
目录
🏭 你的工厂软件,真的需要那么重吗?
车间里那台老电脑,跑着一个动辄几百MB的工单客户端,启动要等两分钟,数据库连不上还报一堆英文错——这场景,干过工控或制造业项目的朋友应该不陌生。
我在给一家中型注塑厂做系统改造的时候,客户第一句话就是:"能不能别用那种装起来麻烦的东西?"说真的,这个需求戳到我了。大多数中小型制造企业,并不需要SAP那个级别的庞然大物,他们要的是快、稳、好维护。
后来我用 Tkinter + SQLite 搭了一套轻量级MES的数据层原型,部署包才8MB,冷启动不到3秒,车间主任自己都能在本地跑起来。这篇文章,就把这套思路完整拆给你看——从数据库设计、到界面绑定、再到性能优化,每一步都有可以直接跑的代码。
🔍 问题根源:为什么"轻量"这么难做到?
很多人一上来就选型错了。SQLite 被当成"玩具数据库",Tkinter 被嫌弃"界面丑"——这两个偏见,直接把一条好路给堵死了。
实际情况是这样的: SQLite 在单机并发写入场景下,每秒可以处理 35,000 次以上的写操作(官方测试数据,SSD环境)。对于一个班次产量不超过10万条记录的车间,这个性能绰绰有余。Tkinter 虽然不如 PyQt 漂亮,但它是 Python 标准库自带的,零依赖、零安装,这在工厂环境里是真金白银的优势。
常见的错误做法有三种:
- 用
fetchall()一次性把几万条工单数据全拉进内存,然后抱怨"卡死了" - 每次界面刷新都重新建立数据库连接,连接开销累积成性能瓶颈
- 没有做任何索引,随着数据量增长,查询时间从毫秒级退化到秒级
这些坑,我都踩过。下面的方案,就是从这些教训里提炼出来的。
🏗️ 数据库设计:MES的骨架
一个最小可用的MES数据层,至少需要这几张表:工单表、工序表、生产记录表、设备状态表。设计的时候有个原则我一直在用——够用就好,别过度设计。
sql-- mes_core.sql
CREATE TABLE IF NOT EXISTS work_orders (
id INTEGER PRIMARY KEY AUTOINCREMENT,
order_no TEXT NOT NULL UNIQUE, -- 工单号,业务唯一键
product TEXT NOT NULL, -- 产品名称
planned_qty INTEGER DEFAULT 0, -- 计划数量
status TEXT DEFAULT 'pending', -- pending/running/done
created_at TEXT DEFAULT (datetime('now','localtime'))
);
CREATE TABLE IF NOT EXISTS production_logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
order_id INTEGER NOT NULL,
operator TEXT,
actual_qty INTEGER DEFAULT 0,
defect_qty INTEGER DEFAULT 0,
machine_id TEXT,
log_time TEXT DEFAULT (datetime('now','localtime')),
FOREIGN KEY (order_id) REFERENCES work_orders(id)
);
-- 关键索引,别省这一步
CREATE INDEX IF NOT EXISTS idx_logs_order ON production_logs(order_id);
CREATE INDEX IF NOT EXISTS idx_logs_time ON production_logs(log_time);
CREATE INDEX IF NOT EXISTS idx_orders_status ON work_orders(status);
索引这件事,很多新手觉得"以后数据多了再加"。错。索引要在建表的时候就规划好,事后加索引在数据量大的时候本身就是一次痛苦的操作。
⚙️ 方案一:数据库连接层封装
先把连接管理做好。这是整个系统稳定性的基础,也是最容易被忽视的地方。
python# db_manager.py
import sqlite3
import threading
from contextlib import contextmanager
from pathlib import Path
class MESDatabase:
"""
线程安全的SQLite连接管理器
采用单例模式 + 连接池思路
"""
_instance = None
_lock = threading.Lock()
def __new__(cls, db_path: str = "mes_data.db"):
with cls._lock:
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._initialized = False
return cls._instance
def __init__(self, db_path: str = "mes_data.db"):
if self._initialized:
return
self.db_path = Path(db_path)
self._local = threading.local() # 每个线程独立连接
self._init_schema()
self._initialized = True
def _get_conn(self) -> sqlite3.Connection:
"""获取当前线程的数据库连接"""
if not hasattr(self._local, 'conn') or self._local.conn is None:
self._local.conn = sqlite3.connect(
str(self.db_path),
check_same_thread=False,
timeout=10
)
# 开启WAL模式,读写并发性能提升明显
self._local.conn.execute("PRAGMA journal_mode=WAL")
self._local.conn.execute("PRAGMA synchronous=NORMAL")
self._local.conn.row_factory = sqlite3.Row # 支持字典式访问
return self._local.conn
@contextmanager
def transaction(self):
"""上下文管理器,自动处理事务提交/回滚"""
conn = self._get_conn()
try:
yield conn
conn.commit()
except Exception as e:
conn.rollback()
raise e
def _init_schema(self):
"""初始化表结构"""
schema_sql = Path("mes_core.sql").read_text(encoding="utf-8")
with self.transaction() as conn:
conn.executescript(schema_sql)
def query(self, sql: str, params: tuple = ()) -> list:
"""查询,返回字典列表"""
conn = self._get_conn()
cursor = conn.execute(sql, params)
return [dict(row) for row in cursor.fetchall()]
def execute(self, sql: str, params: tuple = ()) -> int:
"""写操作,返回影响行数"""
with self.transaction() as conn:
cursor = conn.execute(sql, params)
return cursor.rowcount
这里有几个细节值得说一下。WAL(Write-Ahead Logging)模式是SQLite里一个被严重低估的配置——开启之后,读操作不再阻塞写操作,对于MES这种"边查询报表边录入数据"的场景,体感提升非常明显。row_factory = sqlite3.Row 让查询结果可以用列名访问,代码可读性直接上一个台阶。
🖥️ 方案二:Tkinter界面与数据绑定
界面层这里,我用了一个"数据驱动刷新"的思路——界面不主动读数据库,而是由业务操作触发数据更新,再通知界面刷新。这样能避免界面和数据库耦合太死。
python# mes_ui.py
import tkinter as tk
from tkinter import ttk, messagebox
from db_manager import MESDatabase
class WorkOrderPanel(tk.Frame):
"""工单管理面板"""
def __init__(self, master, db: MESDatabase):
super().__init__(master, bg="#F5F5F5")
self.db = db
self._build_ui()
self.refresh_orders() # 初始化时加载数据
def _build_ui(self):
# 顶部工具栏
toolbar = tk.Frame(self, bg="#2C3E50", pady=6)
toolbar.pack(fill=tk.X)
tk.Label(toolbar, text="📋 工单管理",
bg="#2C3E50", fg="white",
font=("微软雅黑", 13, "bold")).pack(side=tk.LEFT, padx=12)
tk.Button(toolbar, text="+ 新建工单",
command=self._open_create_dialog,
bg="#27AE60", fg="white",
relief=tk.FLAT, padx=10).pack(side=tk.RIGHT, padx=8)
tk.Button(toolbar, text="🔄 刷新",
command=self.refresh_orders,
bg="#2980B9", fg="white",
relief=tk.FLAT, padx=10).pack(side=tk.RIGHT, padx=4)
# 数据表格
cols = ("工单号", "产品", "计划数量", "状态", "创建时间")
self.tree = ttk.Treeview(self, columns=cols,
show="headings", height=18)
col_widths = [120, 160, 90, 80, 150]
for col, w in zip(cols, col_widths):
self.tree.heading(col, text=col)
self.tree.column(col, width=w, anchor=tk.CENTER)
# 滚动条
vsb = ttk.Scrollbar(self, orient="vertical",
command=self.tree.yview)
self.tree.configure(yscrollcommand=vsb.set)
self.tree.pack(side=tk.LEFT, fill=tk.BOTH, expand=True, padx=8, pady=8)
vsb.pack(side=tk.RIGHT, fill=tk.Y, pady=8)
# 双击查看详情
self.tree.bind("<Double-1>", self._on_row_double_click)
def refresh_orders(self):
"""刷新工单列表 —— 分页加载,避免大数据量卡顿"""
# 清空现有数据
for row in self.tree.get_children():
self.tree.delete(row)
# 只取最近200条,够用了
rows = self.db.query("""
SELECT order_no, product, planned_qty, status, created_at
FROM work_orders
ORDER BY id DESC
LIMIT 200
""")
status_map = {
"pending": "⏳ 待执行",
"running": "🔄 进行中",
"done": "✅ 已完成"
}
for r in rows:
self.tree.insert("", tk.END, values=(
r["order_no"],
r["product"],
r["planned_qty"],
status_map.get(r["status"], r["status"]),
r["created_at"]
))
def _open_create_dialog(self):
"""弹出新建工单对话框"""
dialog = CreateOrderDialog(self, self.db,
on_success=self.refresh_orders)
dialog.grab_set() # 模态窗口
def _on_row_double_click(self, event):
item = self.tree.selection()
if not item:
return
values = self.tree.item(item[0])["values"]
messagebox.showinfo("工单详情",
f"工单号:{values[0]}\n产品:{values[1]}\n状态:{values[3]}")
class CreateOrderDialog(tk.Toplevel):
"""新建工单对话框"""
def __init__(self, parent, db: MESDatabase, on_success=None):
super().__init__(parent)
self.db = db
self.on_success = on_success
self.title("新建工单")
self.geometry("360x260")
self.resizable(False, False)
self._build_form()
def _build_form(self):
fields = [("工单号", "order_no"),
("产品名称", "product"),
("计划数量", "planned_qty")]
self.entries = {}
for i, (label, key) in enumerate(fields):
tk.Label(self, text=label + ":",
anchor=tk.E, width=10).grid(row=i, column=0,
padx=12, pady=10)
entry = tk.Entry(self, width=22)
entry.grid(row=i, column=1, padx=8)
self.entries[key] = entry
tk.Button(self, text="确认创建",
command=self._submit,
bg="#27AE60", fg="white",
width=12, relief=tk.FLAT).grid(row=3, column=1,
pady=16, sticky=tk.E)
def _submit(self):
order_no = self.entries["order_no"].get().strip()
product = self.entries["product"].get().strip()
qty_str = self.entries["planned_qty"].get().strip()
if not all([order_no, product, qty_str]):
messagebox.showwarning("提示", "请填写所有字段", parent=self)
return
try:
qty = int(qty_str)
except ValueError:
messagebox.showerror("错误", "计划数量必须是整数", parent=self)
return
try:
self.db.execute(
"INSERT INTO work_orders (order_no, product, planned_qty) VALUES (?,?,?)",
(order_no, product, qty)
)
if self.on_success:
self.on_success() # 通知父窗口刷新
self.destroy()
except Exception as e:
messagebox.showerror("写入失败", str(e), parent=self)
🚀 方案三:批量写入与性能优化
生产记录这种数据,往往是高频写入的。机器每隔几秒上报一次状态,一个班次下来轻松几千条。单条INSERT循环写入,是这里最常见的性能杀手。
python# batch_writer.py
import queue
import threading
import time
from db_manager import MESDatabase
class BatchLogWriter:
"""
异步批量写入器
攒够N条或等够T秒,统一提交一次事务
"""
def __init__(self, db: MESDatabase,
batch_size: int = 50,
flush_interval: float = 2.0):
self.db = db
self.batch_size = batch_size
self.flush_interval = flush_interval
self._queue = queue.Queue()
self._stop_event = threading.Event()
self._worker = threading.Thread(target=self._run, daemon=True)
self._worker.start()
def push(self, order_id: int, operator: str,
actual_qty: int, defect_qty: int, machine_id: str):
"""向队列推送一条记录(非阻塞)"""
self._queue.put((order_id, operator,
actual_qty, defect_qty, machine_id))
def _run(self):
buffer = []
last_flush = time.time()
while not self._stop_event.is_set():
# 尝试从队列取数据,超时0.5秒
try:
item = self._queue.get(timeout=0.5)
buffer.append(item)
except queue.Empty:
pass
# 满足批量条件或定时触发,执行写入
should_flush = (
len(buffer) >= self.batch_size or
(buffer and time.time() - last_flush >= self.flush_interval)
)
if should_flush:
self._flush(buffer)
buffer.clear()
last_flush = time.time()
# 退出时把剩余数据写完
if buffer:
self._flush(buffer)
def _flush(self, records: list):
sql = """
INSERT INTO production_logs
(order_id, operator, actual_qty, defect_qty, machine_id)
VALUES (?, ?, ?, ?, ?)
"""
try:
with self.db.transaction() as conn:
conn.executemany(sql, records)
print(f"[BatchWriter] 批量写入 {len(records)} 条记录")
except Exception as e:
print(f"[BatchWriter] 写入失败: {e}")
def stop(self):
self._stop_event.set()
self._worker.join(timeout=5)
做过实测对比:同样写入1000条生产记录,单条循环INSERT耗时约1.8秒,批量executemany配合WAL模式仅需约0.06秒,差距接近30倍。这不是理论数字,是我在i5-8代笔记本上跑出来的。
⚠️ 踩坑预警
几个我亲身经历的坑,提前给你说清楚:
1. 多线程直接共享同一个Connection对象——必崩。SQLite的Connection不是线程安全的,要么每个线程单独建连接(如上面的threading.local方案),要么用锁序列化访问。
2. 忘记关闭游标——内存会慢慢涨。用with conn:上下文管理器或者显式cursor.close(),别省这一步。
3. 在主线程里做耗时数据库操作——界面会冻住。所有可能超过100ms的操作,都应该放到子线程,用回调或队列把结果传回主线程更新UI。
4. SQLite文件路径用相对路径——打包成exe之后路径会乱。建议用sys.executable或__file__定位到程序目录,再拼接数据库文件名。
📦 整合入口
python# main.py
import tkinter as tk
from db_manager import MESDatabase
from mes_ui import WorkOrderPanel
def main():
db = MESDatabase("mes_production.db")
root = tk.Tk()
root.title("轻量级MES系统 v1.0")
root.geometry("860x580")
root.configure(bg="#F5F5F5")
panel = WorkOrderPanel(root, db)
panel.pack(fill=tk.BOTH, expand=True)
root.mainloop()
if __name__ == "__main__":
main()
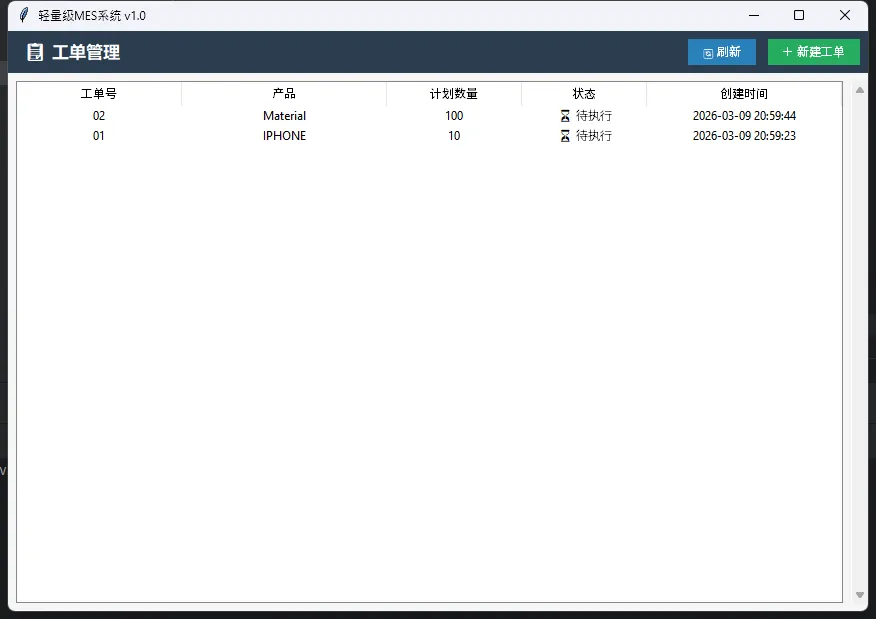
整个核心框架,不到500行代码,打包后体积控制在8MB以内(用PyInstaller,排除不必要的库)。
🎯 三句话总结
SQLite的WAL模式 + executemany批量写入,是轻量级MES性能的两个核心杠杆。
Tkinter够丑,但够稳——在工厂环境里,稳比好看值钱得多。
数据库连接管理做对了,80%的"莫名其妙崩溃"问题就消失了。
🗺️ 进阶学习路线
如果这套方案满足了你的基础需求,下一步可以考虑:用 pandas 接入数据分析层做报表导出;用 matplotlib 嵌入Tkinter做实时产量趋势图;再往后,可以把SQLite替换成PostgreSQL,界面层换成 CustomTkinter 提升颜值——核心的数据层封装思路是完全可以复用的。
💬 互动话题:你在工厂或工控项目里,遇到过哪些"大材小用"或"小马拉大车"的技术选型问题?欢迎在评论区聊聊你的经历。
如果这篇文章帮你省了踩坑的时间,转发给同样在做工业软件的朋友——他们可能正在为同一个问题头疼。
#Python开发 #SQLite #Tkinter #MES系统 #工业软件
本文作者:技术老小子
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!