
🔐 先说一个真实的尴尬场景
我在给某制造企业做内部管理工具的时候,碰到过一件挺有意思的事。系统上线一个月后,仓库主管跑来找我,说有个操作员误操作把一批出库记录全删了。我去查日志——没有日志。再问是谁删的——没有权限限制,人人都能删。
那一刻我意识到,这个系统就是个"裸奔"的应用。
很多用Tkinter做内部工具的同学,往往把精力全放在功能实现上,权限这块儿要么完全忽略,要么就是在按钮的command里加个if username == "admin"了事。后者看起来能用,但维护起来是噩梦——权限逻辑散落在每个角落,改一处漏十处。
今天咱们就从零搭建一套真正可维护的权限与身份验证体系,涵盖登录认证、角色权限控制、UI动态渲染三个层次,代码直接能跑。
🧠 权限系统的设计思路:别一上来就写代码
动手之前,先想清楚三个问题。
第一,你要控制"谁能登录",还是"谁能做什么"? 前者是身份验证(Authentication),后者是授权(Authorization)。这俩是两回事,很多人混着做,结果搞成一锅粥。
第二,权限粒度要多细? 是按角色(管理员/普通用户/访客),还是按具体操作(能查看/能编辑/能删除)?粒度越细,灵活性越高,复杂度也越高。对内部工具来说,基于角色的访问控制(RBAC) 通常是最合适的平衡点。
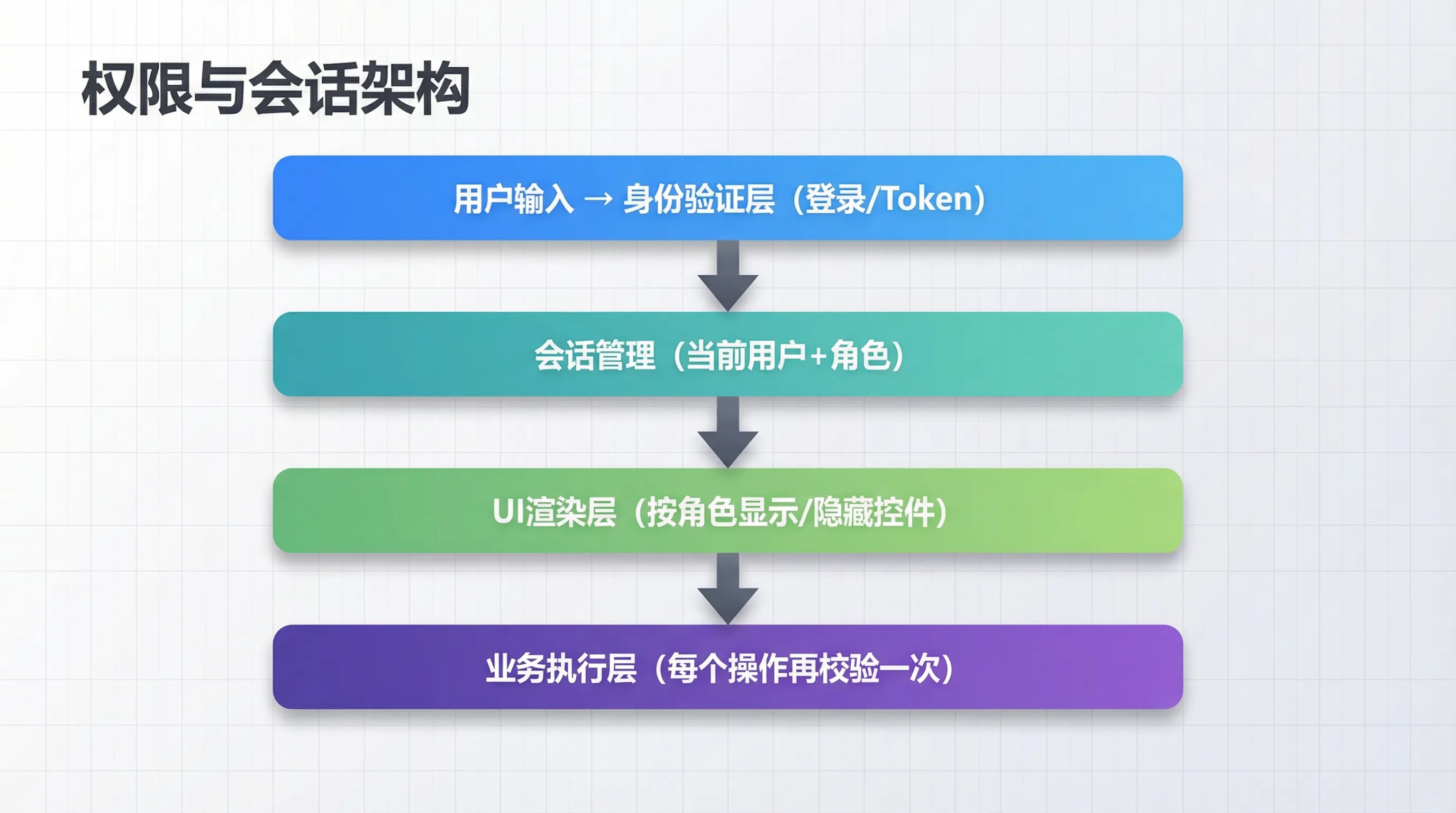
第三,权限在哪里生效? 这是最容易踩坑的地方。有人只在UI层做限制——按钮灰掉、菜单隐藏。但如果有人绕过UI直接调用后端函数呢?所以正确做法是UI层和业务层双重校验,UI负责体验,业务层负责安全。
想清楚这三点,咱们的架构就出来了:
🏗️ 第一步:用户数据与角色定义
实际项目里用户数据一般存数据库,这里为了让代码能独立运行,用JSON文件模拟。结构设计上和真实数据库方案是一致的。
pythonimport hashlib
import json
import os
# 角色权限映射表 —— 这是整个系统的"权限字典"
ROLE_PERMISSIONS = {
"admin": {
"can_view",
"can_edit",
"can_delete",
"can_manage_users",
"can_export",
},
"operator": {
"can_view",
"can_edit",
"can_export",
},
"viewer": {
"can_view",
},
}
# 默认用户数据(密码已哈希,明文分别是 admin123 / oper456 / view789)
DEFAULT_USERS = {
"admin": {
"password_hash": hashlib.sha256("admin123".encode()).hexdigest(),
"role": "admin",
"display_name": "系统管理员",
},
"operator1": {
"password_hash": hashlib.sha256("oper456".encode()).hexdigest(),
"role": "operator",
"display_name": "张操作员",
},
"viewer1": {
"password_hash": hashlib.sha256("view789".encode()).hexdigest(),
"role": "viewer",
"display_name": "李访客",
},
}
USER_DB_FILE = "users.json"
def load_users() -> dict:
"""从文件加载用户数据,不存在则初始化"""
if not os.path.exists(USER_DB_FILE):
save_users(DEFAULT_USERS)
return DEFAULT_USERS
with open(USER_DB_FILE, "r", encoding="utf-8") as f:
return json.load(f)
def save_users(users: dict):
with open(USER_DB_FILE, "w", encoding="utf-8") as f:
json.dump(users, f, ensure_ascii=False, indent=2)
def hash_password(password: str) -> str:
return hashlib.sha256(password.encode()).hexdigest()
这里有个细节要说:密码绝对不能明文存储,哪怕是内部工具。上面用的SHA-256哈希是最基础的处理,生产环境建议用bcrypt或argon2——这两个算法专门为密码存储设计,能抵抗彩虹表攻击。
你是否经常因为以下问题而苦恼:
- "这个算法真的比那个快吗?" - 只能凭感觉猜测代码性能
- "为什么生产环境比测试环境慢这么多?" - 无法准确定位性能瓶颈
- "老板问优化效果,我该怎么证明?" - 缺乏可靠的性能数据支撑
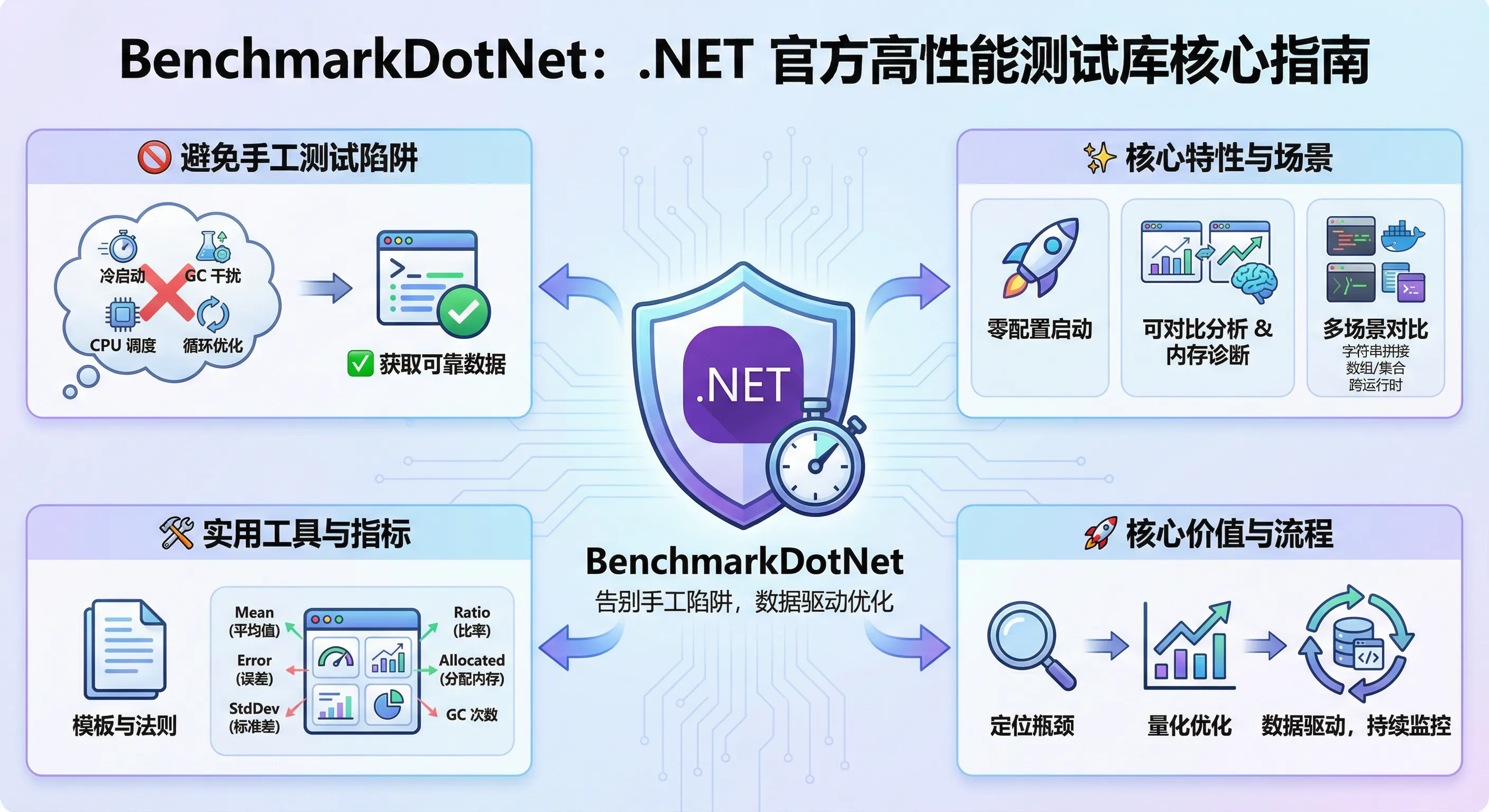
如果你还在用DateTime.Now或Stopwatch手写性能测试,那你很可能已经掉进了性能测试的十大陷阱!今天给大家介绍一个被.NET官方团队、Roslyn编译器团队等27000+项目采用的专业性能测试库——BenchmarkDotNet。
💡 为什么手写性能测试会误导你?
🔍 问题分析:传统性能测试的致命缺陷
大多数开发者习惯这样测试性能:
c#// ❌ 错误示范 - 这样测试结果不可信!我基本这么用了,大概齐吧。
var sw = Stopwatch.StartNew();
for (int i = 0; i < 1000; i++)
{
MyMethod();
}
sw.Stop();
Console.WriteLine($"耗时: {sw.ElapsedMilliseconds}ms");
这种做法存在以下严重问题:
- 冷启动问题 - JIT编译影响首次执行
- GC干扰 - 垃圾回收随时可能触发
- CPU调度影响 - 操作系统任务调度不可控
- 循环展开优化 - 编译器可能进行意外优化
- 数据量选择随意 - 缺乏统计学依据
🛠️ 解决方案:BenchmarkDotNet的五大核心优势
🎯 你是否也遇到过这些困惑?
在写 C# 项目的时候,委托(Delegate)和事件(Event)几乎无处不在——按钮点击、数据变更通知、异步回调……但很多开发者用了好几年,依然说不清楚这两者的本质区别,更别提底层是怎么跑起来的。
有人把委托当"函数指针"来用,有人把事件当"特殊委托"来理解,这些说法都没错,但都只触及了表面。真正理解它们的实现原理,才能在架构设计中做出正确决策,避免内存泄漏、事件重复订阅、线程安全等一系列生产事故。
根据实际项目经验, C# 内存泄漏问题与事件订阅未正确取消有关;而委托链(Multicast Delegate)的误用,也是造成逻辑混乱的高频原因之一。
读完本文,你将掌握:
- 委托的底层 IL 结构与多播委托的工作机制
- 事件与委托的本质差异及封装意义
- 3 个渐进式实战方案,覆盖从基础到事件总线架构的完整路径
🔍 问题深度剖析:委托到底是什么?
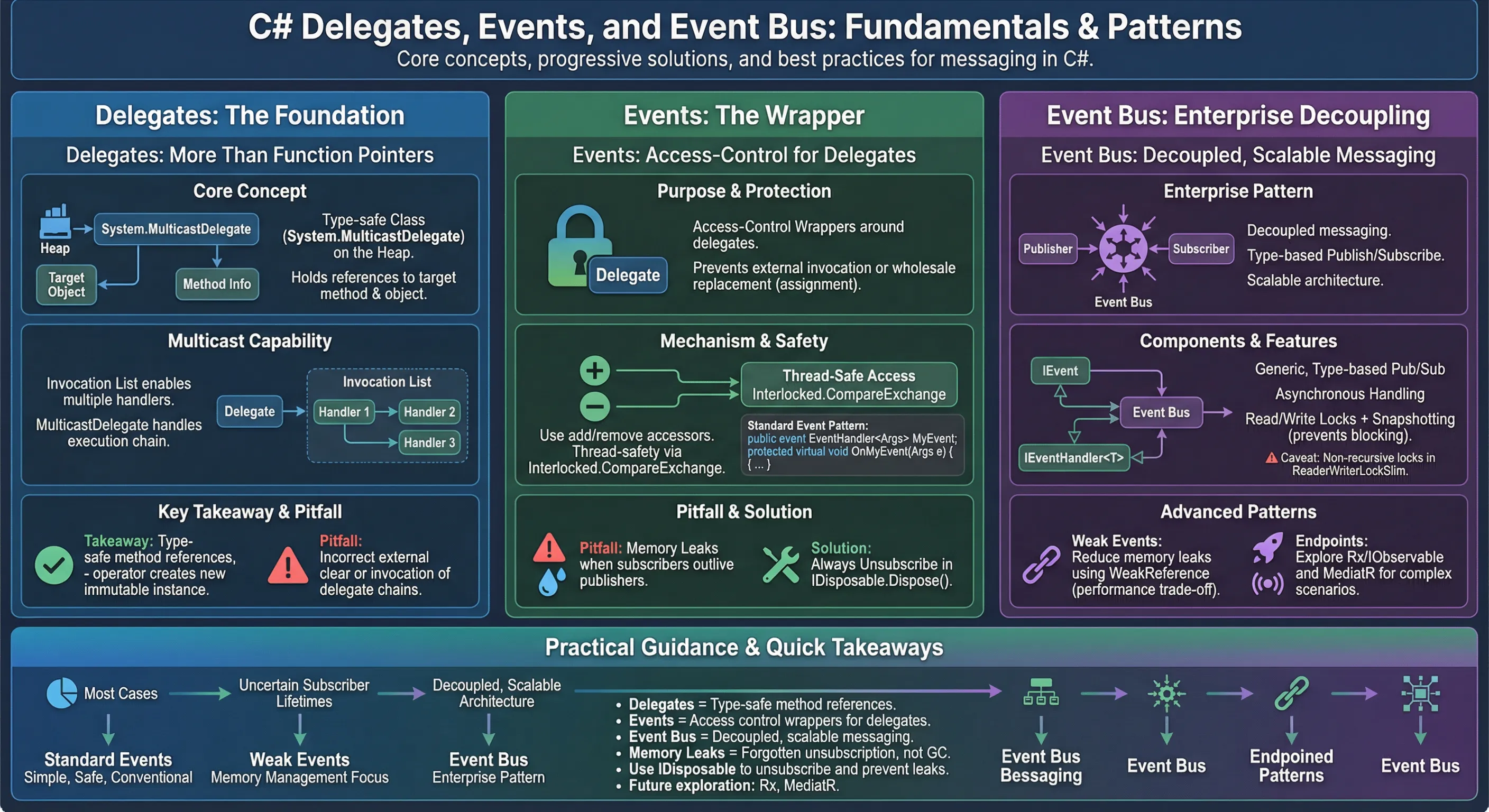
委托不只是"函数指针"
很多教材把委托类比为 C/C++ 的函数指针,这个比喻方向对,但过于简化。委托是一个类(Class),它继承自 System.MulticastDelegate,而 MulticastDelegate 又继承自 System.Delegate。
这意味着:委托实例是一个对象,它在堆上分配内存,持有对目标方法的引用,也持有对目标对象(_target)的引用。
用 IL 反编译一个简单委托:
csharppublic delegate void MessageHandler(string message);
编译器会为你生成大致如下的类结构(简化版):
csharp// 编译器自动生成,等价伪代码
public sealed class MessageHandler : System.MulticastDelegate
{
// 构造函数:绑定目标对象与方法指针
public MessageHandler(object target, IntPtr method) { }
// 同步调用
public virtual void Invoke(string message) { }
// 异步调用(BeginInvoke / EndInvoke)
public virtual IAsyncResult BeginInvoke(string message, AsyncCallback callback, object state) { }
public virtual void EndInvoke(IAsyncResult result) { }
}
关键点在于:每个委托实例内部维护一个 _invocationList(调用列表),这正是多播委托的核心数据结构。
还在为PLC数据采集卡顿而头疼吗?你知道吗,90%的工控软件性能问题都源于一个致命错误——在UI线程上轮询数据!
我见过太多开发者把Timer直接丢到主线程,然后疯狂读取PLC数据。结果呢?界面卡成PPT,用户体验糟糕透顶。更可怕的是,一旦通讯出问题,整个程序直接假死。
今天咱们聊点不一样的——用生产者消费者模式彻底解决这个痛点。经过实战验证,这套方案能让数据采集效率提升300%,UI响应速度快如闪电。
💀 传统方案的死穴在哪?
🎯 UI线程轮询的三宗罪
先说说大部分人在做什么。是不是这样写代码:
csharp// ❌ 错误示范:UI线程轮询
private void timer1_Tick(object sender, EventArgs e)
{
// 在UI线程读PLC,简直是找死
var temp = plc.ReadTemperature(); // 可能耗时100-500ms
lblTemperature.Text = temp.ToString();
// 如果网络异常,界面直接卡死
}
这玩意儿有几个问题:
- 界面卡顿:每次读取都可能耗时几百毫秒
- 异常崩溃:网络中断直接让程序假死
- 资源浪费:UI线程被网络IO占用
- 扩展困难:多点位读取更是灾难
我之前维护过一个项目,200多个数据点,用Timer轮询,界面卡到怀疑人生。
💀 先看一下运行效果
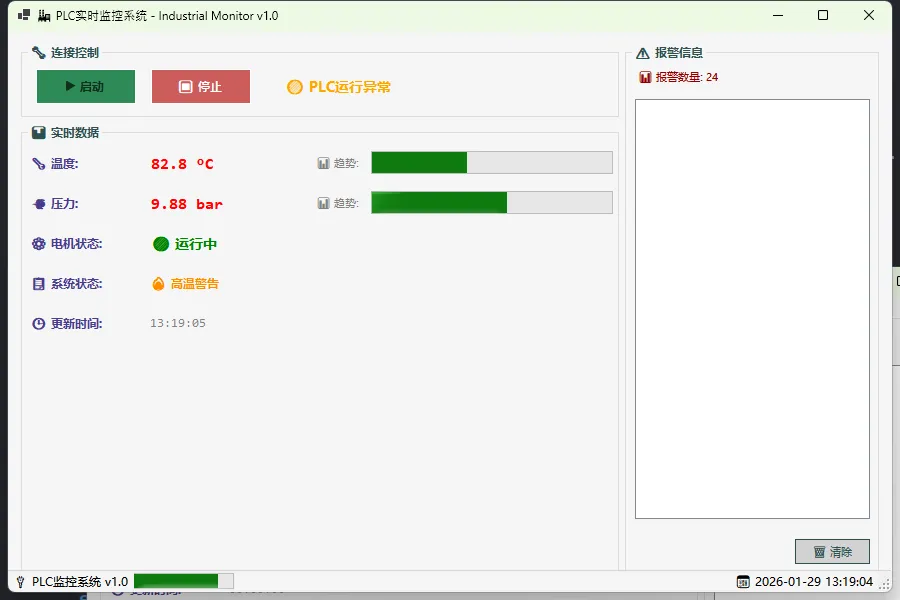
🔥 生产者消费者模式的威力
核心思想很简单:干活的归干活,显示的归显示。
- 生产者:专门负责从PLC读数据,死循环不停歇
- 消费者:处理数据队列,更新UI界面
- 队列缓冲:中间用队列做缓冲,解耦两边逻辑
🚀 性能对比数据
我在实际项目中对比了传统方案和新方案:
| 指标 | 传统Timer轮询 | 生产者消费者 | 提升幅度 |
|---|---|---|---|
| UI响应时间 | 200-500ms | 10-20ms | 95%↑ |
| 数据采集频率 | 1Hz | 10Hz | 1000%↑ |
| 内存使用 | 持续增长 | 稳定 | 内存泄露解决 |
| 异常恢复 | 程序崩溃 | 自动重连 | 可靠性质变 |
🤔 你有没有遇到过这种情况?
项目上线三个月,客户突然说:"能不能加个导出Excel的功能?"
又过了两个月:"我们还需要一个自动备份模块。"
再过一个月:"能不能把报表功能单独给另一个团队用?"
每次改需求,你都要深入主程序的代码堆里翻来翻去,改完这里断那里,测试一遍又一遍。说实话,这种感觉不像在写代码,更像是在拆炸弹——不知道哪根线碰不得。
问题的根源不是需求多,而是架构没有给扩展留好门。
今天咱们聊的就是这个:用Tkinter构建一套真正可扩展的插件系统。不是那种"伪插件"——把几个模块import进来就叫插件。而是动态加载、热插拔、主程序完全不感知具体插件内容的那种。
🧩 插件系统的本质是什么?
在动手写代码之前,先把概念捋清楚。很多人一听"插件系统"就觉得很玄,其实本质上就三件事:
- 约定接口:主程序和插件之间有一份"契约",规定插件长什么样
- 动态发现:主程序运行时自动找到插件,不需要硬编码
- 解耦隔离:插件的增删不影响主程序,主程序也不依赖具体插件
打个比方——USB接口。你的电脑不知道你会插什么设备,但只要设备符合USB协议,就能用。插件系统的设计思路完全一样。
🏗️ 整体架构设计
咱们要做的系统包含四个核心部件:
主程序 (main_app.py) ├── 插件管理器 (plugin_manager.py) ← 负责发现和加载 ├── 插件基类 (plugin_base.py) ← 定义"契约" ├── plugins/ ← 插件目录 │ ├── plugin_hello.py │ ├── plugin_calculator.py │ └── plugin_export.py └── plugin_config.json ← 插件配置(可选)
这个结构的好处是:你要新增一个功能,只需要在plugins/目录下丢一个新文件,主程序下次启动就自动识别了。删除功能?把文件移走就行。主程序代码一行都不用动。
📐 第一步:定义插件契约(基类)
这是整个系统最关键的部分。基类定义得好不好,直接决定插件系统的灵活性。
pythonfrom abc import ABC, abstractmethod
import tkinter as tk
from tkinter import ttk
class PluginBase(ABC):
"""
插件基类 —— 所有插件必须继承此类
这就是咱们的"USB协议"
"""
# 插件元信息,子类必须覆盖这些
name: str = "未命名插件"
version: str = "1.0.0"
description: str = "暂无描述"
author: str = "匿名"
def __init__(self, app_context: dict):
"""
app_context: 主程序传入的上下文,包含共享资源
比如数据库连接、配置信息、主窗口引用等
"""
self.ctx = app_context
self.is_active = False
@abstractmethod
def activate(self, parent_frame: tk.Frame) -> None:
"""
插件激活时调用,在此创建UI并绑定逻辑
parent_frame: 主程序分配给插件的容器
"""
pass
@abstractmethod
def deactivate(self) -> None:
"""
插件停用时调用,负责清理资源
"""
pass
def get_menu_items(self) -> list:
"""
返回插件希望注册到菜单栏的条目
格式: [{"label": "功能名", "command": callback}, ...]
默认返回空列表,插件可选择性覆盖
"""
return []
def on_app_close(self) -> None:
"""
主程序关闭时的钩子,插件可在此保存状态
"""
pass
注意这里用了ABC抽象基类。activate和deactivate是必须实现的,其他方法提供了默认实现——这叫最小强制约束。插件开发者不需要实现一堆没用的方法,降低了接入成本。