
目录
在二元分类任务中,如何高效并准确地对数据进行训练和预测,一直是开发者关注的焦点。SdcaNonCalibratedBinaryTrainer(以下简称 SDCA)是 ML.NET 提供的一种常用二元分类训练器,它能够快速收敛并处理大规模数据,具有非常高的实用价值。在本文中,我们将深入探讨该训练器的适用场景,并通过一个完整的 C# 代码示例来展示其使用方式。
什么是 SdcaNonCalibratedBinaryTrainer
SDCA 全称为 “Stochastic Dual Coordinate Ascent”,是一种迭代优化算法,通常用于大规模线性模型(如逻辑回归、支持向量机等)的训练。ML.NET 中的 SdcaNonCalibratedBinaryTrainer 专门针对二元分类任务,不会对预测结果进行后续校准(non-calibrated),与同系列的 SdcaLogisticRegressionBinaryTrainer(生成可解释的概率输出)相比,少了一步对输出进行概率校准的过程,因此在训练效率及预测速度上可能更具优势。
在一些场景下,我们对预测的输出并不需要转换成概率,只需要确定正例或负例即可,那么 SdcaNonCalibratedBinaryTrainer 可以说是一个快速且直接的二元分类选择。
适用场景
-
大规模、高维度特征数据
如果数据量很大、特征维度很高,SDCA 能够快速迭代,且相比于传统批量梯度下降,需要更少的内存占用。
-
对训练速度或者在线学习效率有较高要求
当需要频繁地更新模型或者进行快速迭代时,SDCA 的随机化策略可以更高效地处理数据,为快速收敛提供了良好支持。
-
不需要获取概率输出,但需要高判别准确率
在某些任务中,如简单的垃圾邮件检测、“是否合格”检查等场景,我们可能只需要一个明确结论:目标是正例还是负例,无需概率值。这时 SdcaNonCalibratedBinaryTrainer 提供的结果已经足够。
-
线上实时推断对速度要求较高
因为缺少了概率校准阶段,SdcaNonCalibratedBinaryTrainer 具有更快的推理速度。在实时决策场景中,减少推断时间有较大帮助。
工作原理概述
SDCA 基于随机梯度下降的对偶形式原理来优化目标函数。它会在小批量数据或单样本数据的基础上进行迭代,每次更新模型参数时,都只需要处理当前的小批量数据。对偶坐标使得其能够在高维数据中高效地收敛,让 SdcaNonCalibratedBinaryTrainer 能够在实际开发场景中游刃有余。
示例项目:使用 SdcaNonCalibratedBinaryTrainer 进行二元分类
下面,我们通过一个完整的 C# 代码示例来展示 SDCA 如何应用到常见的二元分类场景。本示例使用了一个伪造的“是否垃圾邮件”数据集,并给出了完整的中文注释,帮助大家更好地理解使用方式。
C#using System;
using System.IO;
using System.Linq;
using Microsoft.ML;
using Microsoft.ML.Data;
namespace SpamDetectionApp
{
// 定义输入数据模型
public class SpamInput
{
[LoadColumn(0)]
public string RawLabel { get; set; }
[LoadColumn(1)]
public string Message { get; set; }
}
// 定义输出数据模型
public class SpamOutput
{
public string RawLabel { get; set; }
public string Message { get; set; }
public bool Label { get; set; }
}
// 预测结果模型
public class SpamPrediction
{
[ColumnName("PredictedLabel")]
public bool Prediction { get; set; }
public float Score { get; set; }
}
class Program
{
static void Main(string[] args)
{
try
{
// 创建机器学习上下文
var mlContext = new MLContext(seed: 0);
// 加载和预处理数据
var data = LoadAndPrepareData(mlContext, "spam.csv");
// 数据分割
var splitData = mlContext.Data.TrainTestSplit(data, testFraction: 0.2);
// 构建训练管道
var pipeline = BuildTrainingPipeline(mlContext);
// 训练模型
var model = pipeline.Fit(splitData.TrainSet);
// 进行预测
var predictions = model.Transform(splitData.TestSet);
// 评估模型
var metrics = mlContext.BinaryClassification.Evaluate(
predictions,
labelColumnName: "Label",
scoreColumnName: "Score"
);
// 打印模型指标
PrintMetrics(metrics);
// 保存模型
SaveModel(mlContext, model, splitData.TrainSet);
}
catch (Exception ex)
{
Console.WriteLine($"发生错误: {ex.Message}");
Console.WriteLine($"详细错误信息: {ex.StackTrace}");
}
}
static IDataView LoadAndPrepareData(MLContext mlContext, string dataPath)
{
// 加载数据
var rawData = mlContext.Data.LoadFromTextFile<SpamInput>(
path: dataPath,
hasHeader: true,
separatorChar: ','
);
// 打印原始数据架构
Console.WriteLine("原始数据架构:");
foreach (var column in rawData.Schema)
{
Console.WriteLine($"{column.Name} - {column.Type}");
}
// 数据转换管道
var dataProcessingPipeline = mlContext.Transforms.CustomMapping<SpamInput, SpamOutput>(
(SpamInput input, SpamOutput output) =>
{
output.RawLabel = input.RawLabel;
output.Message = input.Message;
output.Label = input.RawLabel.ToLower() == "spam";
},
contractName: "LabelTransform")
.Append(mlContext.Transforms.Text.FeaturizeText(
outputColumnName: "Features",
inputColumnName: nameof(SpamOutput.Message)
));
// 应用数据转换
var processedData = dataProcessingPipeline.Fit(rawData).Transform(rawData);
// 打印处理后的数据架构
Console.WriteLine("\n处理后的数据架构:");
foreach (var column in processedData.Schema)
{
Console.WriteLine($"{column.Name} - {column.Type}");
}
return processedData;
}
static IEstimator<ITransformer> BuildTrainingPipeline(MLContext mlContext)
{
// 构建训练管道
var pipeline = mlContext.Transforms.Text.FeaturizeText(
outputColumnName: "Features",
inputColumnName: nameof(SpamOutput.Message)
)
.Append(mlContext.BinaryClassification.Trainers.SdcaNonCalibrated(
labelColumnName: "Label",
featureColumnName: "Features"
))
// 使用 Platt 校准器
.Append(mlContext.BinaryClassification.Calibrators.Platt());
return pipeline;
}
static void PrintMetrics(BinaryClassificationMetrics metrics)
{
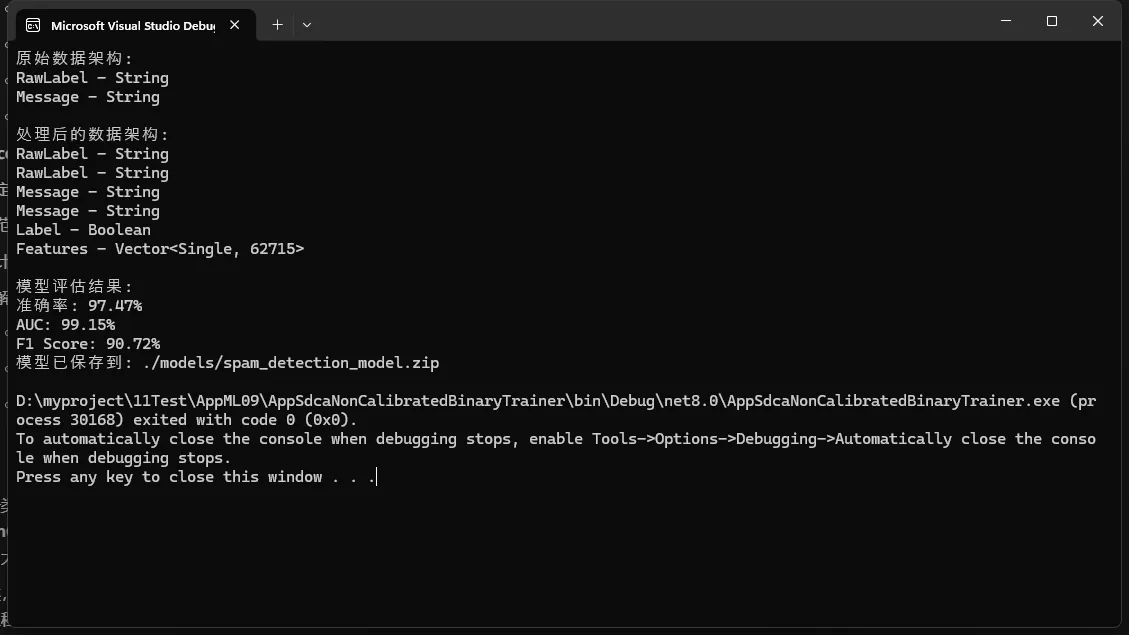
Console.WriteLine("\n模型评估结果:");
Console.WriteLine($"准确率: {metrics.Accuracy:P2}");
Console.WriteLine($"AUC: {metrics.AreaUnderRocCurve:P2}");
Console.WriteLine($"F1 Score: {metrics.F1Score:P2}");
}
static void SaveModel(MLContext mlContext, ITransformer model, IDataView trainData)
{
// 确保模型目录存在
Directory.CreateDirectory("./models");
// 保存模型
var modelPath = "./models/spam_detection_model.zip";
mlContext.Model.Save(model, trainData.Schema, modelPath);
Console.WriteLine($"模型已保存到: {modelPath}");
}
}
}
详细解释:
- 准确率 (Accuracy)
- 定义:正确预测的样本数 / 总样本数
- 范围:0-1(或0%-100%)
- 解释:模型正确分类的总体比例
- 局限性:在不平衡数据集中可能会产生误导
- AUC (Area Under the ROC Curve)
- 全称:Receiver Operating Characteristic曲线下面积
- 范围:0-1(或0%-100%)
- 解释:
- 衡量模型区分两个类别的能力
- 1.0 = 完美分类
- 0.5 = 随机猜测
- 0.7 通常被认为是可接受的
- 0.8 被认为是良好的
- 0.9 被认为是极好的
- F1 Score
- 定义:精确率和召回率的调和平均数
- 范围:0-1(或0%-100%)
- 计算公式:2 * (精确率 * 召回率) / (精确率 + 召回率)
- 解释:
- 平衡了精确率和召回率
- 在正负样本不平衡时特别有用
- 1.0 = 完美分类
总结
在二元分类任务中,如果对训练效率、推断速度要求较高,而不需要对输出进行概率校准,那么 SdcaNonCalibratedBinaryTrainer 就是一个非常理想的选择。它基于高效的随机对偶坐标下降算法,能在高维、大规模数据集中迅速收敛,并且推断时无需额外的后处理操作,速度相对更快。
综上所述,SdcaNonCalibratedBinaryTrainer 尤其适用于大规模二元分类场景,它既保留了准确率,又提升了工程速度与资源利用率。如果你在项目中需要对目标进行“是/否”判定,或者想要快速得到模型结果,那么 SDCA 训练器绝对是值得尝试的利器。期待你在实际项目中灵活使用它,为你的二元分类场景带来更高效率与更好表现。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!