
Press Ctrl+ and K to search
目录
在Python开发中,列表(list)无疑是最常用的数据结构之一。无论你是在开发桌面应用、数据分析工具,还是上位机系统,都离不开对列表的熟练操作。
很多初学者虽然会基本的列表使用,但往往不了解列表的高级特性和性能优化技巧,导致代码效率低下。更有甚者,在处理大量数据时因为不当的列表操作而造成程序卡顿。
本文将从实战角度出发,系统性地介绍Python列表的操作与方法,包括基础操作、进阶技巧和性能优化,帮助你在实际项目中写出更优雅、更高效的代码。
🔍 问题分析
在Windows平台的Python开发中,我们经常遇到以下列表操作难题:
- 数据处理效率低:不知道如何选择合适的列表方法
- 内存占用过大:列表操作不当导致内存泄漏
- 代码可读性差:复杂的列表操作逻辑混乱
💡 解决方案
🚀 基础操作篇
列表创建与初始化
Python# 基础创建方式
numbers = [1, 2, 3, 4, 5]
mixed_list = [1, "hello", 3.14, True]
# 高效初始化技巧
# 创建指定长度的零列表
zeros = [0] * 10
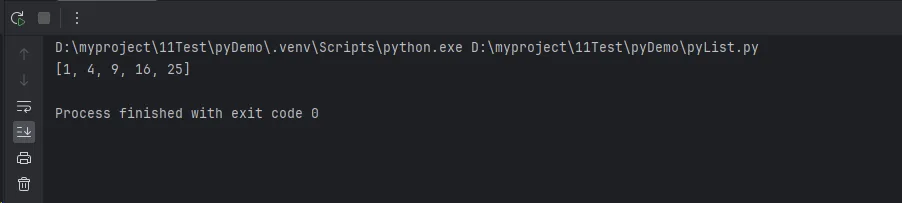
# 使用列表推导式创建
squares = [x**2 for x in range(1, 6)]
print(squares)
# 创建二维列表(注意深拷贝)
matrix = [[0 for _ in range(3)] for _ in range(3)]
元素访问与切片
Pythondata = [10, 20, 30, 40, 50]
# 基础访问
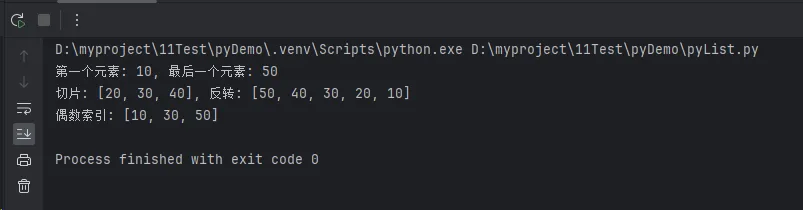
first = data[0]
last = data[-1]
print(f"第一个元素: {first}, 最后一个元素: {last}")
# 切片操作详解
subset = data[1:4]
reverse = data[::-1]
print(f"切片: {subset}, 反转: {reverse}")
# 步长切片
even_indices = data[::2]
print(f"偶数索引: {even_indices}")
🔥 核心方法详解
增删改查操作
Python# 添加元素的多种方式
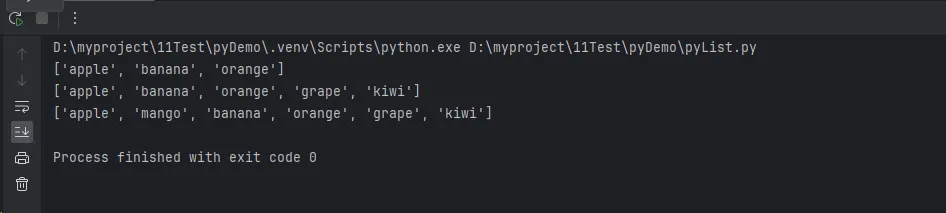
fruits = ['apple', 'banana']
# append() - 末尾添加单个元素
fruits.append('orange')
print(fruits)
# extend() - 添加多个元素
fruits.extend(['grape', 'kiwi'])
print(fruits)
# insert() - 指定位置插入
fruits.insert(1, 'mango')
print(fruits)
# 删除元素的几种方法
# remove() - 删除第一个匹配值
fruits.remove('banana')
# pop() - 删除并返回指定位置元素
removed = fruits.pop(0) # 删除第一个元素
# del - 删除指定位置或切片
del fruits[1:3]
# clear() - 清空列表
fruits.clear()
查找与统计方法
Pythonnumbers = [1, 2, 3, 2, 4, 2, 5]
# index() - 查找元素索引
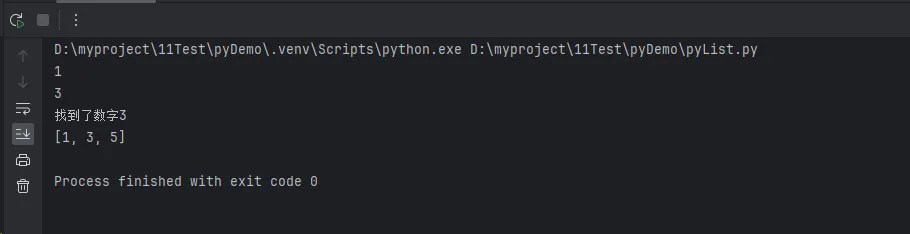
first_two_index = numbers.index(2)
print(first_two_index)
# count() - 统计元素出现次数
two_count = numbers.count(2)
print(two_count)
# 检查元素是否存在
if 3 in numbers:
print("找到了数字3")
# 实用技巧:查找所有匹配位置
def find_all_indices(lst, target):
return [i for i, x in enumerate(lst) if x == target]
all_two_indices = find_all_indices(numbers, 2)
print(all_two_indices)
🎯 排序与反转操作
Pythondata = [3, 1, 4, 1, 5, 9, 2, 6]
# sort() - 原地排序
data.sort()
print(data)
# 降序排序
data.sort(reverse=True)
# sorted() - 返回新列表
original = [3, 1, 4, 1, 5]
sorted_data = sorted(original)
print(original)
print(sorted_data)
# 自定义排序规则
students = [('Alice', 85), ('Bob', 90), ('Charlie', 78)]
students.sort(key=lambda x: x[1], reverse=True) # 按分数降序
print(students)
# reverse() - 反转列表
numbers = [1, 2, 3, 4, 5]
numbers.reverse()
print(numbers)
🔧 代码实战
💻 实战案例1:数据清洗工具
Pythondef clean_data_list(raw_data):
"""
清洗数据列表,去除空值和重复项
适用于上位机开发中的传感器数据处理
"""
# 去除空值和None
cleaned = [item for item in raw_data if item is not None and str(item).strip()]
# 去除重复项并保持原顺序
seen = set()
result = []
for item in cleaned:
if item not in seen:
seen.add(item)
result.append(item)
return result
# 使用示例
sensor_data = [12.5, None, 13.2, '', 12.5, 14.1, None, 15.0]
clean_data = clean_data_list(sensor_data)
print(clean_data)
💻 实战案例2:分页数据处理
Pythondef paginate_list(data_list, page_size=10):
"""
将大列表分页处理,适用于UI界面数据展示
"""
pages = []
for i in range(0, len(data_list), page_size):
page = data_list[i:i + page_size]
pages.append(page)
return pages
# 使用示例
large_dataset = list(range(1, 156)) # 155个数据
paginated = paginate_list(large_dataset, page_size=20)
print(f"总共分为 {len(paginated)} 页")
print(f"第一页数据: {paginated[0]}")
💻 实战案例3:数据统计分析
Pythondef analyze_list_data(numbers):
"""
对数值列表进行统计分析
返回常用的统计指标
"""
if not numbers:
return None
analysis = {
'count': len(numbers),
'sum': sum(numbers),
'average': sum(numbers) / len(numbers),
'max': max(numbers),
'min': min(numbers),
'median': sorted(numbers)[len(numbers) // 2],
'unique_count': len(set(numbers))
}
return analysis
# 使用示例
test_scores = [85, 92, 78, 96, 88, 79, 93, 87, 84, 90]
stats = analyze_list_data(test_scores)
for key, value in stats.items():
print(f"{key}: {value}")
🚀 性能优化技巧
列表推导式 vs 循环
Pythonimport time
# 方法1:传统循环
def create_squares_loop(n):
result = []
for i in range(n):
result.append(i ** 2)
return result
# 方法2:列表推导式
def create_squares_comprehension(n):
return [i ** 2 for i in range(n)]
# 性能测试
n = 100000
start = time.time()
squares1 = create_squares_loop(n)
time1 = time.time() - start
start = time.time()
squares2 = create_squares_comprehension(n)
time2 = time.time() - start
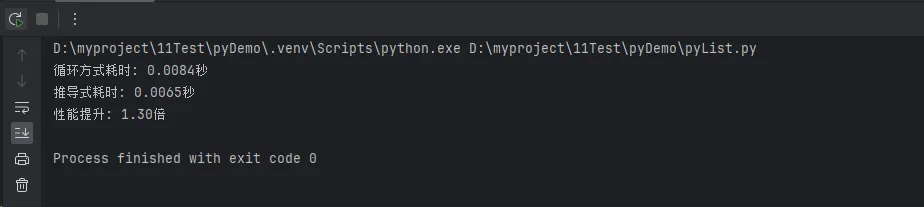
print(f"循环方式耗时: {time1:.4f}秒")
print(f"推导式耗时: {time2:.4f}秒")
print(f"性能提升: {time1/time2:.2f}倍")
合理使用内置函数
Python# 寻找最大值位置 - 高效方法
def find_max_index_efficient(lst):
return lst.index(max(lst))
# 批量操作优化
def batch_operation(data_list, operation):
"""
批量操作优化,避免频繁的列表操作
"""
# 使用map进行批量处理
return list(map(operation, data_list))
# 示例
numbers = [1, 2, 3, 4, 5]
doubled = batch_operation(numbers, lambda x: x * 2)
indexed_doubled = find_max_index_efficient(numbers)
print(doubled)
print(indexed_doubled)

📊 实际应用场景
Windows应用开发中的列表应用
Pythonclass DataBuffer:
"""
用于Windows应用的数据缓冲区管理
适用于实时数据采集和显示
"""
def __init__(self, max_size=1000):
self.buffer = []
self.max_size = max_size
def add_data(self, data):
"""添加数据,超过最大长度时自动删除旧数据"""
self.buffer.append(data)
if len(self.buffer) > self.max_size:
self.buffer.pop(0) # 删除最老的数据
def get_recent_data(self, count=10):
"""获取最近的数据"""
return self.buffer[-count:] if len(self.buffer) >= count else self.buffer
def get_average(self):
"""计算平均值"""
return sum(self.buffer) / len(self.buffer) if self.buffer else 0
# 使用示例
sensor_buffer = DataBuffer(max_size=100)
for i in range(150):
sensor_buffer.add_data(i)
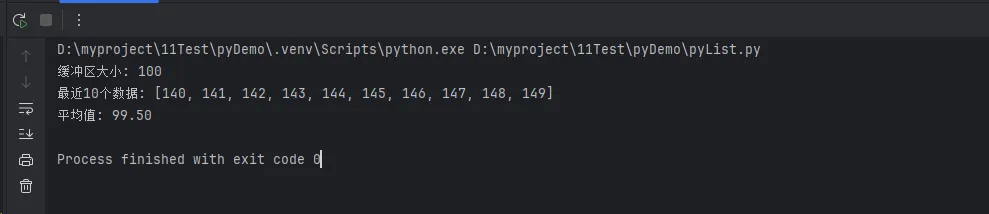
print(f"缓冲区大小: {len(sensor_buffer.buffer)}")
print(f"最近10个数据: {sensor_buffer.get_recent_data(10)}")
print(f"平均值: {sensor_buffer.get_average():.2f}")
⚡ 高级特性与技巧
列表解包与合并
Python# 列表解包
def print_items(*items):
for item in items:
print(item)
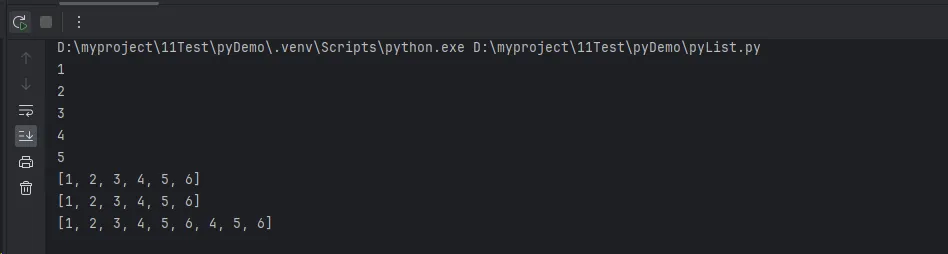
my_list = [1, 2, 3, 4, 5]
print_items(*my_list) # 解包列表作为参数
# 列表合并的多种方式
list1 = [1, 2, 3]
list2 = [4, 5, 6]
# 方式1:+ 操作符
merged1 = list1 + list2
print(merged1)
# 方式2:extend方法
list1.extend(list2)
print(list1)
# 方式3:解包合并
merged2 = [*list1, *list2]
print(merged2)
# 方式4:itertools.chain(大列表推荐)
import itertools
merged3 = list(itertools.chain(list1, list2))
条件筛选与转换
Python# 复杂条件筛选
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 筛选偶数并平方
even_squares = [x**2 for x in data if x % 2 == 0]
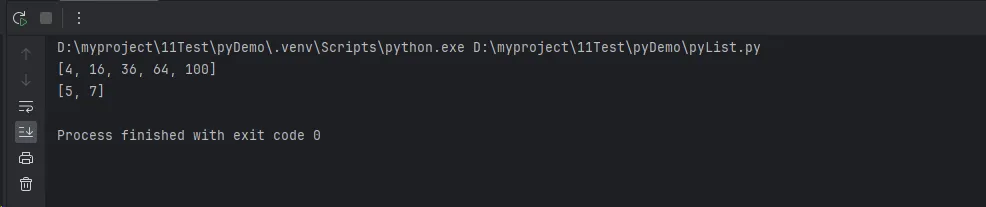
print(even_squares)
# 使用filter和map
filtered_data = list(filter(lambda x: x % 2 == 0, data))
squared_data = list(map(lambda x: x**2, filtered_data))
# 多条件筛选
def complex_filter(lst):
return [x for x in lst if x > 3 and x < 8 and x % 2 == 1]
result = complex_filter(data)
print(result)
🐛 常见陷阱与解决方案
浅拷贝问题
Python# 错误示例
matrix = [[0] * 3] * 3 # 这是浅拷贝!
matrix[0][0] = 1
print(matrix) # 所有行都被修改
# 正确方式
matrix = [[0 for _ in range(3)] for _ in range(3)]
matrix[0][0] = 1
print(matrix) # 只修改第一行

遍历时修改列表
Python# 错误示例
numbers = [1, 2, 3, 4, 5]
for i, num in enumerate(numbers):
if num % 2 == 0:
numbers.remove(num) # 这会导致索引错乱
# 正确方式1:逆向遍历
numbers = [1, 2, 3, 4, 5]
for i in reversed(range(len(numbers))):
if numbers[i] % 2 == 0:
numbers.pop(i)
# 正确方式2:创建新列表
numbers = [1, 2, 3, 4, 5]
numbers = [num for num in numbers if num % 2 != 0]
📈 性能对比与最佳实践
内存效率对比
Pythonimport sys
# 不同数据结构的内存占用
def memory_comparison():
# 列表
list_data = [i for i in range(1000)]
list_size = sys.getsizeof(list_data)
# 元组(只读场景)
tuple_data = tuple(range(1000))
tuple_size = sys.getsizeof(tuple_data)
print(f"列表内存占用: {list_size} bytes")
print(f"元组内存占用: {tuple_size} bytes")
print(f"元组节省: {((list_size - tuple_size) / list_size * 100):.1f}%")
memory_comparison()

🎯 总结要点
通过本文的详细介绍,我们系统性地掌握了Python列表操作的精髓。三个核心要点需要牢记:
1. 选择合适的方法:不同场景下选择最优的列表操作方法,比如大数据量时使用列表推导式而非传统循环,需要频繁插入删除时考虑使用deque等。
2. 注意性能陷阱:避免在循环中修改列表、合理使用浅拷贝和深拷贝、善用内置函数提升效率,这些细节往往决定了程序的运行效率。
3. 实战应用导向:将列表操作与实际的Windows应用开发、上位机编程需求相结合,比如数据缓冲区管理、分页处理等,让技术真正服务于项目需求。
掌握这些列表操作技巧,不仅能让你的Python开发更加高效,还能在处理复杂数据结构时游刃有余。继续深入学习字典、集合等其他数据结构,将为你的编程技巧添砖加瓦!
想了解更多Python编程技巧?关注我们,获取更多实用的Windows平台Python开发经验分享!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录