
🎯 你是否也遇到过这个问题?
做数据可视化的时候,折线图画出来了,数据也对了,但总觉得少点什么——图表太"干",领导看一眼就划走,用户盯着屏幕也读不出重点。
这不是设计能力的问题,而是图表类型选错了。
折线图适合趋势对比,但如果你想让用户一眼感受到数据的"量感"——比如销售额的堆积、温度的波动范围、流量的峰谷变化——那面积图(AreaSeries)才是正解。更进一步,渐变填充能让视觉层次感直接拉满,区域越大颜色越深,区域收窄颜色自然淡去,数据的高低起伏在视觉上变得极其直观。
本文基于 LiveCharts 2(LiveChartsCore.SkiaSharpView.WinForms),从零到一带你实现:
- ✅ 基础面积图搭建
- ✅ 渐变填充配置(LinearGradientPaint)
- ✅ 多系列面积图叠加与透明度控制
代码可直接运行,拿去就能用。
🔍 问题深度剖析:为什么折线图不够用?
很多开发者在做监控面板或数据报表时,第一反应是折线图。折线图确实简洁,但它有一个致命弱点:视觉重量感不足。
用折线图展示"某月每日销售额",用户看到的是一条线在波动,但很难直觉上感知"这个月整体销量是多是少"。面积图通过填充线条以下的区域,把趋势 + 量感同时传递给用户,认知负担大幅降低。
而普通的纯色填充又容易显得呆板,尤其在深色主题或多系列叠加时,颜色块堆在一起辨识度很差。渐变填充的核心价值在于:
- 用颜色深浅暗示数值高低,符合人类直觉
- 多系列叠加时,透明渐变让底层数据依然可见
- 视觉上更现代、更专业,减少"PPT感"
LiveCharts 2 的 LinearGradientPaint 正是为此而生,但官方文档在 WinForms 场景下的示例相当有限,很多开发者折腾半天找不到正确姿势。下面我们一步步来。
💡 核心要点提炼
在动手之前,有几个概念值得先搞清楚,避免后面踩坑。
LiveCharts 2 的绘制引擎是 SkiaSharp,这意味着所有的颜色、画笔、渐变都走 Skia 的 API,而不是 WinForms 原生的 System.Drawing。两套体系不互通,混用会报错。
AreaSeries<T> 有两个关键画笔属性:
Stroke:控制上方折线的样式Fill:控制填充区域的样式
普通纯色填充用 SolidColorPaint,渐变填充用 LinearGradientPaint。LinearGradientPaint 接收一个颜色数组和渐变方向,颜色从上到下(或任意方向)过渡,配合透明度(Alpha 通道)就能实现"上深下淡"的经典面积图效果。
另一个常见误区是忘记设置 GeometrySize = 0。默认情况下,AreaSeries 在每个数据点上会画一个小圆点,数据量大时这些圆点会严重影响性能和美观。实际项目里通常直接把它设为 0 隐藏掉。
🛠️ 方案一:基础面积图 + 渐变填充
这是最基础的使用场景:单系列数据,渐变从主色调过渡到透明,清晰展示趋势。
环境准备
首先通过 NuGet 安装依赖:
LiveChartsCore.SkiaSharpView.WinForms
目前稳定版本为 2.0.0-rc2 系列,建议锁定版本避免 API 变动。
完整代码实现
新建一个 WinForms 项目,在 Form1.cs 中:
csharpusing LiveChartsCore;
using LiveChartsCore.SkiaSharpView;
using LiveChartsCore.SkiaSharpView.Painting;
using LiveChartsCore.SkiaSharpView.WinForms;
using SkiaSharp;
namespace AppLiveChart15
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
InitChart();
}
private void InitChart()
{
var salesData = new double[]
{
120, 145, 132, 178, 165, 190, 210,
198, 223, 245, 230, 267, 289, 275,
301, 318, 295, 340, 328, 356, 372,
360, 389, 401, 385, 420, 445, 432, 460, 478
};
var gradientFill = new LinearGradientPaint(
new[]
{
new SKColor(33, 150, 243, 180),
new SKColor(33, 150, 243, 20)
},
new SKPoint(0.5f, 0f),
new SKPoint(0.5f, 1f)
);
// 我记得以前有一个 AreaSeries
var areaSeries = new LineSeries<double>
{
Values = salesData,
Name = "月销售额(万元)",
Stroke = new SolidColorPaint(new SKColor(33, 150, 243))
{
StrokeThickness = 2
},
// 设置 Fill 即可实现面积图效果
Fill = gradientFill,
GeometrySize = 0,
LineSmoothness = 0.65
};
var cartesianChart = new CartesianChart
{
Dock = DockStyle.Fill,
Series = new ISeries[] { areaSeries },
XAxes = new[]
{
new Axis
{
Name = "日期",
LabelsRotation = 0
}
},
YAxes = new[]
{
new Axis
{
Name = "销售额(万元)",
MinLimit = 0
}
}
};
Controls.Add(cartesianChart);
}
}
}
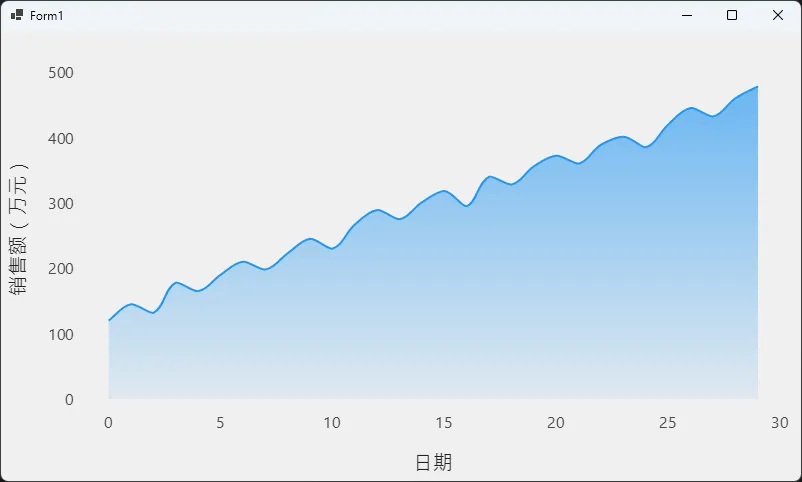
效果说明
运行后你会看到一条蓝色平滑曲线,曲线以下区域从顶部的半透明蓝色渐变到底部的几乎透明,整体既有层次感又不会遮挡背景。MinLimit = 0 这一行很关键——Y 轴如果不从 0 开始,面积区域会被截断,"量感"大打折扣。
设备报警信息要显示在监控屏上,你写了这么一行:
"设备" + deviceId + "温度超限,当前值:" + temp + "℃,阈值:" + threshold + "℃"
加号写了一串,括号配了半天,运行一看,数字之间多了个空格,小数点后面跟了一堆零。领导说:"这显示的什么东西,能不能专业点?"
你盯着代码,不知道从哪改起。
这种情况,今天这篇文章能帮你彻底解决。
📌 上节回顾
上一节我们学了运算符全解,掌握了算术运算、逻辑判断和位运算的使用方法。今天在这个基础上,我们进一步学习字符串操作——如何把设备数据、状态信息、报警内容,拼成一条条可读性强的文字输出。
💡 核心知识讲解
字符串是什么?先用工厂类比理解
字符串(string)就是一串文字,像一条"传送带标签",把各种信息贴在一起传出去。
在工业软件里,你每天都在跟字符串打交道:设备名称、报警描述、日志内容、报表表头……全是字符串。
C# 里的字符串用双引号括起来,例如:"3号注塑机温度超限" 就是一个字符串。
方法一:用 + 号拼接(最直接,但有坑)
最原始的方式是用 + 号把几段文字"焊"在一起:
csharpstring deviceName = "3号注塑机";
double temp = 285.6;
string msg = "设备:" + deviceName + ",当前温度:" + temp + "℃";
这种方式简单,但问题也明显:
- 变量一多,加号写得眼花
- 数字格式不受控,小数位数可能不对
- 频繁拼接会产生大量临时对象,影响性能
「小项目凑合用,正式项目别这么干。」
方法二:string.Format() 格式化(老派但精准)
string.Format() 是 C# 的"模板填空"方法,用 {0}、{1} 占位,再把变量填进去:
csharpstring result = string.Format("设备:{0},温度:{1:F1}℃,状态:{2}",
deviceName, temp, "超限");
🎯 你是否也遇到过这些问题?
在做桌面端库存管理系统时,最让人头疼的不是功能本身,而是界面"卡死"——用户点了一下"刷新库存",整个窗口就像被冻住了,转圈转了三秒,才慢吞吞地更新数据。更糟糕的是,有时候多个操作同时触发,数据还会出现错乱。
这背后的根本原因,往往不是业务逻辑写错了,而是事件处理模型设计得不对。
本文会带你系统性地理解 CustomTkinter 的事件驱动机制,从底层原理到实战代码,一步步构建一个实时响应、数据同步准确、UI 流畅不卡顿的库存管理系统。读完之后,你能直接拿走:
- 一套可复用的事件总线架构模板
- 多线程安全更新 UI 的标准写法
- 实时库存预警的完整实现方案
测试环境:Windows 11 + Python 3.11 + CustomTkinter 5.2.2,所有代码均经过本地验证。
🔍 问题深度剖析:为什么 GUI 会"假死"?
主线程的致命陷阱
Tkinter(以及基于它的 CustomTkinter)有一个铁律:所有 UI 操作必须在主线程执行。它的事件循环 mainloop() 本质上是一个单线程的消息队列,每次只能处理一件事。
当你在按钮回调里直接写数据库查询或网络请求时,主线程就被阻塞了。mainloop() 无法继续处理鼠标移动、窗口重绘等消息,用户看到的就是"假死"。
很多初学者的第一反应是"那我加个 time.sleep() 或者 threading.Thread 不就行了"——方向对了,但如果在子线程里直接操作 Label.configure() 或 CTkLabel.configure(),就会触发 Tkinter 的线程安全问题,轻则数据错乱,重则直接崩溃。
常见的错误写法
python# ❌ 错误示范:在子线程中直接操作 UI 控件
import threading
import customtkinter as ctk
def load_data_wrong(label):
import time
time.sleep(2) # 模拟耗时操作
label.configure(text="数据加载完成") # 危险!子线程操作 UI
app = ctk.CTk()
label = ctk.CTkLabel(app, text="等待中...")
label.pack()
btn = ctk.CTkButton(app, text="加载",
command=lambda: threading.Thread(
target=load_data_wrong, args=(label,)
).start())
btn.pack()
app.mainloop()
这段代码在小规模测试时可能"侥幸"运行,但在高频触发或复杂场景下,必然出问题。线程安全不是"大概率没问题",而是"必须保证正确"。
💡 核心要点提炼:事件驱动的正确姿势
after() 方法:主线程安全调度的核心
CustomTkinter 继承了 Tkinter 的 after(ms, func) 方法,它的作用是将函数调度回主线程的事件队列,在指定毫秒后执行。这是解决线程安全问题的官方推荐方式。
python# ✅ 正确做法:通过 after() 将 UI 更新调度回主线程
app.after(0, lambda: label.configure(text="数据加载完成"))
after(0, ...) 意味着"尽快执行,但必须在主线程"。这一行代码,解决了 90% 的线程安全问题。
事件总线模式:解耦业务与 UI
当系统复杂度上升,组件之间互相调用会形成"蜘蛛网"依赖。引入事件总线(Event Bus),让各模块通过发布/订阅消息通信,彻底解耦。
核心思路:
- 发布者(如数据层)只管发出事件,不关心谁来处理
- 订阅者(如 UI 层)只管监听感兴趣的事件,不关心数据从哪来
- 事件总线负责路由,并保证 UI 回调在主线程安全执行
这个模式在 Vue、React 的状态管理中早已是标配,用在桌面 GUI 里同样好使。
🎯 场景还原
凌晨2点,生产线突然停机。现场工程师焦急地盯着串口调试工具,数据包时有时无,连接状态不稳定。"又是串口通信的问题!"这是我在工业自动化项目中最常听到的抱怨。
我见过太多因为串口通信不稳定导致的生产事故。串口看似简单,实则暗藏玄机:线程安全、异常处理、数据完整性、UI响应,每一个环节都可能成为系统崩溃的导火索。
今天,我将用一个完整的工业级案例,带你掌握C# WinForms串口通信的核心技术,让你的应用从"能用"升级到"好用"、"稳用"。
🔍 串口通信开发的五大痛点分析
痛点1:UI线程冻结问题
传统的同步串口操作会阻塞UI线程,造成界面卡死,用户体验极差。
痛点2:数据接收不完整
串口数据是流式传输,一次接收可能只是完整数据的一部分,如何保证数据完整性?
痛点3:异常处理不当
设备断电、拔插串口线等异常情况处理不当,程序直接崩溃。
痛点4:多串口管理混乱
工业现场往往需要同时管理多个串口,传统方式代码冗余,维护困难。
痛点5:调试困难
数据收发过程不可视,问题排查如大海捞针。
💡 工业级串口通信解决方案
🚀 核心架构设计
我们采用分层架构设计,将串口操作封装成独立的管理器:
markdown┌─────────────────────┐ │ UI层 (WinForms) │ ← 用户界面,数据展示 ├─────────────────────┤ │ 业务逻辑层(Manager) │ ← 串口管理,事件处理 ├─────────────────────┤ │ 封装层(Wrapper) │ ← 串口封装,异常处理 └─────────────────────┘
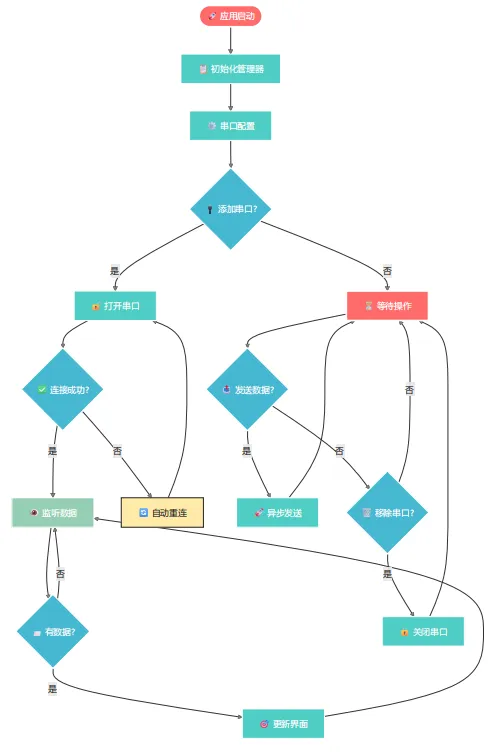
🎯 解决方案一:线程安全的串口封装类
核心思路:使用SemaphoreSlim确保写操作的线程安全,Timer实现智能重连。
c#using System;
using System.Collections.Generic;
using System.IO.Ports;
using System.Linq;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
namespace AppMultiSerialPortManager
{
public class SerialPortWrapper : IDisposable
{
private readonly SerialPort _serialPort;
private readonly SemaphoreSlim _writeSemaphore;
private readonly Timer _reconnectTimer;
private bool _disposed = false;
private volatile bool _isReconnecting = false;
public event EventHandler<SerialDataReceivedEventArgs> DataReceived;
public event EventHandler<SerialErrorEventArgs> ErrorOccurred;
public string PortName => _serialPort.PortName;
public bool IsOpen => _serialPort?.IsOpen ?? false;
public SerialPortWrapper(string portName, int baudRate, Parity parity, int dataBits, StopBits stopBits)
{
_serialPort = new SerialPort(portName, baudRate, parity, dataBits, stopBits)
{
ReadTimeout = 1000,
WriteTimeout = 1000,
ReceivedBytesThreshold = 1
};
_serialPort.DataReceived += _serialPort_DataReceived;
_serialPort.ErrorReceived += SerialPort_ErrorReceived;
_writeSemaphore = new SemaphoreSlim(1, 1);
_reconnectTimer = new Timer(ReconnectCallback, null, Timeout.Infinite, Timeout.Infinite);
}
private void _serialPort_DataReceived(object sender, System.IO.Ports.SerialDataReceivedEventArgs e)
{
try
{
var serialPort = sender as SerialPort;
if (serialPort != null && serialPort.IsOpen)
{
var bytesToRead = serialPort.BytesToRead;
if (bytesToRead > 0)
{
var buffer = new byte[bytesToRead];
var bytesRead = serialPort.Read(buffer, 0, bytesToRead);
if (bytesRead > 0)
{
var actualData = new byte[bytesRead];
Array.Copy(buffer, actualData, bytesRead);
OnDataReceived(new SerialDataReceivedEventArgs(PortName, actualData));
}
}
}
}
catch (Exception ex)
{
OnErrorOccurred(new SerialErrorEventArgs(PortName, ex));
}
}
public bool Open()
{
try
{
if (!_serialPort.IsOpen)
{
_serialPort.Open();
_serialPort.DiscardInBuffer();
_serialPort.DiscardOutBuffer();
}
return true;
}
catch (Exception ex)
{
OnErrorOccurred(new SerialErrorEventArgs(PortName, ex));
return false;
}
}
public void Close()
{
try
{
if (_serialPort.IsOpen)
{
_serialPort.Close();
}
}
catch (Exception ex)
{
OnErrorOccurred(new SerialErrorEventArgs(PortName, ex));
}
}
public async Task<bool> WriteDataAsync(byte[] data)
{
if (data == null || data.Length == 0)
return false;
await _writeSemaphore.WaitAsync();
try
{
if (!_serialPort.IsOpen)
{
if (!Open())
return false;
}
await Task.Run(() => _serialPort.Write(data, 0, data.Length));
return true;
}
catch (Exception ex)
{
OnErrorOccurred(new SerialErrorEventArgs(PortName, ex));
StartReconnectTimer();
return false;
}
finally
{
_writeSemaphore.Release();
}
}
public async Task<bool> WriteStringAsync(string data)
{
if (string.IsNullOrEmpty(data))
return false;
var bytes = System.Text.Encoding.UTF8.GetBytes(data);
return await WriteDataAsync(bytes);
}
private void SerialPort_ErrorReceived(object sender, SerialErrorReceivedEventArgs e)
{
OnErrorOccurred(new SerialErrorEventArgs(PortName, new Exception($"串口错误: {e.EventType}")));
StartReconnectTimer();
}
private void StartReconnectTimer()
{
if (!_isReconnecting && !_disposed)
{
_isReconnecting = true;
_reconnectTimer.Change(TimeSpan.FromSeconds(5), TimeSpan.FromSeconds(5));
}
}
private void ReconnectCallback(object state)
{
try
{
if (_disposed)
return;
Close();
Thread.Sleep(1000); // 等待端口释放
if (Open())
{
_isReconnecting = false;
_reconnectTimer.Change(Timeout.Infinite, Timeout.Infinite);
}
}
catch (Exception ex)
{
OnErrorOccurred(new SerialErrorEventArgs(PortName, ex));
}
}
private void OnDataReceived(SerialDataReceivedEventArgs e)
{
DataReceived?.Invoke(this, e);
}
private void OnErrorOccurred(SerialErrorEventArgs e)
{
ErrorOccurred?.Invoke(this, e);
}
public void Dispose()
{
if (!_disposed)
{
_disposed = true;
_reconnectTimer?.Dispose();
_writeSemaphore?.Dispose();
try
{
if (_serialPort != null)
{
if (_serialPort.IsOpen)
_serialPort.Close();
_serialPort.Dispose();
}
}
catch { }
}
}
}
}
实战应用:适用于需要高稳定性的工业控制系统,如PLC通信、传感器数据采集。
避坑指南:⚠️ 必须设置合理的读写超时时间,避免无限等待导致程序假死。
写给每一位想用 C# 写出跨平台桌面应用的开发者
🤔 你是否也有这样的困惑?
刚接触 Avalonia 的时候,不少开发者卡在了"第一步"——环境搭建。
明明照着网上的教程一步步操作,结果 dotnet new 跑出来没有 Avalonia 模板;或者 SDK 版本对不上,编译直接报错;再或者 NuGet 源没配好,包死活下不下来。一顿折腾两三个小时,Hello World 都没跑起来,挫败感拉满。
这篇文章就是为了解决这个问题。
读完之后,你将掌握:从零到一完整搭建 Avalonia 开发环境的标准流程,包括 .NET SDK 的版本选择与验证、Avalonia 模板的安装与更新、常见报错的排查思路,以及创建并运行第一个项目的完整步骤。整个过程控制在 30 分钟以内,可直接落地到实际项目中。
🧩 先搞清楚:Avalonia 到底是什么?
在动手之前,咱们先花两分钟把概念摸清楚,后面操作起来才不会懵。
Avalonia 是一个基于 .NET 的开源跨平台 UI 框架,设计理念上和 WPF 非常接近——同样用 XAML 描述界面,同样支持数据绑定和 MVVM 模式。但它最大的不同在于:一套代码,能跑在 Windows、macOS、Linux,甚至 iOS、Android 和 WebAssembly 上。
对于长期做 Windows 桌面开发的 C# 开发者来说,Avalonia 的学习曲线相当平缓。如果你熟悉 WPF,上手 Avalonia 基本不需要太多额外学习成本。而对于想从 Windows 走向全平台的团队,Avalonia 是目前 .NET 生态里最成熟的选择之一。
🛠️ 第一步:安装 .NET SDK
版本要求
Avalonia 目前要求 .NET 8.0 或更高版本。这一点需要特别注意——很多老项目可能还跑在 .NET 6 甚至 .NET Framework 上,但 Avalonia 的模板和工具链已经全面迁移到 .NET 8+。
当然,.NET 支持多版本共存,你完全可以在同一台机器上同时装着 .NET 6、.NET 8、.NET 9,它们互不干扰。
下载与安装
前往 dotnet.microsoft.com 下载对应操作系统的 SDK 安装包。
- Windows:下载
.exe安装程序,一路 Next 即可 - macOS:下载
.pkg安装包,或者通过 Homebrew 安装:
bashbrew install --cask dotnet-sdk
- Linux(Ubuntu/Debian 系):
bashsudo apt-get update sudo apt-get install -y dotnet-sdk-8.0
验证安装是否成功
安装完成后,打开终端(Windows 用 PowerShell 或 CMD),执行:
bashdotnet --version
如果输出类似 8.0.xxx 或 10.0.xxx 的版本号,说明安装成功。
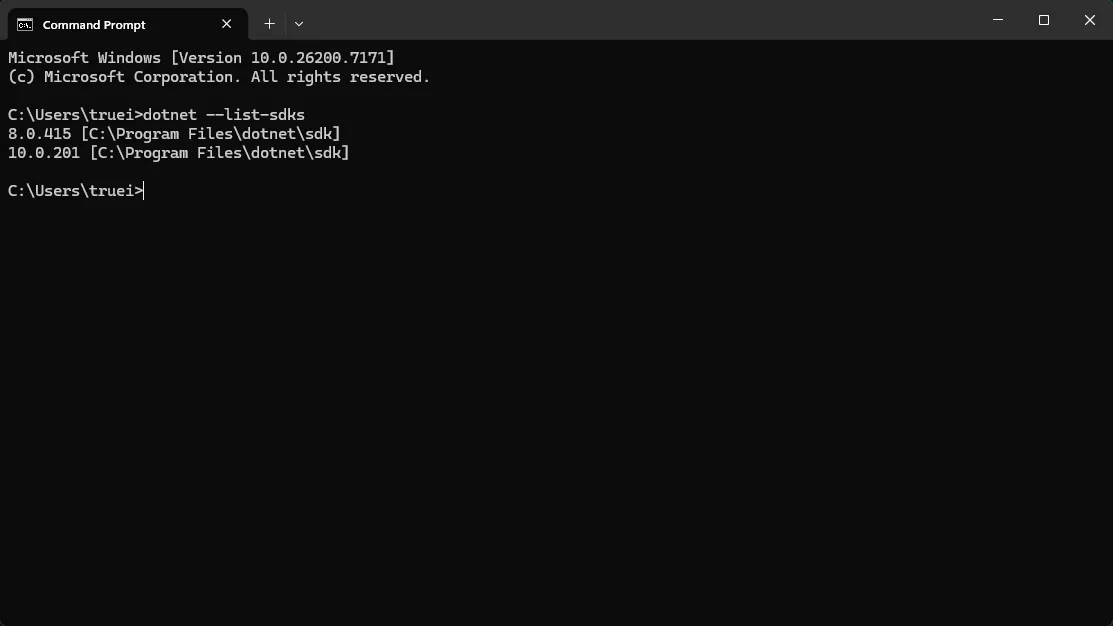
想查看当前机器上装了哪些版本的 SDK,执行:
bashdotnet --list-sdks
输出示例:
📦 第二步:安装 Avalonia 项目模板
.NET SDK 本身并不自带 Avalonia 的项目模板,需要单独安装。这一步是很多新手卡壳的地方。
安装命令
bashdotnet new install Avalonia.Templates
Avalonia 要求 .NET 8+,正常情况下直接用
install子命令就行。
安装成功后,终端会输出一张模板清单,大概长这样:
Template Name Short Name Language Tags -------------------------------------------- ---------------------------- ----------- --------------------------------------------------------- Avalonia .NET App avalonia.app [C#],F# Desktop/Xaml/Avalonia/Windows/Linux/macOS Avalonia .NET MVVM App avalonia.mvvm [C#],F# Desktop/Xaml/Avalonia/Windows/Linux/macOS Avalonia Cross Platform Application avalonia.xplat [C#],F# Desktop/Xaml/Avalonia/Browser/Mobile Avalonia Resource Dictionary avalonia.resource Desktop/Xaml/Avalonia/Windows/Linux/macOS Avalonia Styles avalonia.styles Desktop/Xaml/Avalonia/Windows/Linux/macOS Avalonia TemplatedControl avalonia.templatedcontrol [C#],F# Desktop/Xaml/Avalonia/Windows/Linux/macOS Avalonia UserControl avalonia.usercontrol [C#],F# Desktop/Xaml/Avalonia/Windows/Linux/macOS Avalonia Window avalonia.window [C#],F# Desktop/Xaml/Avalonia/Windows/Linux/macOS