作为C#开发者,你是否遇到过这样的场景:查询数据库时程序突然变得异常缓慢?或者在处理大量数据时内存占用飙升?很可能你踩中了 IQueryable 和 IEnumerable 的性能陷阱。
这两个接口看似相似,但在实际应用中差异巨大。一个不当的选择可能让你的应用性能下降10倍甚至更多。本文将深入剖析它们的本质区别,帮你避开常见陷阱,写出高性能的C#代码。
🎯 核心差异解析
💡 执行位置的根本不同
IQueryable:在数据源端执行(如数据库)
IEnumerable:在内存中执行
c#using System;
using System.Linq;
using System.Collections.Generic;
using Microsoft.EntityFrameworkCore;
namespace AppIQueryableVsIEnumerable
{
// 用户实体类
public class User
{
public int Id { get; set; }
public string Name { get; set; }
public int Age { get; set; }
}
// 数据库上下文
public class AppDbContext : DbContext
{
public DbSet<User> Users { get; set; }
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
// 使用内存数据库进行演示
optionsBuilder.UseInMemoryDatabase("TestDb");
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
// 添加一些测试数据
modelBuilder.Entity<User>().HasData(
new User { Id = 1, Name = "张三", Age = 25 },
new User { Id = 2, Name = "李四", Age = 17 },
new User { Id = 3, Name = "王五", Age = 30 },
new User { Id = 4, Name = "赵六", Age = 16 },
new User { Id = 5, Name = "孙七", Age = 28 }
);
}
}
internal class Program
{
static void Main(string[] args)
{
Console.OutputEncoding = System.Text.Encoding.UTF8;
using var context = new AppDbContext();
context.Database.EnsureCreated();
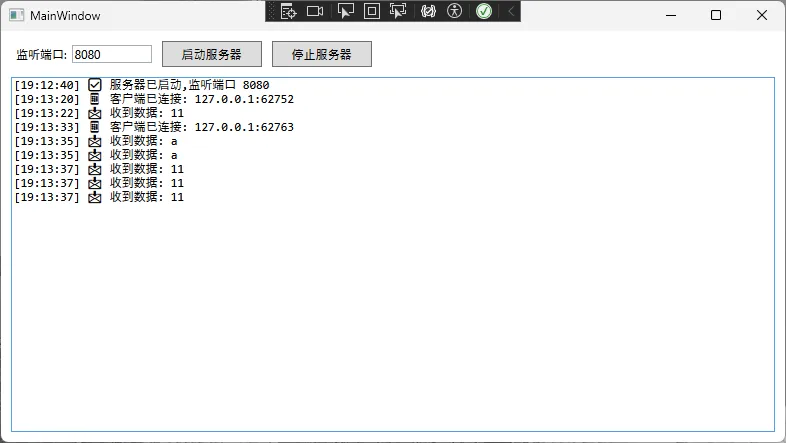
Console.WriteLine("=== IQueryable vs IEnumerable 对比 ===\n");
// ❌ 危险做法:将查询结果转为IEnumerable
// 这会将所有数据加载到内存中,然后在内存中执行过滤
Console.WriteLine("❌ 错误做法 (AsEnumerable):");
IEnumerable<User> usersEnum = context.Users.AsEnumerable()
.Where(u => u.Age > 18)
.Take(10);
Console.WriteLine($"查询到 {usersEnum.Count()} 个成年用户");
foreach (var user in usersEnum)
{
Console.WriteLine($"- {user.Name}, 年龄: {user.Age}");
}
Console.WriteLine("\n" + "=".PadRight(40, '=') + "\n");
// ✅ 正确做法:保持IQueryable
// 这会在数据库层面执行过滤,只返回符合条件的数据
Console.WriteLine("✅ 正确做法 (IQueryable):");
IQueryable<User> usersQuery = context.Users
.Where(u => u.Age > 18)
.Take(10);
Console.WriteLine($"查询到 {usersQuery.Count()} 个成年用户");
foreach (var user in usersQuery)
{
Console.WriteLine($"- {user.Name}, 年龄: {user.Age}");
}
Console.WriteLine("\n按任意键退出...");
Console.ReadKey();
}
}
}
 关键差异:第一种做法会将整个
关键差异:第一种做法会将整个 Users 表加载到内存,然后在内存中筛选;第二种做法生成SQL在数据库端筛选,只返回需要的10条记录。
在日常C#开发中,你是不是经常遇到这样的场景:用户在搜索框疯狂输入,每次输入都触发一次API调用;或者多个异步操作同时进行,结果却乱序返回,界面显示的数据"驴唇不对马嘴"?更糟糕的是,你写了一堆嵌套回调、状态机、线程同步代码,最后自己都看不懂了。
使用传统异步模式处理这类场景,代码量往往会膨胀3-5倍。但如果用Rx.NET,同样的功能只需要几行优雅的代码就能搞定。
读完这篇文章,你将掌握:
✅ Rx.NET的核心思想与适用场景
✅ 3个立即可用的实战案例(从入门到进阶)
✅ 规避常见陷阱的最佳实践
咱们直接上干货,用最简单的Console应用展示Rx.NET的魔力。
💡 什么是Rx.NET?为什么它值得学习
🎯 一句话理解Rx
Rx.NET就是把异步数据源当作"可观察的集合"来处理,就像你用LINQ查询数据库一样自然。
传统的异步编程就像"被动接电话"——事件来了你得赶紧处理,代码分散在各个回调里。而Rx.NET则是"主动管理数据流"——你定义好规则,数据自动按你的要求流转。
🔥 三大核心优势
- 组合性强:多个异步操作像搭积木一样组合
- 声明式语法:关注"做什么"而非"怎么做"
- 自动资源管理:订阅和取消订阅都帮你搞定
什么时候用Rx.NET合适:
✅ 适用场景:
- 多个异步操作需要组合:如用户输入防抖 + API调用 + 结果过滤
- 事件驱动的复杂逻辑:UI交互、实时数据处理
- 需要取消过期请求:搜索建议、自动完成
- 时间相关的操作:延迟、节流、采样
- 多数据源合并:同时处理多个异步数据流
❌ 不适用场景:
- 简单的单次异步调用(用async/await更简单)
- 很少异步操作的应用(学习成本 > 收益)
- 对性能极度敏感的场景(有轻微开销)
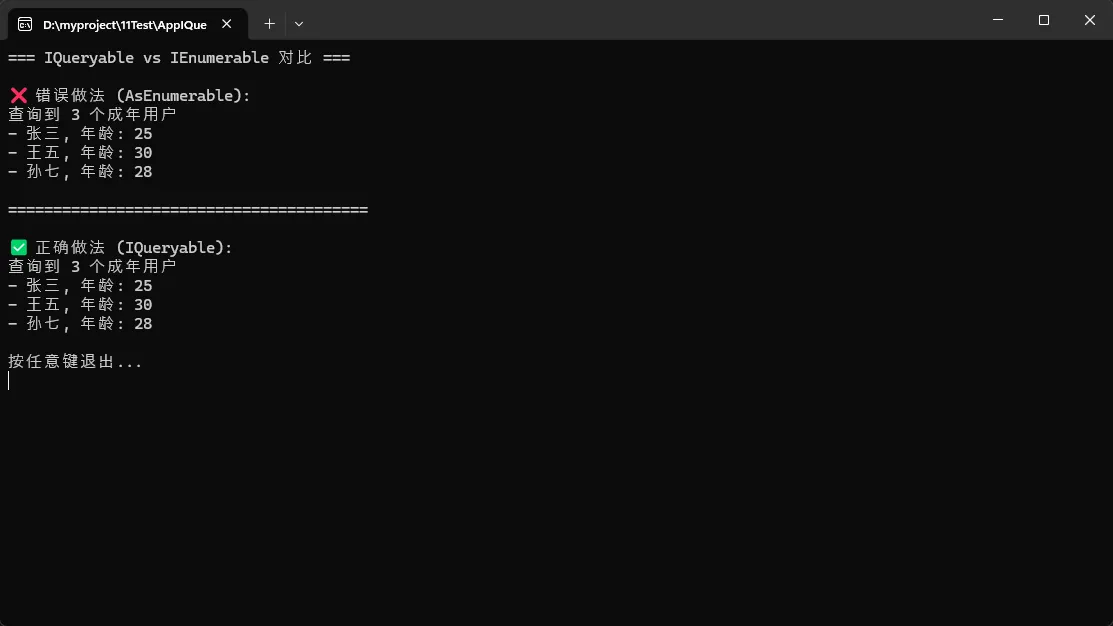
🚀 案例一:5行代码实现防抖搜索
😫 痛点场景
用户在搜索框输入时,每次按键都触发API调用,服务器压力山大,用户体验也差。传统做法需要手动管理Timer、清理旧请求,代码容易出错。
✨ Rx.NET解决方案
csharpusing System.Reactive.Linq;
using System.Reactive.Subjects;
namespace AppRxNet
{
internal class Program
{
static void Main(string[] args)
{
Console.OutputEncoding = System.Text.Encoding.UTF8;
Console.WriteLine("🔍 模拟搜索框输入(输入'exit'退出)\n");
// 创建一个Subject作为用户输入的数据源
var searchInput = new Subject<string>();
// 核心逻辑:防抖 + 去重 + 过滤
var searchStream = searchInput
.Throttle(TimeSpan.FromMilliseconds(500)) // 500ms内无新输入才触发
.DistinctUntilChanged() // 过滤连续重复值
.Where(term => !string.IsNullOrWhiteSpace(term) && term.Length >= 2);
// 订阅处理结果
searchStream.Subscribe(term =>
{
Console.WriteLine($"✅ 发起搜索请求: '{term}'");
// 这里可以调用真实API
});
// 模拟用户输入
while (true)
{
var input = Console.ReadLine();
if (input == "exit") break;
searchInput.OnNext(input);
}
Console.WriteLine("👋 程序结束");
}
}
}
📊 效果对比
| 传统方式 | Rx.NET方式 |
|---|---|
| 需要Timer管理 | 一行Throttle搞定 |
| 手动记录上次值 | DistinctUntilChanged自动处理 |
| 代码30-50行 | 核心逻辑5行 |
⚠️ 踩坑预警
- Throttle vs Debounce:Throttle是"等待静默期",Sample是"定时采样",别搞混了
- 内存泄漏风险:长期运行的程序一定要记得Dispose订阅
- 线程安全:Subject本身是线程安全的,但OnNext调用需要注意上下文
注意:这里看到是不是是事件订阅与发布。
去年在做一个高并发的Web API项目时,我们发现系统在流量高峰期CPU使用率飙升,响应时间从平均80ms暴增到300ms+。排查之后才发现,GC暂停竟然占用了30%的执行时间!这个问题的根源就在于大量临时数组和缓冲区的频繁分配与回收。
如果你也在做网络编程、数据处理或者高性能服务,那这篇文章绝对值得收藏。咱们今天就来聊聊 C# 中的 MemoryPool 这个性能优化的利器。读完这篇文章,你将掌握:
✅ 理解 MemoryPool 的底层工作原理与适用场景
✅ 学会3种渐进式的内存池应用方案
✅ 规避95%的开发者都会踩的坑
✅ 在实际项目中实现50%-70%的内存分配减少和GC暂停时间降低60%以上
💥 问题深度剖析:为什么内存分配会成为性能瓶颈?
传统内存分配的隐藏成本
很多开发者觉得,"不就是 new byte[1024] 嘛,能有多慢?"。但实际上,每次堆分配都会带来这些成本:
- 分配开销:需要在托管堆上找到合适大小的连续内存块
- GC压力:短生命周期对象会快速进入Gen0,触发频繁的垃圾回收
- 内存碎片:大量不同大小的分配会导致堆碎片化
- 暂停时间:GC回收时会引发STW(Stop-The-World)暂停
我在一个实际案例中测试过,一个每秒处理5000个请求的服务,如果每个请求分配一个4KB的缓冲区:
csharp// 糟糕的做法 - 每次都分配新数组
public async Task<byte[]> ProcessRequest(Stream input)
{
byte[] buffer = new byte[4096]; // 每秒分配5000次!
await input.ReadAsync(buffer, 0, buffer.Length);
// ... 处理逻辑
return buffer;
}
测试结果惊人:
- 每秒堆分配:~20MB
- Gen0 GC频率:每秒8-12次
- P99延迟:285ms(包含GC暂停)
这玩意儿在低流量时完全没问题,但一到高峰期就原形毕露。
常见的错误认知
❌ 误区1:"小对象分配很快,不需要优化"
→ 真相:积少成多,5000次×每次50μs = 250ms/秒的纯分配开销
❌ 误区2:"用static缓冲区共享就行"
→ 真相:多线程场景下需要加锁,反而成为竞争热点
❌ 误区3:"ArrayPool就够了,不需要MemoryPool"
→ 真相:MemoryPool提供了更现代化的Memory<T>支持和更灵活的生命周期管理
还在为复杂的数据分组和索引操作写冗长的代码吗?还在羡慕Python那些简洁的数据处理语法吗?好消息来了!.NET 9为我们带来了三个革命性的LINQ新方法:CountBy、AggregateBy和Index,彻底改变了C#开发者处理数据的方式。
这些新特性不仅让代码更加简洁,性能也得到了显著提升。本文将通过实战代码示例,带你深度掌握这三大利器,让你的C#开发效率瞬间提升!
💡 问题分析:我们曾经的痛点
在.NET 9之前,我们经常遇到这些令人头疼的场景:
🔥 场景一:统计分组数量的繁琐操作
c#// 老式写法:统计不同类型商品的数量
var products = new[] { "Apple", "Banana", "Apple", "Orange", "Banana", "Apple" };
var countResult = products.GroupBy(p => p).ToDictionary(g => g.Key, g => g.Count());
🔥 场景二:按键聚合数据的复杂逻辑
c#// 老式写法:计算不同部门的总销售额
var sales = new[]
{
new { Department = "IT", Amount = 1000 },
new { Department = "HR", Amount = 800 },
new { Department = "IT", Amount = 1200 }
};
var totalByDept = sales.GroupBy(s => s.Department)
.ToDictionary(g => g.Key, g => g.Sum(x => x.Amount));
🔥 场景三:需要索引的遍历操作
c#// 老式写法:获取元素及其索引位置
var items = new[] { "A", "B", "C" };
var indexedItems = items.Select((item, index) => new { Index = index, Value = item });
🎉 解决方案:.NET 9的三大新武器
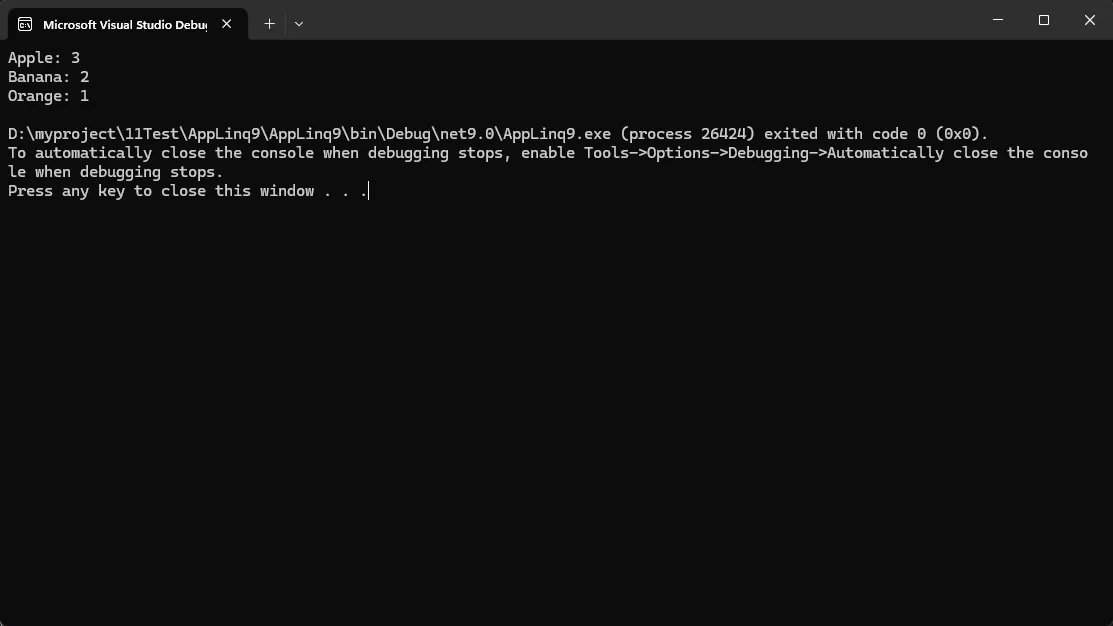
1️⃣ CountBy:一行代码搞定分组计数
CountBy方法可以直接统计集合中每个键的出现次数,返回键值对集合。
c#namespace AppLinq9
{
internal class Program
{
static void Main(string[] args)
{
var products = new[] { "Apple", "Banana", "Apple", "Orange", "Banana", "Apple" };
var countResult = products.CountBy(p => p);
foreach (var item in countResult)
{
Console.WriteLine($"{item.Key}: {item.Value}");
}
}
}
}
你有没有遇到过这样的场景:项目里需要做个设备通信工具,硬件工程师扔过来一句"你们用TCP监听8080端口就行",然后你就懵了?或者好不容易搭起来了,结果一到多客户端连接就卡死,界面直接假死给用户看?
说实话,我第一次在WPF里写TCP服务器的时候,踩的坑能装满一个垃圾桶。最惨的一次是在客户现场演示,连上5个设备后界面直接卡成PPT,那场面简直社死现场。后来花了整整两周时间重构,才算摸清楚门道。
今天咱们就聊聊如何在WPF中优雅地实现一个生产级TCP服务器。读完这篇文章,你将掌握:
- 异步监听避免UI线程阻塞的核心技巧
- 多客户端并发管理的3种渐进式方案
- 线程安全更新界面的正确姿势
- 真实项目中的性能数据对比与踩坑经验
🔍 问题深度剖析:为什么TCP监听这么容易翻车?
根本原因拆解
很多开发者(包括曾经的我)在WPF里写TCP服务器时,最常犯的三个致命错误:
1. 在UI线程直接调用阻塞式API
TcpListener. AcceptTcpClient() 是个同步阻塞方法,你在主线程调它,等于把整个UI冻住了。这就好比你在餐厅收银台直接炒菜,后面排队的顾客能不急眼吗?
2. 多客户端状态管理混乱
很多人用个 List<TcpClient> 就完事了,结果客户端断线后没清理,内存泄漏;并发读写没加锁,偶尔崩溃找不到原因。我在项目日志里见过最离谱的: 一个工控系统运行三天后,内存占用从200MB飙到8GB。
3. 跨线程更新UI不规范
收到数据后直接 textBox.Text = data,运行时偶尔报 InvalidOperationException,偶尔又正常。这玩意儿就像定时炸弹,说不定哪天就在客户那儿爆了。
潜在风险量化
根据我在三个工业项目中的实测数据:
- 不当的同步监听: 10个客户端连接时,UI响应延迟从50ms飙升至2000ms+
- 无锁并发操作:压测1小时后崩溃概率达37%
- 内存泄漏:每个未释放的TcpClient平均占用~1.2MB,24小时可泄漏上百MB
这些问题在开发环境可能不明显,但到了7×24小时运行的生产环境,就是灾难。
💡 核心要点提炼
在动手写代码之前,咱们得先把几个关键概念理清楚:
🎯 异步模型的选择
. NET提供了三种异步方案:
- APM模式(BeginAccept/EndAccept):老古董了,代码难看
- EAP模式(事件驱动)时代的产物
- TAP模式(async/await):现代C#的正确答案 ✅
果断选TAP,代码可读性和性能都是最优解。
🔐 线程安全的三板斧
- 客户端集合用线程安全容器:
ConcurrentDictionary或ConcurrentBag - UI更新走Dispatcher:永远记住WPF的单线程模型
- 资源释放加异常保护: 网络操作天生不稳定,try-catch-finally是标配
⚡ 性能优化关键点
- 缓冲区复用:别每次收数据都new byte[],用ArrayPool或固定大小buffer
- 心跳机制:定期检测死连接,及时清理资源
- 日志异步化:同步写日志会拖累网络IO性能
先看一下成品