Evaluate(predictions);
Console.WriteLine($"准确率: {metrics.Accuracy:P2}");
Console.WriteLine($"F1分数: {metrics.F1Score:P2}");
Console.WriteLine($"AUC: {metrics.AreaUnderRocCurve:P2}");
// 使用模型进行预测
var predictionEngine = mlContext.Model.CreatePredictionEngine<ReviewData, ReviewPrediction>(model);
// 测试一些示例
var testReviews = new[]
{
"很快,好吃,服务态度好",
"等了两个小时还没送到,太慢了",
"味道不错,下次还会点"
};
Console.WriteLine("\n测试预测结果:");
foreach (var review in testReviews)
{
var prediction = predictionEngine.Predict(new ReviewData { Text = review });
Console.WriteLine($"评论: {review}");
Console.WriteLine($"预测结果: {(prediction.Prediction ? "正面" : "负面")}");
Console.WriteLine($"概率: {prediction.Probability:P2}");
Console.WriteLine($"评分: {prediction.Score}\n");
}
}
}
}
代码中的关键步骤如下:
- FeaturizeText:将文本转换为数字向量特征,为后续模型训练提供可计算的数值信息;
- AveragedPerceptronTrainer:核心训练器,通过多次迭代找到最优权重;
- 评估:使用 BinaryClassification.Evaluate 获取准确率、AUC、F1-Score 等指标;
- 预测:使用
PredictionEngine对新输入进行预测,并输出结果。
代码说明
numberOfIterations
numberOfIterations:10
- 用途:指定训练过程中的迭代次数
- 值类型:整数
- 默认值:10
- 影响:
- 较大值可能提高准确性但增加训练时间
- 较小值训练更快但可能影响性能
learningRate
learningRate:1.0f
- 用途:控制每次迭代时模型参数更新的步长
- 值类型:浮点数
- 默认值:1.0
- 特点:
- 较大的学习率:学习更快但可能不稳定
- 较小的学习率:学习更稳定但需要更多迭代
小结
- AveragedPerceptronTrainer 是感知器算法的改进版本,结合“平均”权重策略,在面对高维、稀疏数据时表现优秀。
- 能够快速迭代和调试,适合小规模实验或对训练速度有强需求的场景。
- 适用于文本分类、情感分析、垃圾邮件检测等常见的二元分类任务。
- 通过与 ML.NET 的多种文本与特征处理方法结合,可以快速构建端到端的机器学习应用。
- 数据不平衡:负面评论数量是正面评论尽量平衡,这可能会影响模型的预测偏向。
若你正在寻找一种兼具速度和可扩展性的线性算法来进行二元分类,别忘了试试 AveragedPerceptronTrainer。希望本文为你在 ML.NET 上更好地运用感知器算法提供了宝贵参考,让我们一起打造高效的 .NET 机器学习应用吧!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!