
Press Ctrl+ and K to search
目录
在Python开发中,字典(dict)是我们最常用的数据结构之一,无论是配置文件解析、数据缓存还是API响应处理,字典都扮演着重要角色。然而,很多开发者对字典的认知还停留在基础的增删改查上,错过了许多高效的操作技巧。
本文将从实战角度出发,系统梳理Python字典的核心操作方法,涵盖常用方法、性能优化技巧以及实际应用场景。无论你是Python新手还是有经验的开发者,都能从中获得有价值的编程技巧,让你的代码更加优雅高效。
🔍 问题分析:字典操作的常见痛点
📊 开发中的典型场景
在日常的Python开发工作中,我们经常遇到以下场景:
- 配置管理:需要灵活处理各种配置参数
- 数据转换:JSON数据与Python对象之间的转换
- 缓存优化:使用字典实现高效的数据缓存
- 统计分析:对数据进行分组统计和聚合操作
⚡ 性能瓶颈识别
许多开发者在使用字典时容易陷入以下误区:
- 频繁使用
if key in dict进行存在性检查 - 不合理的嵌套字典操作
- 缺乏对字典方法的深入理解,导致代码冗余
💡 解决方案:字典操作的核心方法详解
🏗️ 基础创建与初始化
Python# 多种创建方式
user_info = {} # 空字典,这种更习惯
user_info = dict() # 使用构造函数
# 字面量创建
config = {
'host': 'localhost',
'port': 3306,
'username': 'admin'
}
# 使用dict()构造函数
settings = dict(debug=True, timeout=30)
# 从键值对列表创建
pairs = [('name', 'Python'), ('version', '3.9')]
info = dict(pairs)
🔧 高效的访问与修改操作
get()方法:安全的键值获取
Pythonuser_info = {
'name': 'Alice',
'age': 25,
}
# 传统方式(容易出错)
if 'age' in user_info:
age = user_info['age']
else:
age = 18
# 推荐方式:使用get()
age = user_info.get('age', 18) # 提供默认值
email = user_info.get('email') # 返回None(如果不存在)
print(f"年龄: {age}")
print(f"邮箱: {email}")
setdefault():条件设置的利器
Python# 统计词频的经典应用
def count_words(text):
word_count = {}
for word in text.split():
word_count.setdefault(word, 0)
word_count[word] += 1
return word_count
# 更简洁的写法
def count_words_v2(text):
word_count = {}
for word in text.split():
word_count[word] = word_count.setdefault(word, 0) + 1
return word_count
print(count_words('this is test'))
print(count_words_v2('this is test'))
🔄 字典合并与更新技巧
update()方法的灵活应用
Python# 基础合并
base_config = {'host': 'localhost', 'port': 3306}
user_config = {'port': 5432, 'database': 'myapp'}
base_config.update(user_config)
print(base_config)
# 批量更新的实战场景
def merge_configurations(*configs):
"""合并多个配置字典"""
result = {}
for config in configs:
if isinstance(config, dict):
result.update(config)
return result
# 使用示例
default_config = {'timeout': 30, 'retries': 3}
env_config = {'timeout': 60}
user_config = {'debug': True}
final_config = merge_configurations(default_config, env_config, user_config)
print(final_config)
Python 3.9+的新特性:字典合并操作符
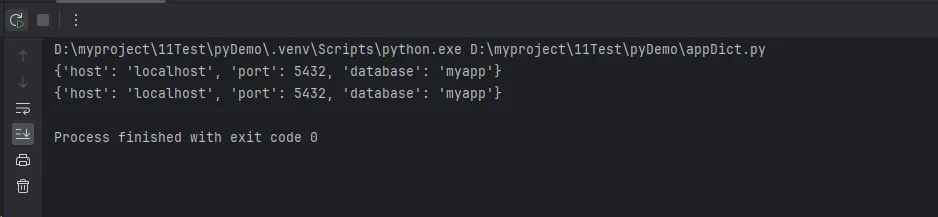
Python# 使用 | 操作符合并(Python 3.9+)
config1 = {'host': 'localhost', 'port': 3306}
config2 = {'port': 5432, 'database': 'myapp'}
merged_config = config1 | config2 # 创建新字典
print(merged_config)
# 使用 |= 操作符更新
config1 |= config2
print(config1)
🗑️ 删除操作的最佳实践
Pythonimport time
user_data = {'name': 'Alice', 'age': 25, 'temp_token': 'abc123'}
# 删除临时数据
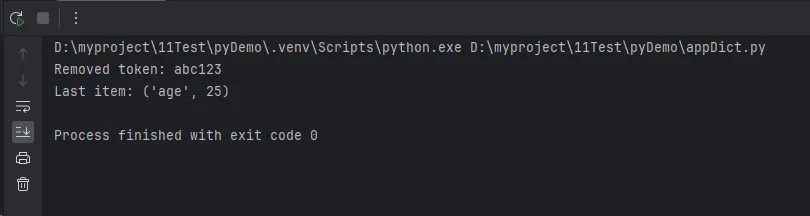
temp_token = user_data.pop('temp_token', None)
print(f"Removed token: {temp_token}")
# popitem():删除最后插入的键值对(Python 3.7+保证顺序)
last_item = user_data.popitem()
print(f"Last item: {last_item}")
# 实战:清理过期缓存
def cleanup_expired_cache(cache, expire_time):
expired_keys = []
current_time = time.time()
for key, (value, timestamp) in cache.items():
if current_time - timestamp > expire_time:
expired_keys.append(key)
for key in expired_keys:
cache.pop(key, None)
cache_data = {
'user1': ('Alice', time.time() - 7200), # 2小时前的数据
'user2': ('Bob', time.time() - 1800), # 30分钟前的数据
'user3': ('Charlie', time.time()), # 刚刚的数据
}
cleanup_expired_cache(cache_data, 3600)
🔍 字典视图与迭代优化
Python# 高效的字典遍历
data = {'a': 1, 'b': 2, 'c': 3}
# 遍历键值对(推荐)
for key, value in data.items():
print(f"{key}: {value}")
# 只遍历键
for key in data.keys():
print(key)
# 只遍历值
for value in data.values():
print(value)
# 实战:数据清洗
def clean_user_data(users):
"""清理用户数据中的空值"""
cleaned_users = {}
for user_id, user_info in users.items():
# 过滤空值
cleaned_info = {k: v for k, v in user_info.items() if v is not None}
if cleaned_info: # 只保留非空的用户信息
cleaned_users[user_id] = cleaned_info
return cleaned_users
users={
'u1': {'name': '张三', 'age': 25, 'city': '北京'},
'u2': {'name': '李四', 'age': None, 'city': '上海'},
'u3': {'name': None, 'age': 30, 'city': '广州'},
'u4': {'name': '王五', 'age': 28, 'city': None}
}
print(clean_user_data(users))
🚀 代码实战:字典在实际项目中的应用
📝 案例1:配置文件管理器
Pythonimport json
from pathlib import Path
class ConfigManager:
def __init__(self, config_file='config.json'):
self.config_file = Path(config_file)
self._config = {}
self.load_config()
def load_config(self):
"""加载配置文件"""
if self.config_file.exists():
with open(self.config_file, 'r', encoding='utf-8') as f:
self._config = json.load(f)
else:
self._config = self.get_default_config()
self.save_config()
def get_default_config(self):
"""获取默认配置"""
return {
'database': {
'host': 'localhost',
'port': 3306,
'name': 'myapp'
},
'app': {
'debug': False,
'timeout': 30
}
}
def get(self, key, default=None):
"""获取配置值,支持点号分隔的嵌套键"""
keys = key.split('.')
value = self._config
for k in keys:
if isinstance(value, dict) and k in value:
value = value[k]
else:
return default
return value
def set(self, key, value):
"""设置配置值"""
keys = key.split('.')
config = self._config
# 创建嵌套结构
for k in keys[:-1]:
config = config.setdefault(k, {})
config[keys[-1]] = value
self.save_config()
def save_config(self):
"""保存配置到文件"""
with open(self.config_file, 'w', encoding='utf-8') as f:
json.dump(self._config, f, indent=2, ensure_ascii=False)
# 使用示例
config = ConfigManager()
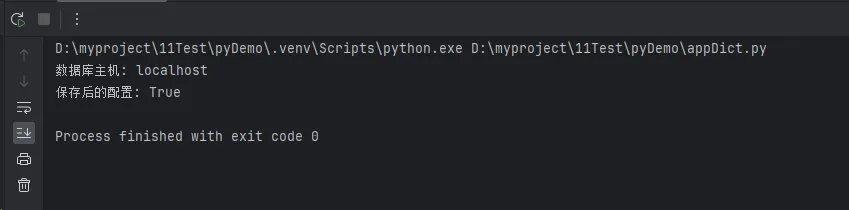
db_host = config.get('database.host', 'localhost')
print(f"数据库主机: {db_host}")
config.set('app.debug', True)
config.save_config()
print(f"保存后的配置: {config.get('app.debug')}")
📊 案例2:数据统计分析器
Pythonfrom collections import defaultdict, Counter
from datetime import datetime
class DataAnalyzer:
def __init__(self):
self.data = []
def add_record(self, **kwargs):
"""添加数据记录"""
record = {
'timestamp': datetime.now(),
**kwargs
}
self.data.append(record)
def group_by(self, field):
"""按字段分组"""
groups = defaultdict(list)
for record in self.data:
key = record.get(field)
if key is not None:
groups[key].append(record)
return dict(groups)
def count_by(self, field):
"""按字段统计数量"""
values = [record.get(field) for record in self.data if field in record]
return dict(Counter(values))
def aggregate(self, group_field, agg_field, func=sum):
"""聚合统计"""
groups = self.group_by(group_field)
result = {}
for group_key, records in groups.items():
values = [record.get(agg_field, 0) for record in records if agg_field in record]
if values:
result[group_key] = func(values)
return result
def top_n(self, field, n=10):
"""获取前N个最常见的值"""
counter = Counter(record.get(field) for record in self.data if field in record)
return counter.most_common(n)
# 使用示例
analyzer = DataAnalyzer()
# 添加销售数据
analyzer.add_record(product='iPhone', category='手机', amount=5999, quantity=2)
analyzer.add_record(product='MacBook', category='电脑', amount=12999, quantity=1)
analyzer.add_record(product='AirPods', category='耳机', amount=1999, quantity=3)
# 统计分析
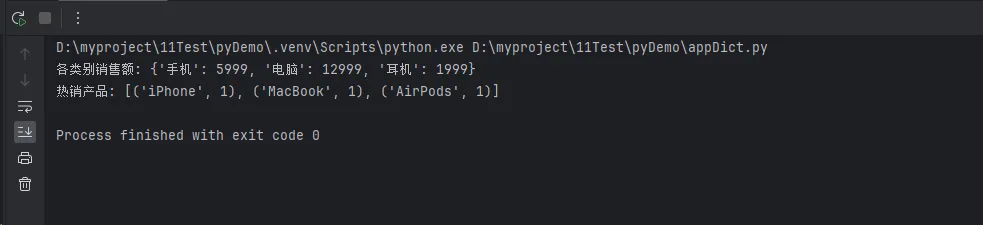
category_sales = analyzer.aggregate('category', 'amount', sum)
print(f"各类别销售额: {category_sales}")
top_products = analyzer.top_n('product', 5)
print(f"热销产品: {top_products}")
🎯 案例3:缓存装饰器
Pythonimport time
import functools
from typing import Any, Callable
class SmartCache:
def __init__(self, maxsize=128, ttl=300):
"""
智能缓存装饰器
:param maxsize: 最大缓存条目数
:param ttl: 生存时间(秒)
"""
self.maxsize = maxsize
self.ttl = ttl
self.cache = {}
self.access_times = {}
def __call__(self, func: Callable) -> Callable:
@functools.wraps(func)
def wrapper(*args, **kwargs):
# 生成缓存键
cache_key = self._make_key(args, kwargs)
current_time = time.time()
# 检查缓存是否存在且未过期
if cache_key in self.cache:
value, timestamp = self.cache[cache_key]
if current_time - timestamp < self.ttl:
self.access_times[cache_key] = current_time
return value
else:
# 过期,删除缓存
self.cache.pop(cache_key, None)
self.access_times.pop(cache_key, None)
# 执行函数并缓存结果
result = func(*args, **kwargs)
# 如果缓存已满,删除最久未使用的条目
if len(self.cache) >= self.maxsize:
self._evict_lru()
self.cache[cache_key] = (result, current_time)
self.access_times[cache_key] = current_time
return result
wrapper.cache_info = lambda: {
'cache_size': len(self.cache),
'max_size': self.maxsize,
'ttl': self.ttl
}
wrapper.clear_cache = lambda: self._clear()
return wrapper
def _make_key(self, args, kwargs):
"""生成缓存键"""
key_parts = []
key_parts.extend(str(arg) for arg in args)
key_parts.extend(f"{k}={v}" for k, v in sorted(kwargs.items()))
return "|".join(key_parts)
def _evict_lru(self):
"""删除最久未使用的缓存条目"""
if not self.access_times:
return
# 找到最久未访问的键
lru_key = min(self.access_times.keys(),
key=lambda k: self.access_times[k])
self.cache.pop(lru_key, None)
self.access_times.pop(lru_key, None)
def _clear(self):
"""清空缓存"""
self.cache.clear()
self.access_times.clear()
# 使用示例
@SmartCache(maxsize=100, ttl=60)
def expensive_calculation(x, y):
"""模拟耗时计算"""
time.sleep(1) # 模拟耗时操作
return x * y + x ** 2
# 测试缓存效果
start_time = time.time()
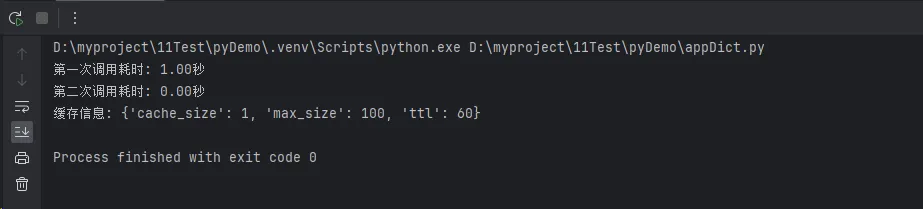
result1 = expensive_calculation(10, 20) # 首次调用,会执行计算
print(f"第一次调用耗时: {time.time() - start_time:.2f}秒")
start_time = time.time()
result2 = expensive_calculation(10, 20) # 第二次调用,从缓存获取
print(f"第二次调用耗时: {time.time() - start_time:.2f}秒")
print(f"缓存信息: {expensive_calculation.cache_info()}")
🔥 性能优化技巧
⚡ 字典推导式的高效应用
Python# 传统方式
result = {}
for i in range(1000):
if i % 2 == 0:
result[i] = i ** 2
# 字典推导式(更高效)
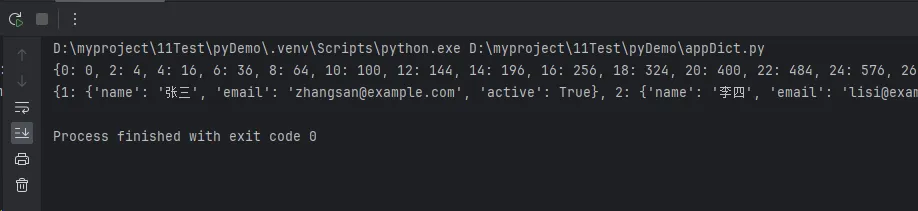
result = {i: i**2 for i in range(1000) if i % 2 == 0}
print(result)
# 实战:数据转换
def transform_user_data(users):
"""将用户列表转换为以ID为键的字典"""
return {user['id']: {
'name': user['name'],
'email': user.get('email', ''),
'active': user.get('status') == 'active'
} for user in users if 'id' in user}
users=[
{'id': 1, 'name': '张三', 'email': 'zhangsan@example.com', 'status': 'active'},
{'id': 2, 'name': '李四', 'email': 'lisi@example.com', 'status': 'inactive'},
{'id': 3, 'name': '王五', 'email': 'wangwu@example.com', 'status': 'active'},
{'id': 4, 'name': '赵六', 'status': 'active'},
{'id': 5, 'name': '孙七', 'email': ''}
]
print(transform_user_data(users))
🎯 使用defaultdict简化逻辑
Pythonfrom collections import defaultdict
# 传统分组方式
def group_by_category_old(products):
groups = {}
for product in products:
category = product['category']
if category not in groups:
groups[category] = []
groups[category].append(product)
return groups
# 使用defaultdict简化
def group_by_category_new(products):
groups = defaultdict(list)
for product in products:
groups[product['category']].append(product)
return dict(groups)
products=[
{'name': 'iPhone', 'category': '手机'},
{'name': 'MacBook', 'category': '电脑'},
{'name': 'iPad', 'category': '手机'},
{'name': 'AirPods', 'category': '音频'},
{'name': 'MacBook Pro', 'category': '电脑'},
{'name': 'MacBook Air', 'category': '电脑'},
{'name': 'MacBook Mini', 'category': '电脑'},
{'name': 'MacBook Pro', 'category': '电脑'},
]
groups = group_by_category_old(products)
print(groups)
groups = group_by_category_new(products)
print(groups)

🎯 总结:掌握字典操作的三个关键点
通过本文的深入探讨,我们可以将Python字典操作的精髓归纳为三个核心要点:
1. 安全访问是基础 - 始终使用get()方法和setdefault()来避免KeyError,编写更加健壮的代码。这不仅能提高程序的稳定性,还能让代码更加清晰易读。
2. 合理选择方法是关键 - 根据具体场景选择最适合的字典方法,如使用字典推导式提升性能,使用defaultdict简化分组逻辑,使用Counter进行统计分析。掌握这些工具能让你的Python开发效率大幅提升。
3. 实战应用是目标 - 字典不仅仅是数据容器,更是构建复杂应用的基石。无论是配置管理、数据缓存还是上位机开发中的状态管理,合理运用字典操作都能让你的项目更加优雅高效。
希望本文的编程技巧能帮助你在实际项目中写出更加Pythonic的代码,如果你有任何字典操作的疑问或想分享自己的实战经验,欢迎在评论区交流讨论!
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
目录