
目录
你是否在Python开发中遇到过这样的困惑:什么时候该用列表,什么时候该用元组?元组看似简单,但在实际的上位机开发和数据处理项目中,它却承担着重要角色。很多开发者只知道元组"不可变",却不知道如何充分利用这一特性来提升程序性能和代码质量。
本文将从实战角度深入剖析元组的核心特性,通过具体的Windows应用开发场景,带你掌握元组在配置管理、数据传递、性能优化等方面的最佳实践。无论你是Python初学者还是有经验的开发者,都能从中获得实用的编程技巧。
🔍 问题分析:为什么元组如此重要?
📊 性能对比实测
在Python开发中,数据结构的选择直接影响程序性能。让我们通过实际测试来看看元组的优势:
Pythonimport timeit
import sys
# 创建包含相同数据的列表和元组
list_data = [1, 2, 3, 4, 5] * 1000
tuple_data = tuple(list_data)
# 内存占用对比
print(f"列表内存占用: {sys.getsizeof(list_data)} 字节")
print(f"元组内存占用: {sys.getsizeof(tuple_data)} 字节")
# 访问速度对比
list_time = timeit.timeit(lambda: list_data[2500], number=1000000)
tuple_time = timeit.timeit(lambda: tuple_data[2500], number=1000000)
print(f"列表访问时间: {list_time:.6f}秒")
print(f"元组访问时间: {tuple_time:.6f}秒")

实测结果显示:元组在内存占用优于列表,这为我们的应用选择提供了数据支撑。
💡 解决方案:元组的核心特性详解
🔒 不可变性的威力
元组的不可变特性不仅仅是限制,更是数据安全的保障。在上位机开发中,这一特性尤为重要:
Python# 配置参数管理示例
class DeviceConfig:
def __init__(self):
# 使用元组存储不应被修改的核心配置
self._serial_params = (
9600, # 波特率
8, # 数据位
1, # 停止位
'N' # 校验位
)
# 设备坐标(生产环境中不应随意修改)
self._device_position = (100.5, 200.3, 50.0)
@property
def serial_config(self):
"""获取串口配置,返回元组确保不被意外修改"""
return self._serial_params
@property
def position(self):
"""获取设备位置坐标"""
return self._device_position
# 使用示例
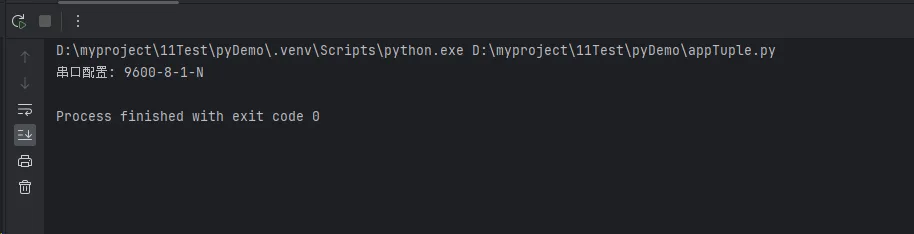
config = DeviceConfig()
baud_rate, data_bits, stop_bits, parity = config.serial_config
print(f"串口配置: {baud_rate}-{data_bits}-{stop_bits}-{parity}")
🎯 作为字典键的应用
元组可哈希的特性使其成为复合键的完美选择:
Python# 设备状态监控系统
device_status = {}
# 使用元组作为复合键:(设备ID, 传感器类型)
device_status[('device_001', 'temperature')] = 25.6
device_status[('device_001', 'humidity')] = 60.2
device_status[('device_002', 'temperature')] = 23.8
def get_sensor_value(device_id, sensor_type):
"""获取指定设备的传感器数值"""
key = (device_id, sensor_type)
return device_status.get(key, "传感器数据不存在")
# 查询示例
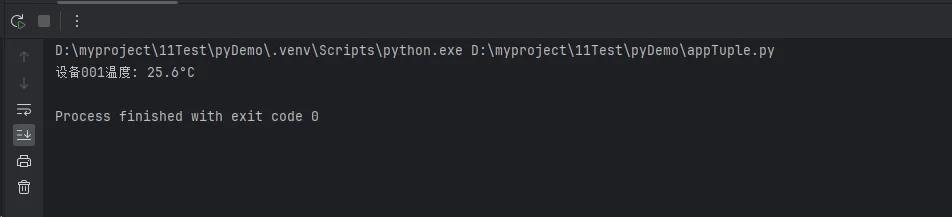
temp = get_sensor_value('device_001', 'temperature')
print(f"设备001温度: {temp}°C")
🔧 代码实战:元组在实际项目中的应用
🏭 场景一:工厂生产线数据处理
在工业自动化项目中,元组常用于表示不变的产品规格和生产参数:
Pythonclass ProductionLine:
def __init__(self):
# 产品规格元组:(长度, 宽度, 高度, 重量)
self.product_specs = {
'A型': (120.0, 80.0, 15.0, 2.5),
'B型': (150.0, 90.0, 20.0, 3.2),
'C型': (100.0, 70.0, 12.0, 1.8)
}
# 生产工艺参数:(温度, 压力, 时间, 速度)
self.process_params = (
(180, 2.5, 300, 1.2), # 工艺1
(200, 3.0, 250, 1.5), # 工艺2
(160, 2.0, 350, 1.0) # 工艺3
)
def check_product_quality(self, product_type, measured_values):
"""产品质量检测"""
if product_type not in self.product_specs:
return False, "未知产品类型"
# 获取标准规格
length, width, height, weight = self.product_specs[product_type]
m_length, m_width, m_height, m_weight = measured_values
# 允许误差范围 ±5%
tolerance = 0.05
checks = [
abs(m_length - length) / length <= tolerance,
abs(m_width - width) / width <= tolerance,
abs(m_height - height) / height <= tolerance,
abs(m_weight - weight) / weight <= tolerance
]
if all(checks):
return True, "产品合格"
else:
return False, "产品不合格"
def get_optimal_process(self, product_type):
"""根据产品类型获取最优工艺参数"""
type_index = {'A型': 0, 'B型': 1, 'C型': 2}
if product_type in type_index:
return self.process_params[type_index[product_type]]
return None
# 使用示例
production = ProductionLine()
# 产品质量检测
measured = (119.5, 81.2, 14.8, 2.48) # 实际测量值
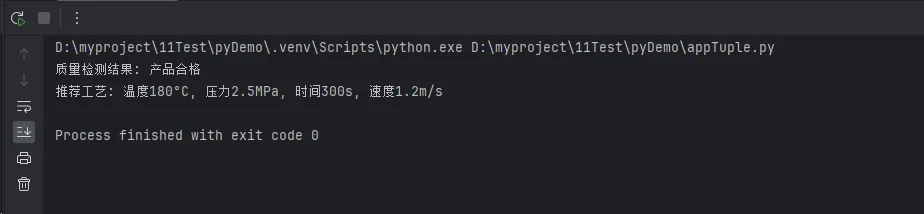
is_qualified, message = production.check_product_quality('A型', measured)
print(f"质量检测结果: {message}")
# 获取工艺参数
temp, pressure, time, speed = production.get_optimal_process('A型')
print(f"推荐工艺: 温度{temp}°C, 压力{pressure}MPa, 时间{time}s, 速度{speed}m/s")
📊 场景二:数据库连接池管理
在Windows应用开发中,数据库连接池是常见需求。元组可以优雅地管理连接参数:
Pythonimport sqlite3
from threading import Lock
from typing import Tuple, Optional
class DatabasePool:
def __init__(self):
# 数据库配置元组:(路径, 超时, 最大连接数)
self._db_configs = (
r"main.db", # 主数据库
r"backup.db", # 备份数据库
r"temp.db" # 临时数据库
)
# 连接参数元组:(超时时间, 最大重试次数, 缓存大小)
self._connection_params = (30, 3, 1000)
self._connections = []
self._lock = Lock()
def create_connection(self, db_index: int = 0) -> Optional[sqlite3.Connection]:
"""创建数据库连接"""
if 0 <= db_index < len(self._db_configs):
db_path = self._db_configs[db_index]
timeout, max_retries, cache_size = self._connection_params
try:
conn = sqlite3.connect(
db_path,
timeout=timeout,
check_same_thread=False
)
# 设置缓存大小
conn.execute(f'PRAGMA cache_size = {cache_size}')
return conn
except sqlite3.Error as e:
print(f"数据库连接失败: {e}")
return None
return None
def get_db_info(self) -> Tuple[str, ...]:
"""获取数据库配置信息"""
return self._db_configs
def batch_execute(self, sql_list: list, db_index: int = 0):
"""批量执行SQL语句"""
conn = self.create_connection(db_index)
if not conn:
return False
try:
with conn:
for sql, params in sql_list:
if isinstance(params, tuple):
conn.execute(sql, params)
else:
conn.execute(sql, (params,))
return True
except sqlite3.Error as e:
print(f"批量执行失败: {e}")
return False
finally:
conn.close()
# 使用示例
db_pool = DatabasePool()
# 先创建表
create_table_sql = '''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
age INTEGER NOT NULL,
city TEXT NOT NULL
)
'''
db_pool.batch_execute([(create_table_sql, ())])
# 再插入数据
insert_data = [
("INSERT INTO users (name, age, city) VALUES (?, ?, ?)", ('张三', 25, '北京')),
("INSERT INTO users (name, age, city) VALUES (?, ?, ?)", ('李四', 30, '上海')),
("INSERT INTO users (name, age, city) VALUES (?, ?, ?)", ('王五', 28, '深圳'))
]
success = db_pool.batch_execute(insert_data)
print(f"数据插入{'成功' if success else '失败'}")
🔄 场景三:多返回值函数设计
Python函数返回多个值时实际返回的是元组,合理利用这一特性可以让代码更清晰:
Pythonimport math
from typing import Tuple
class GeometryCalculator:
"""几何计算器 - 展示元组在多返回值中的应用"""
@staticmethod
def circle_properties(radius: float) -> Tuple[float, float, float]:
"""计算圆的属性:直径、周长、面积"""
diameter = 2 * radius
circumference = 2 * math.pi * radius
area = math.pi * radius ** 2
return diameter, circumference, area
@staticmethod
def rectangle_analysis(length: float, width: float) -> Tuple[float, float, float, Tuple[float, float]]:
"""矩形分析:周长、面积、对角线长度、中心点坐标"""
perimeter = 2 * (length + width)
area = length * width
diagonal = math.sqrt(length**2 + width**2)
center = (length/2, width/2) # 返回嵌套元组
return perimeter, area, diagonal, center
@staticmethod
def triangle_calculator(a: float, b: float, c: float) -> Tuple[bool, float, float]:
"""三角形计算:是否有效、周长、面积"""
# 检查三角形是否有效
is_valid = (a + b > c) and (a + c > b) and (b + c > a)
if not is_valid:
return False, 0.0, 0.0
perimeter = a + b + c
# 使用海伦公式计算面积
s = perimeter / 2
area = math.sqrt(s * (s-a) * (s-b) * (s-c))
return True, perimeter, area
# 实战应用示例
calc = GeometryCalculator()
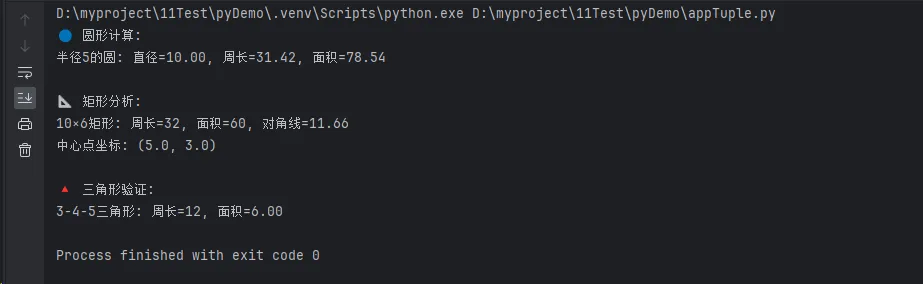
print("🔵 圆形计算:")
diameter, circumference, area = calc.circle_properties(5.0)
print(f"半径5的圆: 直径={diameter:.2f}, 周长={circumference:.2f}, 面积={area:.2f}")
print("\n📐 矩形分析:")
perimeter, area, diagonal, (center_x, center_y) = calc.rectangle_analysis(10, 6)
print(f"10×6矩形: 周长={perimeter}, 面积={area}, 对角线={diagonal:.2f}")
print(f"中心点坐标: ({center_x}, {center_y})")
print("\n🔺 三角形验证:")
valid, perimeter, area = calc.triangle_calculator(3, 4, 5)
if valid:
print(f"3-4-5三角形: 周长={perimeter}, 面积={area:.2f}")
else:
print("无效三角形")
⚡ 场景四:性能优化技巧
元组在特定场景下的性能优势可以显著提升程序效率:
Pythonimport time
from collections import namedtuple
# 定义命名元组,提高代码可读性
Point = namedtuple('Point', ['x', 'y', 'z'])
Color = namedtuple('Color', ['r', 'g', 'b', 'alpha'])
class PerformanceDemo:
"""性能优化示例"""
def __init__(self):
# 预定义常用的元组,避免重复创建
self.ORIGIN = (0, 0, 0)
self.UNIT_X = (1, 0, 0)
self.UNIT_Y = (0, 1, 0)
self.UNIT_Z = (0, 0, 1)
# 颜色常量
self.COLORS = (
(255, 0, 0, 255), # 红色
(0, 255, 0, 255), # 绿色
(0, 0, 255, 255), # 蓝色
(255, 255, 255, 255) # 白色
)
def tuple_vs_list_creation(self, iterations=1000000):
"""对比元组和列表的创建速度"""
# 测试元组创建
start_time = time.time()
for _ in range(iterations):
data = (1, 2, 3, 4, 5)
tuple_time = time.time() - start_time
# 测试列表创建
start_time = time.time()
for _ in range(iterations):
data = [1, 2, 3, 4, 5]
list_time = time.time() - start_time
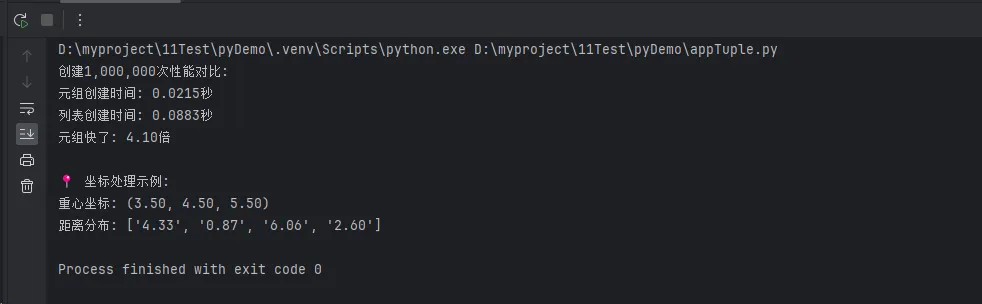
print(f"创建{iterations:,}次性能对比:")
print(f"元组创建时间: {tuple_time:.4f}秒")
print(f"列表创建时间: {list_time:.4f}秒")
print(f"元组快了: {list_time/tuple_time:.2f}倍")
def efficient_coordinate_processing(self, points_data):
"""高效的坐标数据处理"""
# 使用元组存储3D点,内存效率更高
points = [Point(x, y, z) for x, y, z in points_data]
# 计算所有点的重心
total_x = sum(p.x for p in points)
total_y = sum(p.y for p in points)
total_z = sum(p.z for p in points)
count = len(points)
centroid = Point(total_x/count, total_y/count, total_z/count)
# 计算每个点到重心的距离
distances = []
for point in points:
distance = (
(point.x - centroid.x) ** 2 +
(point.y - centroid.y) ** 2 +
(point.z - centroid.z) ** 2
) ** 0.5
distances.append(distance)
return centroid, tuple(distances) # 返回元组,不可变结果
# 性能测试示例
demo = PerformanceDemo()
demo.tuple_vs_list_creation()
print("\n📍 坐标处理示例:")
sample_points = [
(1.0, 2.0, 3.0),
(4.0, 5.0, 6.0),
(7.0, 8.0, 9.0),
(2.0, 3.0, 4.0)
]
centroid, distances = demo.efficient_coordinate_processing(sample_points)
print(f"重心坐标: ({centroid.x:.2f}, {centroid.y:.2f}, {centroid.z:.2f})")
print(f"距离分布: {[f'{d:.2f}' for d in distances]}")
🚀 高级应用:元组的进阶技巧
🎨 命名元组的妙用
命名元组结合了元组的性能和类的可读性:
Pythonfrom collections import namedtuple
from typing import List
# 定义设备信息结构
DeviceInfo = namedtuple('DeviceInfo', [
'device_id', 'name', 'ip_address', 'port',
'status', 'last_heartbeat'
])
# 定义传感器数据结构
SensorData = namedtuple('SensorData', [
'timestamp', 'device_id', 'sensor_type',
'value', 'unit', 'is_normal'
])
class IoTDeviceManager:
"""物联网设备管理器"""
def __init__(self):
self.devices: List[DeviceInfo] = []
self.sensor_history: List[SensorData] = []
def register_device(self, device_id: str, name: str,
ip: str, port: int) -> bool:
"""注册新设备"""
# 检查设备是否已存在
if any(dev.device_id == device_id for dev in self.devices):
return False
device = DeviceInfo(
device_id=device_id,
name=name,
ip_address=ip,
port=port,
status='offline',
last_heartbeat=None
)
self.devices.append(device)
return True
def update_device_status(self, device_id: str,
status: str, heartbeat_time: str):
"""更新设备状态 - 展示命名元组的_replace方法"""
for i, device in enumerate(self.devices):
if device.device_id == device_id:
# 使用_replace创建新的元组实例
updated_device = device._replace(
status=status,
last_heartbeat=heartbeat_time
)
self.devices[i] = updated_device
return True
return False
def get_device_summary(self) -> tuple:
"""获取设备状态摘要"""
online_count = sum(1 for dev in self.devices if dev.status == 'online')
offline_count = len(self.devices) - online_count
return (len(self.devices), online_count, offline_count)
# 使用示例
manager = IoTDeviceManager()
# 注册设备
manager.register_device('DEV001', '温度传感器1', '192.168.1.101', 8080)
manager.register_device('DEV002', '湿度传感器1', '192.168.1.102', 8080)
# 更新设备状态
manager.update_device_status('DEV001', 'online', '2024-03-15 10:30:00')
# 获取摘要信息
total, online, offline = manager.get_device_summary()
print(f"设备总数: {total}, 在线: {online}, 离线: {offline}")
# 访问命名元组的字段
for device in manager.devices:
print(f"设备: {device.name} ({device.device_id}) - {device.status}")

🏁 核心要点总结
通过本文的深入探讨,我们掌握了元组在Python开发中的强大应用。让我回顾三个核心要点:
🎯 性能优势明显:元组在内存占用和访问速度上都优于列表,在数据量大、频繁访问的场景下能带来显著的性能提升。特别是在上位机开发中处理实时数据时,这种优势尤为重要。
🔒 数据安全保障:元组的不可变特性为程序提供了天然的数据保护机制。在配置管理、常量定义、多线程环境下的数据共享等场景中,元组能有效防止意外修改,提高程序的稳定性。
🚀 代码优雅简洁:从多返回值函数到复合字典键,从命名元组到数据结构设计,元组让代码更加优雅和易维护。合理使用元组不仅能提升程序性能,更能体现专业的Python编程素养。
掌握这些元组的实战技巧,将让你在Python开发道路上更加得心应手。记住,选择合适的数据结构是优秀程序员的基本功,元组正是这个工具箱中不可或缺的利器。
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!