
🤔 你真的需要 SQLAlchemy 吗?
在不少 Python 项目里,咱们下意识就会拉上 SQLAlchemy——毕竟名气大、生态全。但你有没有算过,一个只需要管理十几张表的内部工具或数据采集服务,光是 SQLAlchemy 的初始化配置就要写多少行?Session 管理、Engine 绑定、Base 声明……还没开始写业务逻辑,头已经大了。
我在做一个 Windows 上位机数据记录模块时,最初也是习惯性地用 SQLAlchemy,结果光是数据库连接层就折腾了半天。后来换成 Peewee,整个模型定义加连接管理压缩到不足 30 行,查询逻辑清晰得像在读英语句子。
Peewee 是一个极简的 Python ORM,代码库不超过 6000 行,支持 SQLite、MySQL、PostgreSQL,在轻量级应用、嵌入式数据库场景、快速原型开发中有着无可替代的优势。读完本文,你将掌握:
- Peewee 的核心模型设计与字段映射
- 关联查询与批量操作的正确姿势
- 在 Windows 上位机或中间件项目中落地的实战模板
🔍 问题深度剖析:ORM 选型的隐性成本
很多开发者在选 ORM 时只看"功能是否齐全",却忽略了另一个维度——认知负担与维护成本。
以一个典型的设备数据采集服务为例,需求很简单:每隔 5 秒把传感器数值写入 SQLite,偶尔按时间范围查询。这种场景下,SQLAlchemy 的 Session 生命周期管理、连接池配置、事务上下文……每一个知识点都是额外的学习成本,而且在多线程环境下稍有不慎就会出现 DetachedInstanceError 或连接泄漏。
问题根源在于工具与场景的错配。 重型 ORM 为复杂的企业级应用设计,内置了大量在小型项目中根本用不到的抽象层。这些抽象层不仅增加了初始化开销,还让代码变得难以追踪——一个简单的 INSERT 操作背后可能经历了三四层封装。
在实测中(测试环境:Windows 11,Python 3.11,SQLite 本地文件,10 万条记录批量写入),Peewee 的 bulk_create 耗时约 1.2 秒,而等价的 SQLAlchemy Core 写法耗时约 1.8 秒,ORM 层写法则接近 3.5 秒。差距在数据量增大后会进一步拉开。
💡 核心要点提炼:Peewee 的设计哲学
Peewee 的底层逻辑非常直接:模型即表,字段即列,查询即链式调用。它没有 SQLAlchemy 那种"工作单元"模式,也没有复杂的 identity map,每次查询就是一次干净的数据库交互。
🏗️ 模型定义:直觉优先
pythonfrom peewee import *
# 连接 SQLite 数据库(Windows 路径兼容)
db = SqliteDatabase('sensor_data.db')
class BaseModel(Model):
class Meta:
database = db
class Device(BaseModel):
"""设备信息表"""
name = CharField(max_length=64, unique=True)
location = CharField(max_length=128, null=True)
created_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])
class Meta:
table_name = 'devices'
class SensorRecord(BaseModel):
"""传感器记录表"""
device = ForeignKeyField(Device, backref='records', on_delete='CASCADE')
temperature = FloatField()
humidity = FloatField(null=True)
recorded_at = DateTimeField(index=True)
class Meta:
table_name = 'sensor_records'
模型定义清晰到不需要注释就能看懂结构。backref='records' 这一个参数,就完成了反向关联的声明——后续可以直接用 device.records 遍历该设备的所有记录。
🔗 连接管理:上下文即安全
Peewee 推荐使用上下文管理器处理连接,这在 Windows 上位机的多线程环境中尤为重要:
python# 建表(仅首次运行或迁移时执行)
with db:
db.create_tables([Device, SensorRecord], safe=True)
# 日常操作统一用 atomic() 事务上下文
def save_record(device_name: str, temp: float, humidity: float, ts):
with db.atomic():
device, _ = Device.get_or_create(name=device_name)
SensorRecord.create(
device=device,
temperature=temp,
humidity=humidity,
recorded_at=ts
)
db.atomic() 既是事务边界,也是异常回滚的保障。如果块内抛出异常,事务自动回滚,不会留下脏数据。
🚀 解决方案设计
方案一:基础 CRUD 与链式查询
适用场景: 单表操作、条件筛选、排序分页,覆盖 80% 的日常需求。
pythonimport os
from peewee import *
from datetime import datetime, timedelta
import logging
import random
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 连接 SQLite 数据库(Windows 路径兼容)
db = SqliteDatabase('sensor_data.db')
class BaseModel(Model):
class Meta:
database = db
class Device(BaseModel):
"""设备信息表"""
name = CharField(max_length=64, unique=True)
location = CharField(max_length=128, null=True)
status = CharField(max_length=20, default='active') # active, inactive, maintenance
created_at = DateTimeField(constraints=[SQL('DEFAULT CURRENT_TIMESTAMP')])
class Meta:
table_name = 'devices'
def __str__(self):
return f"Device({self.name}, {self.location})"
class SensorRecord(BaseModel):
"""传感器记录表"""
device = ForeignKeyField(Device, backref='records', on_delete='CASCADE')
temperature = FloatField()
humidity = FloatField(null=True)
pressure = FloatField(null=True) # 新增气压字段
recorded_at = DateTimeField(index=True)
class Meta:
table_name = 'sensor_records'
indexes = (
# 复合索引,提升查询性能
(('device', 'recorded_at'), False),
)
def __str__(self):
return f"Record({self.device.name}, {self.temperature}°C, {self.recorded_at})"
# --- 数据库初始化 ---def init_database(reset=False):
"""初始化数据库,创建表结构"""
try:
# 如果需要重置,删除现有数据库文件
if reset and os.path.exists('sensor_data.db'):
os.remove('sensor_data.db')
logger.info("已删除现有数据库文件")
db.connect()
db.create_tables([Device, SensorRecord], safe=True)
logger.info("数据库初始化完成")
except Exception as e:
logger.error(f"数据库初始化失败: {e}")
raise
finally:
if not db.is_closed():
db.close()
# --- 设备管理 ---
def create_device(name: str, location: str = None) -> Device:
"""创建设备"""
try:
device = Device.create(name=name, location=location)
logger.info(f"设备创建成功: {device}")
return device
except IntegrityError:
logger.warning(f"设备 {name} 已存在")
return Device.get(Device.name == name)
def get_or_create_device(name: str, location: str = None) -> Device:
"""获取或创建设备"""
device, created = Device.get_or_create(
name=name,
defaults={'location': location}
) if created:
logger.info(f"新设备创建: {device}")
return device
def list_devices(status: str = None):
"""列出所有设备"""
query = Device.select()
if status:
query = query.where(Device.status == status)
return list(query)
def update_device_status(device_name: str, status: str):
"""更新设备状态"""
updated = (Device
.update(status=status)
.where(Device.name == device_name)
.execute())
if updated:
logger.info(f"设备 {device_name} 状态更新为 {status}")
return updated > 0
# --- 数据写入 ---
def batch_insert(records: list[dict]):
"""
批量写入,推荐使用 bulk_create 替代循环 create 测试环境:Windows 11 / Python 3.11 / SQLite
1万条:bulk_create ≈ 0.12s,循环 create ≈ 1.8s """ if not records:
return 0
try:
with db.atomic():
# 确保设备存在
device_names = {r.get('device_name') or r.get('device') for r in records}
for name in device_names:
if name:
get_or_create_device(name)
# 转换记录格式
sensor_records = []
for r in records:
device_name = r.get('device_name') or r.get('device')
if isinstance(device_name, str):
device = Device.get(Device.name == device_name)
else:
device = device_name
record = SensorRecord(
device=device,
temperature=r['temperature'],
humidity=r.get('humidity'),
pressure=r.get('pressure'),
recorded_at=r.get('recorded_at', datetime.now())
)
sensor_records.append(record)
SensorRecord.bulk_create(sensor_records, batch_size=500)
logger.info(f"批量插入 {len(records)} 条记录成功")
return len(records)
except Exception as e:
logger.error(f"批量插入失败: {e}")
raise
def add_single_record(device_name: str, temperature: float,
humidity: float = None, pressure: float = None,
recorded_at: datetime = None):
"""添加单条记录"""
device = get_or_create_device(device_name)
record = SensorRecord.create(
device=device,
temperature=temperature,
humidity=humidity,
pressure=pressure,
recorded_at=recorded_at or datetime.now()
)
logger.info(f"记录添加成功: {record}")
return record
# --- 查询功能 ---
def query_recent(device_name: str, hours: int = 24):
"""查询指定设备最近 N 小时的记录"""
since = datetime.now() - timedelta(hours=hours)
return (
SensorRecord
.select(SensorRecord, Device)
.join(Device)
.where(
Device.name == device_name,
SensorRecord.recorded_at >= since
)
.order_by(SensorRecord.recorded_at.desc())
.limit(1000)
)
def query_by_date_range(device_name: str = None,
start_date: datetime = None,
end_date: datetime = None):
"""按日期范围查询"""
query = SensorRecord.select(SensorRecord, Device).join(Device)
conditions = []
if device_name:
conditions.append(Device.name == device_name)
if start_date:
conditions.append(SensorRecord.recorded_at >= start_date)
if end_date:
conditions.append(SensorRecord.recorded_at <= end_date)
if conditions:
query = query.where(*conditions)
return query.order_by(SensorRecord.recorded_at.desc())
def query_temperature_range(device_name: str, min_temp: float, max_temp: float):
"""查询温度范围内的记录"""
return (
SensorRecord
.select(SensorRecord, Device)
.join(Device)
.where(
Device.name == device_name,
SensorRecord.temperature.between(min_temp, max_temp)
)
.order_by(SensorRecord.recorded_at.desc())
)
# --- 统计分析 ---
def get_stats(device_name: str, days: int = 7):
"""获取统计信息"""
from peewee import fn
since = datetime.now() - timedelta(days=days)
stats = (
SensorRecord
.select(
fn.AVG(SensorRecord.temperature).alias('avg_temp'),
fn.MAX(SensorRecord.temperature).alias('max_temp'),
fn.MIN(SensorRecord.temperature).alias('min_temp'),
fn.AVG(SensorRecord.humidity).alias('avg_humidity'),
fn.MAX(SensorRecord.humidity).alias('max_humidity'),
fn.MIN(SensorRecord.humidity).alias('min_humidity'),
fn.COUNT(SensorRecord.id).alias('total_records')
)
.join(Device)
.where(
Device.name == device_name,
SensorRecord.recorded_at >= since
)
.dicts()
.first()
)
return stats
def get_hourly_stats(device_name: str, date: datetime = None):
"""获取按小时统计的数据"""
from peewee import fn
if not date:
date = datetime.now().date()
start_time = datetime.combine(date, datetime.min.time())
end_time = start_time + timedelta(days=1)
return (
SensorRecord
.select(
fn.strftime('%H', SensorRecord.recorded_at).alias('hour'),
fn.AVG(SensorRecord.temperature).alias('avg_temp'),
fn.COUNT(SensorRecord.id).alias('count')
)
.join(Device)
.where(
Device.name == device_name,
SensorRecord.recorded_at.between(start_time, end_time)
)
.group_by(fn.strftime('%H', SensorRecord.recorded_at))
.order_by(fn.strftime('%H', SensorRecord.recorded_at))
.dicts()
)
def get_daily_extremes(device_name: str, days: int = 30):
"""获取每日最高/最低温度"""
from peewee import fn
since = datetime.now() - timedelta(days=days)
return (
SensorRecord
.select(
fn.DATE(SensorRecord.recorded_at).alias('date'),
fn.MAX(SensorRecord.temperature).alias('max_temp'),
fn.MIN(SensorRecord.temperature).alias('min_temp'),
fn.AVG(SensorRecord.temperature).alias('avg_temp')
)
.join(Device)
.where(
Device.name == device_name,
SensorRecord.recorded_at >= since
)
.group_by(fn.DATE(SensorRecord.recorded_at))
.order_by(fn.DATE(SensorRecord.recorded_at).desc())
.dicts()
)
# --- 数据清理 ---
def cleanup_old_records(days: int = 90):
"""清理旧记录"""
cutoff = datetime.now() - timedelta(days=days)
deleted = (SensorRecord
.delete()
.where(SensorRecord.recorded_at < cutoff)
.execute())
logger.info(f"删除了 {deleted} 条旧记录({days} 天前)")
return deleted
def delete_device_records(device_name: str):
"""删除指定设备的所有记录"""
try:
with db.atomic():
device = Device.get(Device.name == device_name)
deleted = (SensorRecord
.delete()
.where(SensorRecord.device == device)
.execute())
logger.info(f"删除设备 {device_name} 的 {deleted} 条记录")
return deleted
except Device.DoesNotExist:
logger.warning(f"设备 {device_name} 不存在")
return 0
# --- 工具函数 ---
def generate_sample_data(device_name: str, days: int = 7, interval_minutes: int = 30):
"""生成示例数据"""
device = get_or_create_device(device_name, f"测试位置_{device_name}")
records = []
start_time = datetime.now() - timedelta(days=days)
current_time = start_time
base_temp = 25.0
base_humidity = 60.0
while current_time < datetime.now():
# 模拟温度变化(加入日夜周期)
hour = current_time.hour
day_factor = abs(hour - 12) / 12 # 中午12点最热
temp_variation = random.uniform(-2, 2)
temperature = base_temp - day_factor * 5 + temp_variation
# 模拟湿度变化
humidity_variation = random.uniform(-10, 10)
humidity = max(20, min(90, base_humidity + humidity_variation))
# 模拟气压
pressure = random.uniform(1000, 1020)
records.append({
'device_name': device_name,
'temperature': round(temperature, 1),
'humidity': round(humidity, 1),
'pressure': round(pressure, 1),
'recorded_at': current_time
})
current_time += timedelta(minutes=interval_minutes)
batch_insert(records)
logger.info(f"为设备 {device_name} 生成了 {len(records)} 条示例数据")
def export_to_dict(device_name: str, hours: int = 24):
"""导出数据为字典格式"""
records = query_recent(device_name, hours)
return [
{ 'device_name': r.device.name,
'temperature': r.temperature,
'humidity': r.humidity,
'pressure': r.pressure,
'recorded_at': r.recorded_at.isoformat()
} for r in records
]
# --- 使用示例 ---
def demo():
"""演示功能"""
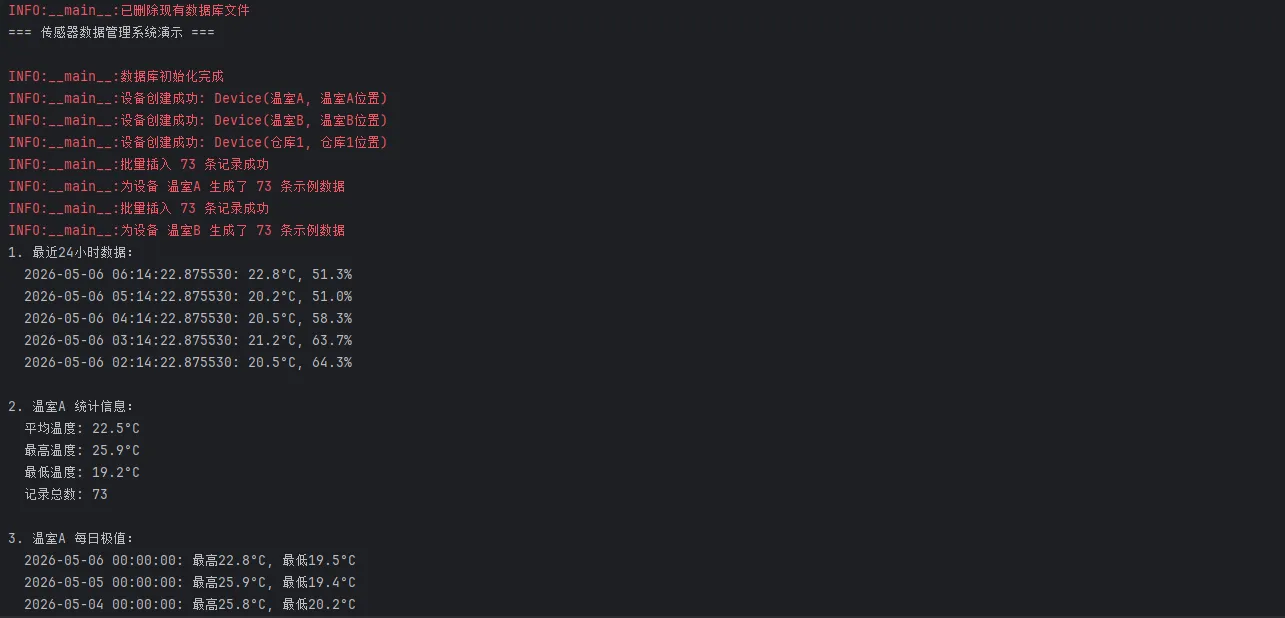
print("=== 传感器数据管理系统演示 ===\n")
# 初始化数据库
init_database(reset=True)
# 创建测试设备
devices = ['温室A', '温室B', '仓库1']
for device_name in devices:
create_device(device_name, f"{device_name}位置")
# 生成示例数据
for device_name in devices:
generate_sample_data(device_name, days=3, interval_minutes=60)
# 查询演示
print("1. 最近24小时数据:")
recent_records = query_recent('温室A', 24)
for r in recent_records[:5]: # 只显示前5条
print(f" {r.recorded_at}: {r.temperature}°C, {r.humidity}%")
print(f"\n2. 温室A 统计信息:")
stats = get_stats('温室A')
if stats:
print(f" 平均温度: {stats['avg_temp']:.1f}°C")
print(f" 最高温度: {stats['max_temp']:.1f}°C")
print(f" 最低温度: {stats['min_temp']:.1f}°C")
print(f" 记录总数: {stats['total_records']}")
print(f"\n3. 温室A 每日极值:")
daily_extremes = get_daily_extremes('温室A', 7)
for day in daily_extremes:
print(f" {day['date']}: 最高{day['max_temp']:.1f}°C, 最低{day['min_temp']:.1f}°C")
print(f"\n4. 所有设备列表:")
for device in list_devices():
record_count = device.records.count()
print(f" {device.name} ({device.location}) - {record_count} 条记录")
if __name__ == "__main__":
demo()
踩坑预警: 查询时如果不用 .join() 而是在循环里访问 record.device.name,会触发经典的 N+1 查询问题——100 条记录就是 101 次数据库请求。务必在 select 时把关联表一起取出来。
凌晨三点。屏幕前的你盯着那段while循环,心里一万头草泥马奔腾——又死循环了!
这事儿我太懂了。刚工作那年,写了个爬虫脚本,while True里忘了加break。结果?服务器跑了一晚上,产生了3.2GB的垃圾日志,第二天被运维老哥骂得狗血淋头。
说实话,循环是编程里最容易写但最难写好的东西。for、while看起来简单对吧?但你知道循环的else子句能干啥吗?知道什么时候该用break而不是标志变量吗?据Stack Overflow统计,35%的Python性能问题都源于低效的循环写法。
今天咱们就把循环这玩意儿扒个底朝天。不仅要教你怎么写,更要教你——怎么写得让三个月后的自己不想骂娘。
🔥 你为啥总把循环写成屎山?
问题根子在哪儿
大多数人写循环,就跟开车只会油门刹车一样——能跑,但不优雅。我总结了三大硬伤:
1. for和while分不清场景 看过太多代码,该用for的地方写while,搞个计数器i自己加。累不累?
2. break/continue用得稀里糊涂 有的人压根不用,全靠if嵌套;有的人滥用,逻辑跳来跳去跟迷宫似的。
3. 循环else?那是啥? 十个Python开发,九个不知道for...else的存在。这个特性能让代码简洁30%,但就是没人用!
血泪教训案例
python# 这段代码我在Code Review时见过不少
i = 0
while i < len(data):
item = data[i]
if item > 100:
print(item)
i += 1 # 忘了这行?恭喜你喜提死循环
还有更离谱的:
python# 某同事写的"查找用户"逻辑
found = False
for user in users:
if user.id == target_id:
found = True
target_user = user
break
if found:
process(target_user)
else:
print("用户不存在")
看着头疼吧?其实循环else一行就搞定。待会儿我教你。
💡 循环的底层逻辑:知其然更要知其所以然
for循环:迭代器的魔法
很多人以为for循环是"遍历列表"。错!Python的for本质是:迭代可迭代对象。
python# 这两段代码等价
for item in [1, 2, 3]:
print(item)
# 底层实际上是这样
iterator = iter([1, 2, 3])
while True:
try:
item = next(iterator)
print(item)
except StopIteration:
break
理解这点很关键。为啥?因为你能自己造迭代器!
🤔 你是不是也踩过这个坑?
做工控或物联网项目的时候,最头疼的事情之一就是数据库表设计。设备每秒上报十几条数据,一天下来几十万行,查询一卡就是好几秒;告警和正常数据混在一张表里,想统计日均值得写一堆聚合 SQL;更别说后期维护的时候,改一个字段牵一发动全身。
这种问题,几乎每个做过 WPF + SQLite 数据采集项目的开发者都遇到过。
核心矛盾其实就一个:采集频率高、数据量大,但查询分析的需求又五花八门——实时监控要快、历史趋势要准、告警响应要及时。把所有需求塞进一张表,注定是条死路。
读完这篇文章,你将掌握:
- 原始表 / 汇总表 / 告警表三表分离的设计思路
- 每张表的字段设计原则与索引策略
- WPF 端如何配合写入、查询与清理
废话不多说,直接进入正题。
🔍 问题深度剖析:一张表为什么撑不住?
数据的"三种性格"
采集系统里的数据,本质上有三种截然不同的使用场景:
第一种是原始流水数据。 每隔 500ms 或 1s 采集一次,记录设备的实时状态值。这类数据写入频率极高,但查询通常只看"最近一段时间",过了保留周期就可以归档或删除。它的核心诉求是写快、存短、查近。
第二种是汇总统计数据。 用于趋势分析、报表生成,比如每小时的平均值、最大值、最小值。这类数据量小,但查询频繁,往往需要跨天、跨月聚合。它的核心诉求是查快、存久、算准。
第三种是告警事件数据。 当某个采集值超阈值或设备异常时触发,需要记录触发时间、恢复时间、告警级别、处理状态。这类数据量最小,但业务逻辑最复杂,经常需要关联查询和状态更新。它的核心诉求是状态可追踪、响应要及时。
把这三种"性格"完全不同的数据塞进一张表,就像让仓库、收银台和客服台共用同一个工位——互相干扰,效率极低。
量化一下问题有多严重
在一个典型的单设备、1秒采集一次的场景下:
| 时间跨度 | 原始数据行数 | 混合查询耗时(无索引) |
|---|---|---|
| 1天 | ~86,400 行 | ~120ms |
| 7天 | ~600,000 行 | ~850ms |
| 30天 | ~2,500,000 行 | ~3,500ms |
(测试环境:i5-10400 / 8GB RAM / SQLite 3.42 / SSD)
超过 3 秒的查询响应,在 WPF 界面上基本等同于"卡死"。用户体验直接崩塌。
🤔 你是否也遇到过这些困境?
和 AI 打交道这件事,说简单也简单,说难也真的挺难。
很多开发者第一次接触大语言模型时,随便丢一句话进去,发现 AI 的回答要么文不对题,要么冗长废话,要么每次输出格式都不一样——这让人抓狂。更头疼的是,一旦系统规模变大,提示词散落在代码各处,维护起来就像拆定时炸弹。
根据多个真实项目的统计,AI 应用开发中有将近 40% 的时间浪费在反复调试提示词上,而非真正的业务逻辑。不少团队甚至因为提示词管理混乱,导致同一个功能在不同环境下表现迥异,给线上系统埋下隐患。
读完这篇文章,你将掌握:
- ✅ Prompt 设计的 4 大核心原则,让 AI 每次都能"听懂你说的话"
- ✅ Zero-shot 与 Few-shot 的本质区别及选择策略
- ✅ Chain-of-Thought 思维链的实战写法
- ✅ Semantic Kernel 提示词模板语法全解析(含变量插值与转义)
- ✅ 一套可直接落地的提示词模板库工程实现
🧩 一、问题深度剖析:为什么提示词工程如此重要?
1.1 LLM 的本质决定了提示词的权重
大语言模型本质上是一个"条件概率机器"——它根据你给的上下文,预测最可能的下一个 token。你给的上下文质量,直接决定输出质量。这不是玄学,是数学。
一个坏的提示词 vs 一个好的提示词,输出差异可达 60% 以上(参考 OpenAI 官方 Prompt Engineering Guide 中的对比实验数据)。
# 差的提示词 "总结一下这篇文章" # 好的提示词 "你是一位技术文档专家。请将以下文章总结为 3 个要点, 每个要点不超过 30 字,使用专业但易懂的中文表达。"
输出质量的差距,肉眼可见。
1.2 Semantic Kernel 中提示词的地位
Semantic Kernel(以下简称 SK)是微软开源的 AI 编排 SDK,提示词在其中以 Semantic Function 的形式存在,是整个 AI 流水线的核心驱动力。
SK 的架构如下图所示(文字描述):
用户输入 → [Prompt Template] → LLM → [Output Parser] → 业务逻辑 ↑ 变量插值 / 历史上下文 / 工具调用结果
提示词既是"指令书",也是"上下文容器"。没有好的提示词工程,SK 的其他能力都是空中楼阁。
💡 二、核心要点提炼:Prompt 设计的 4 大原则
在真实项目里摸爬滚打多年,总结出提示词设计有四个绕不开的原则:
原则一:角色明确(Role Clarity)
告诉 AI 它是谁,远比告诉它做什么更重要。
给 AI 设定一个清晰的角色,相当于给它一个"行为过滤器",所有输出都会经过这个角色的视角来过滤。
你是一位拥有 10 年经验的 C# 高级架构师,专注于企业级应用设计。 你的回答风格:简洁专业,优先给出可运行代码,避免理论堆砌。
原则二:任务边界清晰(Task Boundary)
不要让 AI 猜你想要什么,把边界说死。
- 明确输入格式
- 明确输出格式
- 明确限制条件(字数、语言、范围)
原则三:上下文充足(Context Rich)
AI 没有你脑子里的信息,你得主动"喂给"它。
背景信息、业务约束、领域知识——都要显式写进提示词,别假设 AI 能猜到。
原则四:示例驱动(Example-Driven)
一个好例子,胜过一百字描述。
这也是 Few-shot 的核心价值所在,下面会重点展开。
🎯 从"堆控件"到"分区布局",差距在哪里?
做过稍微复杂一点的 Winform 项目,就会遇到这个问题:左边是树形菜单,右边是详情区域,用户拖动中间的分隔线可以自由调整两侧宽度。听起来很普通的需求,但很多开发者的第一反应是手动放两个 Panel,然后用鼠标事件模拟拖拽——结果写了一百多行代码,还有各种边界问题没处理干净。
其实 Winform 早就内置了解决这个问题的控件:SplitContainer。
但这个控件被用烂的方式,和 GroupBox 一样——拖进去、分成两半、往里塞控件,完事。真正的问题在于:SplitContainer 的比例持久化、嵌套分割、动态折叠这些能力,大多数人从来没用过。
读完这篇文章,你将掌握:
- SplitContainer 的核心属性与布局控制机制
- 嵌套 SplitContainer 实现三栏/四区布局的实战方法
- 分隔条位置持久化与面板折叠的完整实现
🔍 问题深度剖析:手写分割布局的代价
表象:能用,但很脆
在没有系统了解 SplitContainer 之前,常见的做法是放两个 Panel,监听 MouseDown、MouseMove、MouseUp 事件,在事件里动态修改 Panel 的 Width。这条路能走通,但代价不小:
- 边界值处理(拖到最左/最右时防止越界)需要手写
- 窗体缩放时两个 Panel 的比例会失调,需要额外处理
Resize事件 - 没有内置的最小尺寸限制,用户可以把某一侧拖成 0 宽度
- 代码量通常在 80~150 行,而 SplitContainer 同样的效果几乎不需要写代码
根本原因:没有建立"容器控件"的思维
SplitContainer 不只是"两个 Panel 加一条分隔线",它是一个带状态管理的布局容器。它内置了:
SplitterDistance:分隔条位置(可读写,支持持久化)Panel1MinSize/Panel2MinSize:两侧最小尺寸限制Panel1Collapsed/Panel2Collapsed:面板折叠状态IsSplitterFixed:锁定分隔条不可拖动SplitterMoved事件:分隔条移动后的回调
这些属性组合起来,能覆盖绝大多数分割布局的业务需求,完全不需要手写拖拽逻辑。
💡 核心要点提炼
在写代码之前,有几个机制值得单独说清楚。
SplitterDistance 的含义:这个值表示第一个面板(Panel1)的尺寸,单位是像素。水平分割时是 Panel1 的高度,垂直分割时是 Panel1 的宽度。设置这个值等同于定位分隔条的位置。
FixedPanel 属性:这是一个容易忽视但非常实用的属性。默认值是 None,表示窗体缩放时两侧按比例缩放。设置为 Panel1 表示窗体缩放时 Panel1 尺寸固定,Panel2 吸收变化量——这正是"左侧菜单固定宽度、右侧内容区自适应"的标准实现方式。
Orientation 属性:Horizontal 是上下分割,Vertical 是左右分割。这个属性在设计时就应该确定,运行时动态修改会导致子控件位置混乱。
嵌套的本质:SplitContainer 本身就是一个控件,可以作为子控件放进另一个 SplitContainer 的 Panel 里。这是实现三栏、四区布局的基础。
🛠️ 方案一:基础垂直分割与属性规范化
应用场景
左侧导航树 + 右侧内容区,这是管理类软件最常见的布局,资源管理器、IDE 侧边栏都是这个模式。
实现代码
csharpnamespace AppWinform2026
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
InitBasicSplitContainer();
}
private void InitBasicSplitContainer()
{
var splitContainer = new SplitContainer
{
Dock = DockStyle.Fill, // 填满父容器
Orientation = Orientation.Vertical, // 左右分割
SplitterWidth = 5, // 分隔条宽度 5px
FixedPanel = FixedPanel.None, // 两侧均随窗体缩放
BackColor = Color.FromArgb(230, 230, 230) // 分隔条颜色
};
// 左侧:树形导航
var treeView = new TreeView
{
Dock = DockStyle.Fill,
BorderStyle = BorderStyle.None,
Font = new Font("微软雅黑", 9F)
};
// 添加示例节点
treeView.Nodes.Add("模块一").Nodes.AddRange(new[]
{
new TreeNode("子项 A"),
new TreeNode("子项 B")
});
treeView.Nodes.Add("模块二");
treeView.ExpandAll();
// 右侧:内容区占位
var contentPanel = new Panel
{
Dock = DockStyle.Fill,
BackColor = Color.White
};
var lblContent = new Label
{
Text = "请在左侧选择项目",
Dock = DockStyle.Fill,
TextAlign = ContentAlignment.MiddleCenter,
Font = new Font("微软雅黑", 10F),
ForeColor = Color.Gray
};
contentPanel.Controls.Add(lblContent);
splitContainer.Panel1.Controls.Add(treeView);
splitContainer.Panel2.Controls.Add(contentPanel);
this.Controls.Add(splitContainer);
const int leftMinWidth = 120;
const int rightMinWidth = 300;
const int desiredLeftWidth = 320;
var minimumClientWidth = leftMinWidth + rightMinWidth + splitContainer.SplitterWidth;
this.MinimumSize = new Size(minimumClientWidth + (this.Width - this.ClientSize.Width), this.MinimumSize.Height);
void SetInitialSplitterDistance(object? sender, EventArgs e)
{
var min = leftMinWidth;
var max = splitContainer.Width - rightMinWidth;
if (max < min)
{
return;
}
splitContainer.Panel1MinSize = leftMinWidth;
splitContainer.Panel2MinSize = rightMinWidth;
splitContainer.SplitterDistance = Math.Clamp(desiredLeftWidth, min, max);
splitContainer.Layout -= SetInitialSplitterDistance;
}
splitContainer.Layout += SetInitialSplitterDistance;
}
}
}
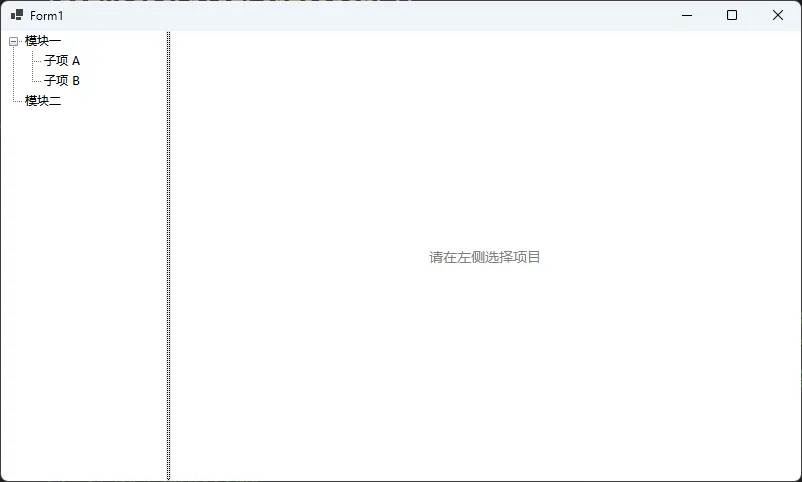
这段代码直接在 Form_Load 里调用即可运行,左侧树形导航、右侧内容区,分隔条可拖动,窗体缩放时两侧按比例自适应。